- Page 1 and 2:
M E T H O D S I N M O L E C U L A R
- Page 3 and 4:
M E T H O D S I N M O L E C U L A R
- Page 5 and 6:
© 2006 Humana Press Inc. 999 River
- Page 7 and 8:
vi Preface comprehensive review of
- Page 9 and 10:
viii Contents 11 Detection of the F
- Page 11 and 12:
x Contributors D. GARY GILLILAND
- Page 14 and 15:
RNA and DNA From Leukocytes 1 1 Iso
- Page 16 and 17:
RNA and DNA From Leukocytes 3 mine
- Page 18 and 19:
RNA and DNA From Leukocytes 5 late
- Page 20 and 21:
RNA and DNA From Leukocytes 7 9. Us
- Page 22 and 23:
RNA and DNA From Leukocytes 9 16. C
- Page 24 and 25:
RNA and DNA From Leukocytes 11 3. I
- Page 26 and 27:
Cytogenetic and FISH Techniques 13
- Page 28 and 29:
Cytogenetic and FISH Techniques 15
- Page 30 and 31:
Cytogenetic and FISH Techniques 17
- Page 32 and 33:
Cytogenetic and FISH Techniques 19
- Page 34 and 35:
Cytogenetic and FISH Techniques 21
- Page 36 and 37:
Cytogenetic and FISH Techniques 23
- Page 38 and 39:
Cytogenetic and FISH Techniques 25
- Page 40 and 41:
Real-Time RT-PCR Strategies 27 3 Ov
- Page 42 and 43:
Real-Time RT-PCR Strategies 29
- Page 44 and 45:
Real-Time RT-PCR Strategies 31 cifi
- Page 46 and 47:
Real-Time RT-PCR Strategies 33 2.1.
- Page 48 and 49:
Real-Time RT-PCR Strategies 35 Fig.
- Page 50 and 51:
Real-Time RT-PCR Strategies 37 2.1.
- Page 52 and 53:
Real-Time RT-PCR Strategies 39 the
- Page 54 and 55:
Real-Time RT-PCR Strategies 41 Fig.
- Page 56 and 57:
Real-Time RT-PCR Strategies 43 duri
- Page 58 and 59:
MyiQ single color 400 nm 585 nm 96
- Page 60 and 61:
Real-Time RT-PCR Strategies 47 side
- Page 62 and 63:
Table 2 Real-Time Quantitative Poly
- Page 64 and 65:
Real-Time RT-PCR Strategies 51 AML-
- Page 66 and 67:
Real-Time RT-PCR Strategies 53 the
- Page 68 and 69:
Real-Time RT-PCR Strategies 55 plas
- Page 70 and 71:
Real-Time RT-PCR Strategies 57 betw
- Page 72 and 73:
Real-Time RT-PCR Strategies 59 Ct C
- Page 74 and 75:
Real-Time RT-PCR Strategies 61 Fig.
- Page 76 and 77:
Real-Time RT-PCR Strategies 63 asse
- Page 78 and 79:
Real-Time RT-PCR Strategies 65 21.
- Page 80 and 81:
Real-Time RT-PCR Strategies 67 50.
- Page 82 and 83:
Quantitative PCR for Monitoring CML
- Page 84 and 85:
Quantitative PCR for Monitoring CML
- Page 86 and 87:
Quantitative PCR for Monitoring CML
- Page 88 and 89:
Quantitative PCR for Monitoring CML
- Page 90 and 91:
Quantitative PCR for Monitoring CML
- Page 92 and 93:
Quantitative PCR for Monitoring CML
- Page 94 and 95:
Quantitative PCR for Monitoring CML
- Page 96 and 97:
Quantitative PCR for Monitoring CML
- Page 98 and 99:
Quantitative PCR for Monitoring CML
- Page 100 and 101:
Quantitative PCR for Monitoring CML
- Page 102 and 103:
Quantitative PCR for Monitoring CML
- Page 104 and 105:
Quantitative PCR for Monitoring CML
- Page 106 and 107:
Detection of BCR-ABL Mutations 93 5
- Page 108 and 109:
Detection of BCR-ABL Mutations 95 F
- Page 110 and 111:
Detection of BCR-ABL Mutations 97 2
- Page 112 and 113:
Detection of BCR-ABL Mutations 99 o
- Page 114 and 115:
Detection of BCR-ABL Mutations 101
- Page 116 and 117:
Detection of BCR-ABL Mutations 103
- Page 118 and 119:
Detection of BCR-ABL Mutations 105
- Page 120 and 121:
Deletion of Derivative Chromosome 9
- Page 122 and 123:
Deletion of Derivative Chromosome 9
- Page 124 and 125:
Deletion of Derivative Chromosome 9
- Page 126 and 127:
Deletion of Derivative Chromosome 9
- Page 128 and 129:
Diagnosis of PML-RARA-Positive APL
- Page 130 and 131:
Diagnosis of PML-RARA-Positive APL
- Page 132 and 133:
Diagnosis of PML-RARA-Positive APL
- Page 134 and 135:
Diagnosis of PML-RARA-Positive APL
- Page 136 and 137:
Diagnosis of PML-RARA-Positive APL
- Page 138 and 139:
Diagnosis of PML-RARA-Positive APL
- Page 140 and 141:
Duplexed QZyme RT-PCR for APL Analy
- Page 142 and 143:
Duplexed QZyme RT-PCR for APL Analy
- Page 144 and 145:
Duplexed QZyme RT-PCR for APL Analy
- Page 146 and 147:
Duplexed QZyme RT-PCR for APL Analy
- Page 148 and 149:
Duplexed QZyme RT-PCR for APL Analy
- Page 150 and 151:
Duplexed QZyme RT-PCR for APL Analy
- Page 152 and 153:
Duplexed QZyme RT-PCR for APL Analy
- Page 154 and 155:
Duplexed QZyme RT-PCR for APL Analy
- Page 156 and 157:
Duplexed QZyme RT-PCR for APL Analy
- Page 158 and 159:
Duplexed QZyme RT-PCR for APL Analy
- Page 160 and 161:
Duplexed QZyme RT-PCR for APL Analy
- Page 162 and 163:
Diagnosis of AML1-MTG8 (ETO)-Positi
- Page 164 and 165:
Diagnosis of AML1-MTG8 (ETO)-Positi
- Page 166 and 167:
Diagnosis of AML1-MTG8 (ETO)-Positi
- Page 168 and 169:
Diagnosis of AML1-MTG8 (ETO)-Positi
- Page 170 and 171:
Diagnosis of AML1-MTG8 (ETO)-Positi
- Page 172 and 173:
Diagnosis of AML1-MTG8 (ETO)-Positi
- Page 174 and 175:
Diagnosis of AML1-MTG8 (ETO)-Positi
- Page 176 and 177:
Diagnosis of CBFB-MYH11-Positive AM
- Page 178 and 179:
165 Table 1 Primers for CBFB-MYH11
- Page 180 and 181:
Diagnosis of CBFB-MYH11-Positive AM
- Page 182 and 183:
Diagnosis of CBFB-MYH11-Positive AM
- Page 184 and 185:
Diagnosis of CBFB-MYH11-Positive AM
- Page 186 and 187:
Diagnosis of CBFB-MYH11-Positive AM
- Page 188 and 189:
Diagnosis of CBFB-MYH11-Positive AM
- Page 190 and 191:
FIP1L1-PDGFRA in Hypereosinophilic
- Page 192 and 193:
FIP1L1-PDGFRA in Hypereosinophilic
- Page 194 and 195:
FIP1L1-PDGFRA in Hypereosinophilic
- Page 196 and 197: FIP1L1-PDGFRA in Hypereosinophilic
- Page 198 and 199: FIP1L1-PDGFRA in Hypereosinophilic
- Page 200 and 201: FIP1L1-PDGFRA in Hypereosinophilic
- Page 202 and 203: FLT3 Mutations in AML 189 12 FLT3 M
- Page 204 and 205: FLT3 Mutations in AML 191 3.1.1. DN
- Page 206 and 207: FLT3 Mutations in AML 193 Table 2 R
- Page 208 and 209: FLT3 Mutations in AML 195 Fig. 2. D
- Page 210 and 211: FLT3 Mutations in AML 197 10. Kiyoi
- Page 212 and 213: WT1 Expression in AML and MDS 199 1
- Page 214 and 215: WT1 Expression in AML and MDS 201 T
- Page 216 and 217: WT1 Expression in AML and MDS 203 1
- Page 218 and 219: WT1 Expression in AML and MDS 205 T
- Page 220 and 221: WT1 Expression in AML and MDS 207 F
- Page 222 and 223: WT1 Expression in AML and MDS 209 2
- Page 224 and 225: WT1 Expression in AML and MDS 211 1
- Page 226 and 227: Classification of AML by DNA-Oligon
- Page 228 and 229: Classification of AML by DNA-Oligon
- Page 230 and 231: Classification of AML by DNA-Oligon
- Page 232 and 233: Classification of AML by DNA-Oligon
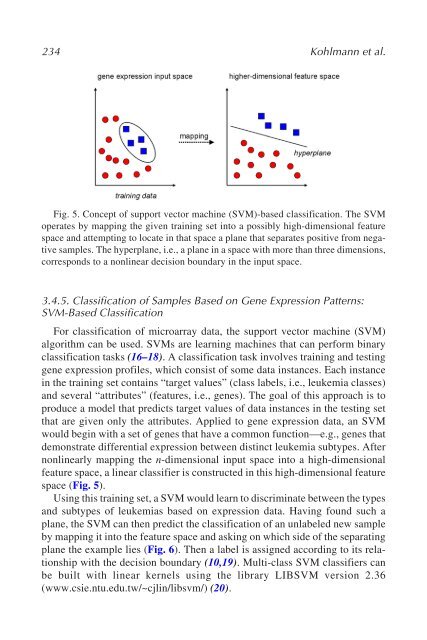
- Page 234 and 235: Classification of AML by DNA-Oligon
- Page 236 and 237: Classification of AML by DNA-Oligon
- Page 238 and 239: Classification of AML by DNA-Oligon
- Page 240 and 241: Classification of AML by DNA-Oligon
- Page 242 and 243: Classification of AML by DNA-Oligon
- Page 244 and 245: Classification of AML by DNA-Oligon
- Page 248 and 249: Classification of AML by DNA-Oligon
- Page 250 and 251: Classification of AML by DNA-Oligon
- Page 252 and 253: Classification of AML by DNA-Oligon
- Page 254 and 255: Classification of AML by Monoclonal
- Page 256 and 257: Classification of AML by Monoclonal
- Page 258 and 259: Classification of AML by Monoclonal
- Page 260 and 261: 247 Classification of AML by Monocl
- Page 262 and 263: Classification of AML by Monoclonal
- Page 264 and 265: Classification of AML by Monoclonal
- Page 266 and 267: Detecting JAK2 V617F Mutation in MP
- Page 268 and 269: Detecting JAK2 V617F Mutation in MP
- Page 270 and 271: Detecting JAK2 V617F Mutation in MP
- Page 272 and 273: Detecting JAK2 V617F Mutation in MP
- Page 274 and 275: Detecting JAK2 V617F Mutation in MP
- Page 276 and 277: Detecting JAK2 V617F Mutation in MP
- Page 278 and 279: PRV-1 Overexpression in PV and ET 2
- Page 280 and 281: PRV-1 Overexpression in PV and ET 2
- Page 282 and 283: PRV-1 Overexpression in PV and ET 2
- Page 284 and 285: PRV-1 Overexpression in PV and ET 2
- Page 286 and 287: PRV-1 Overexpression in PV and ET 2
- Page 288 and 289: Chimerism Analysis 275 18 Chimerism
- Page 290 and 291: Chimerism Analysis 277 1.2. Detecti
- Page 292 and 293: Chimerism Analysis 279 3. Extractio
- Page 294 and 295: Chimerism Analysis 281 14. 310 Gene
- Page 296 and 297:
Chimerism Analysis 283 12. Upon com
- Page 298 and 299:
Chimerism Analysis 285 Fig. 2. Calc
- Page 300 and 301:
Chimerism Analysis 287 4. Allow the
- Page 302 and 303:
Chimerism Analysis 289 capillary el
- Page 304 and 305:
Chimerism Analysis 291 and recipien
- Page 306 and 307:
Chimerism Analysis 293 Table 2 Comm
- Page 308:
Chimerism Analysis 295 12. Maas, F.
- Page 311 and 312:
298 Index management, 128 AML, see
- Page 313 and 314:
300 Index and AML, 213, 236, 238, 2
- Page 315 and 316:
302 Index chimerism analysis in sex
- Page 317 and 318:
304 Index minimal residual disease
- Page 319:
306 Index Stem cell transplantation