

antriebstechnik 6/2018
antriebstechnik 6/2018
antriebstechnik 6/2018
- TAGS
- antriebstechnik

Sie wollen auch ein ePaper? Erhöhen Sie die Reichweite Ihrer Titel.
YUMPU macht aus Druck-PDFs automatisch weboptimierte ePaper, die Google liebt.
Anteile [%]<br />
CFD-Modell<br />
CHT-Modell<br />
Rechenzeit f/tn [s]<br />
Effizienz E(n) [%]<br />
Speedup-Faktor S(n) [-]<br />
08<br />
Simulationsmodelle mit ihren Randbedingungen im<br />
Vergleich<br />
Gleichung weiter zu (9). Die Fluiderwärmung infolge innerer Reibung<br />
wird zunächst in Form des Terms berücksichtigt, gleiches<br />
gilt für die Wärmeleitung im Fluid in Form des Terms .<br />
Q in<br />
= P H<br />
≤ 2.8 kW<br />
Fluid<br />
T amb<br />
= 20 °C<br />
a= 5 W/m 2 K<br />
P<br />
out,abs = 1 bar<br />
V in<br />
≤ 14 l/min<br />
T in<br />
= 20 °C<br />
out<br />
Fluid<br />
in<br />
Im CHT-Modell (Conjugate Heat Transfer, siehe Bild 08) wird zusätzlich<br />
zur erzwungenen Konvektion im Fluid (CFD-Modell) die<br />
Wärmeleitung in den Festkörpern (Heizelement, Kühlhülse und<br />
Gehäuse) berücksichtigt. Dazu wird in den Festkörpern die Energietransportgleichung<br />
entsprechend Gl. (10) gelöst. Da der Festkörper<br />
starr ist und keine inneren Energiequellen existieren vereinfacht<br />
sich der Ansatz für den stationären Fall zu Gl. (11).<br />
09<br />
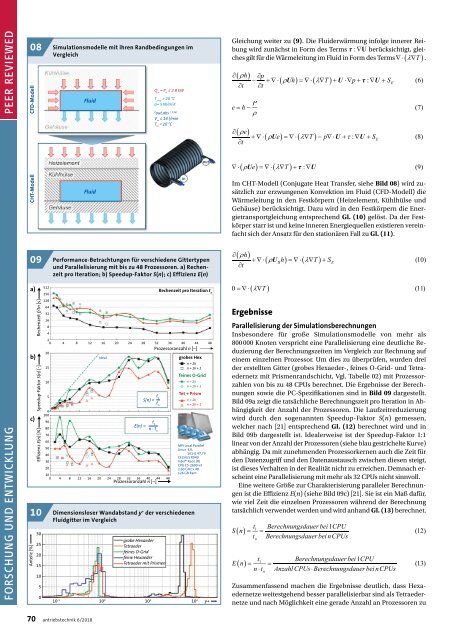
Performance-Betrachtungen für verschiedene Gittertypen<br />
und Parallelisierung mit bis zu 48 Prozessoren. a) Rechenzeit<br />
pro Iteration; b) Speedup-Faktor S(n); c) Effizienz E(n)<br />
a)<br />
b)<br />
c)<br />
10<br />
30<br />
25<br />
20<br />
15<br />
512<br />
256<br />
128<br />
64<br />
32<br />
16<br />
8<br />
4<br />
2<br />
0 4 8 12 16 20 24 28 32 36 40 44 48<br />
20<br />
15<br />
10<br />
5<br />
0<br />
100<br />
90<br />
80<br />
70<br />
60<br />
50<br />
40<br />
30<br />
20<br />
10<br />
ideal<br />
S(n) =<br />
E(n) =<br />
n . t n<br />
0 4 8 12 16 20 24 28 32 36 40 44 48<br />
t 1<br />
Prozessoranzahl n [–]<br />
Rechenzeit pro Iteration t n<br />
Prozessoranzahl n [–]<br />
t 1<br />
t n<br />
grobes Hex<br />
n = 2k<br />
n = 2k + 1<br />
feines O-Grid<br />
n = 2k<br />
n = 2k + 1<br />
Tet + Prism<br />
n = 2k<br />
n = 2k + 1<br />
MPI Local Parallel<br />
Linux 3.0.<br />
101-0.47.79<br />
CELSIUS R940<br />
Intel® Xeon (R)<br />
CPU E5-2690 v3<br />
2.60 GHz x 48<br />
126 GB Ram<br />
Dimensionsloser Wandabstand y + der verschiedenen<br />
Fluidgitter im Vergleich<br />
grobe Hexaeder<br />
Tetraeder<br />
feines O-Grid<br />
feine Hexaeder<br />
Tetraeder mit Prismen<br />
Überschrift bold<br />
Normaler Text<br />
Ergebnisse<br />
Parallelisierung der Simulationsberechnungen<br />
Insbesondere für große Simulationsmodelle von mehr als<br />
800 000 Knoten verspricht eine Parallelisierung eine deutliche Reduzierung<br />
der Berechnungszeiten im Vergleich zur Rechnung auf<br />
einem einzelnen Prozessor. Um dies zu überprüfen, wurden drei<br />
der erstellten Gitter (grobes Hexaeder-, feines O-Grid- und Tetraedernetz<br />
mit Prismenrandschicht, Vgl. Tabelle 02) mit Prozessorzahlen<br />
von bis zu 48 CPUs berechnet. Die Ergebnisse der Berechnungen<br />
sowie die PC-Spezifikationen sind in Bild 09 dargestellt.<br />
Bild 09a zeigt die tatsächliche Berechnungszeit pro Iteration in Abhängigkeit<br />
der Anzahl der Prozessoren. Die Laufzeitreduzierung<br />
wird durch den sogenannten Speedup-Faktor S(n) gemessen,<br />
welcher nach [21] entsprechend Gl. (12) berechnet wird und in<br />
Bild 09b dargestellt ist. Idealerweise ist der Speedup-Faktor 1:1<br />
linear von der Anzahl der Prozessoren (siehe blau gestrichelte Kurve)<br />
abhängig. Da mit zunehmenden Prozessorkernen auch die Zeit für<br />
den Datenzugriff und den Datenaustausch zwischen diesen steigt,<br />
ist dieses Verhalten in der Realität nicht zu erreichen. Demnach erscheint<br />
eine Parallelisierung mit mehr als 32 CPUs nicht sinnvoll.<br />
Eine weitere Größe zur Charakterisierung paralleler Berechnungen<br />
ist die Effizienz E(n) (siehe Bild 09c) [21]. Sie ist ein Maß dafür,<br />
wie viel Zeit die einzelnen Prozessoren während der Berechnung<br />
tatsächlich verwendet werden und wird anhand Gl. (13) berechnet.<br />
Überschrift bold<br />
Normaler Text<br />
10<br />
5<br />
0<br />
10 -1<br />
10 0 10 1 10 2 y+<br />
Zusammenfassend machen die Ergebnisse deutlich, dass Hexaedernetze<br />
weitestgehend besser parallelisierbar sind als Tetraedernetze<br />
und nach Möglichkeit eine gerade Anzahl an Prozessoren zu<br />
70 <strong>antriebstechnik</strong> 6/<strong>2018</strong>














