Xcell Journal: The authoritative journal for programmable ... - Xilinx
Xcell Journal: The authoritative journal for programmable ... - Xilinx
Xcell Journal: The authoritative journal for programmable ... - Xilinx

Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
Functional % of Run-Time<br />
Blocks Total Cycles<br />
mv_search.c 67.31 %<br />
block.c 8.19 %<br />
refbuf.c 6.95 %<br />
macroblock.c 3.48 %<br />
rdopt.c 3.37 %<br />
biariencode.c 3.21 %<br />
cabac.c 2.98 %<br />
memcpy.asm* 2.91 %<br />
abs.c* 0.57 %<br />
image.c 0.54 %<br />
rdopt_coding_state.c 0.46 %<br />
loopFilter.c 0.03 %<br />
Table 1 – H.264/AVC encoder<br />
complexity profile by files<br />
However, computation complexity<br />
alone does not determine if a functional<br />
module should be mapped to hardware or<br />
remain in software. To evaluate the viability<br />
of software and hardware partitioning of the<br />
H.264/AVC coding standard implementation<br />
on a plat<strong>for</strong>m that consists of a mixture<br />
of FPGAs, <strong>programmable</strong> DSPs, or generalpurpose<br />
host processors, we need to look at<br />
a number of architectural issues that influence<br />
the overall design decision.<br />
• Data locality. In a synchronous design,<br />
the ability to access memory in a particular<br />
order and granularity while minimizing<br />
the number of clock cycles due<br />
to latency, bus contention, alignment,<br />
DMA transfer rate, and the types of<br />
memory used (such as ZBT memory,<br />
SDRAM, and SRAM) is very important.<br />
<strong>The</strong> data locality issue is primarily<br />
dictated by the physical interfaces<br />
between the data unit and the arithmetic<br />
unit (or the processing engine).<br />
• Data parallelism. Most signal processing<br />
algorithms operate on data that is<br />
highly parallelizable (such as FIR filtering).<br />
Single instruction multiple data<br />
(SIMD) and vector processors are particularly<br />
efficient <strong>for</strong> data that can be<br />
parallelized or made into a vector <strong>for</strong>mat<br />
(or long data width).<br />
FPGA fabric exploits this by providing<br />
a large amount of block RAM to support<br />
numerous very high aggregate<br />
bandwidth requirements. In the new<br />
<strong>Xilinx</strong> Virtex-4 SX device family, the<br />
amount of block RAM matches closely<br />
with the number of Xtreme DSP<br />
slices (SX25 – 128 block RAM, 128<br />
DSP slices; SX35 – 192 block RAM,<br />
192 DSP slices; SX55 – 320 block<br />
RAM, 512 DSP slices).<br />
• Signal processing algorithm parallelism.<br />
In a typical <strong>programmable</strong> DSP<br />
or a general-purpose processor, signal<br />
processing algorithm parallelism is<br />
often referred to as instruction level<br />
parallelism (ILP). A very long instruction<br />
word (VLIW) processor is an<br />
example of such a machine that<br />
exploits ILP by grouping multiple<br />
instructions (ADD, MULT, and BRA)<br />
to be executed in a single cycle. A<br />
heavily pipelined execution unit in the<br />
processor is also an excellent example<br />
of hardware that exploits the parallelism.<br />
Modern <strong>programmable</strong> DSPs<br />
have adopted this architecture (including<br />
the Texas Instruments<br />
TMS320C64x).<br />
However, not all algorithms can<br />
exploit such parallelism. Recursive<br />
algorithms like IIR filtering, variablelength<br />
coding (VLC) in MPEG1/2/4,<br />
context-adaptive variable length coding<br />
(CAVLC), and context-adaptive binary<br />
arithmetic coding (CABAC) in<br />
H.264/AVC are particularly sub-optimal<br />
and inefficient when mapped to<br />
these <strong>programmable</strong> DSPs. This is<br />
because data recursion prevents ILP<br />
from being used effectively. Instead,<br />
dedicated hardware engines can be<br />
built efficiently in the FPGA fabric.<br />
• Computational complexity.<br />
Programmable DSP is bounded in<br />
computational complexity, as measured<br />
by the clock rate of the processor.<br />
Signal processing algorithms implemented<br />
in the FPGA fabric are typically<br />
computationally intensive. Some<br />
examples of these are the sum of<br />
DIGITAL SIGNAL PROCESSING<br />
absolute difference (SAD) engine in<br />
motion estimation and video scaling.<br />
By mapping these modules onto the<br />
FPGA fabric, the host processor or the<br />
<strong>programmable</strong> DSP has the extra cycles<br />
<strong>for</strong> other algorithms. Furthermore,<br />
FPGAs can have multiple clock<br />
domains in the fabric, so selective hardware<br />
blocks can thus have separate<br />
clock speeds based on their computational<br />
requirements.<br />
• <strong>The</strong>oretic optimality in quality. Any<br />
theoretic optimal solution based on<br />
the rate-distortion curve can be<br />
achieved if and only if the complexity<br />
is unbounded. In a <strong>programmable</strong><br />
DSP or general-purpose processor, the<br />
computational complexity is always<br />
bounded by the clock cycles available.<br />
FPGAs, on the other hand, offer much<br />
more flexibility by exploiting data and<br />
algorithm parallelism by means of<br />
multiple instantiations of the hardware<br />
engines, or increased use of block<br />
RAM and register banks in the fabric.<br />
A <strong>programmable</strong> DSP or general-purpose<br />
processor is often limited by the<br />
number of instruction issues per cycle,<br />
the level of pipeline in the execution<br />
unit, or the maximum data width to<br />
fully feed the execution units. Video<br />
quality is often compromised as a result<br />
of the limited cycles available per task<br />
in a <strong>programmable</strong> DSP, whereas hardware<br />
resources are fully allocated in<br />
FPGA fabric (three-step vs. full-search<br />
motion estimation).<br />
Implementing Functional Modules onto FPGAs<br />
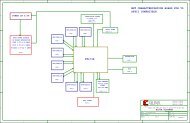
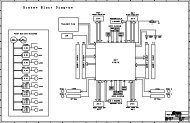
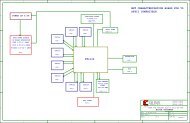
Figure 1 shows the overall H.264/AVC<br />
macroblock level encoder with major functional<br />
blocks and data flows defined. One<br />
of the primary successes of the H.264/AVC<br />
standard is its ability to predict the values<br />
of the content of a picture to be encoded by<br />
exploiting the pixel redundancy in different<br />
ways and directions not exploited previously<br />
in other standards. Un<strong>for</strong>tunately, when<br />
comparing to previous standards, this<br />
increases the complexity and memory<br />
access bandwidth approximately four-fold.<br />
Winter 2004 <strong>Xcell</strong> <strong>Journal</strong> 41