

Es war einmal.. .. eine Zelle und sie wurde nimmermehr gesehen?
LJ_16_07
LJ_16_07

Erfolgreiche ePaper selbst erstellen
Machen Sie aus Ihren PDF Publikationen ein blätterbares Flipbook mit unserer einzigartigen Google optimierten e-Paper Software.
<strong>Es</strong>say<br />
schaft solche kognitionswissenschaftlichen<br />
Studien wie oben erwähnt durch bildgebende<br />
Verfahren wie etwa die funktionelle<br />
Magnetresonanztomographie (fMRT) erweitert.<br />
Gr<strong>und</strong>sätzlich sind z<strong>war</strong> ähnliche<br />
Replikationsraten zu er<strong>war</strong>ten, insbesondere<br />
zwei Faktoren können diese hier allerdings<br />
noch weiter nach unten ziehen:<br />
niedrigere Probengrößen <strong>und</strong> weitverbreitete<br />
Missverständnisse über die multiple<br />
Testkorrektur bei fMRT.<br />
Zum Thema niedrigere Probengrößen<br />
können wir uns kurz fassen: Die oben erwähnte<br />
Studie über präklinisch-neurowissenschaftliche<br />
Arbeiten untersuchte<br />
überdies auch Neuroimaging-Projekte mit<br />
menschlichen Probanden – <strong>und</strong> berichtet<br />
<strong>eine</strong> mittlere statistische Power von lediglich<br />
acht Prozent (4). Das ist absurd niedrig<br />
<strong>und</strong> ist wahrscheinlich den hohen Investitionen<br />
an Zeit <strong>und</strong> Kosten selbst bei kl<strong>eine</strong>n<br />
fMRT-Studien geschuldet. Schlimmer aber<br />
ist, dass einige offenbar nicht verstehen,<br />
dass man mit <strong>eine</strong>r regulären fMRT-Analyse<br />
leicht 200.000 Voxel testen kann. Und<br />
man muss dabei nicht <strong>einmal</strong> 200.000 Testentscheidungen<br />
korrigieren– zum Beispiel<br />
indem man Alpha durch 200.000 dividiert<br />
–, da diese Voxel ja miteinander korreliert<br />
sind...<br />
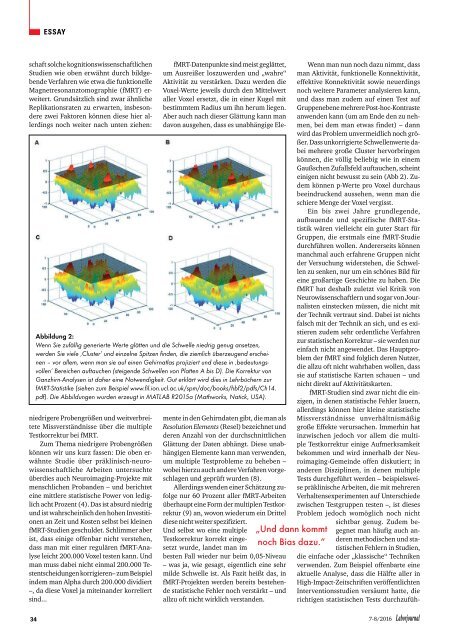
Abbildung 2:<br />
Wenn Sie zufällig generierte Werte glätten <strong>und</strong> die Schwelle niedrig genug ansetzen,<br />
werden Sie viele ‚Cluster’ <strong>und</strong> einzelne Spitzen finden, die ziemlich überzeugend ersch<strong>eine</strong>n<br />
– vor allem, wenn man <strong>sie</strong> auf <strong>eine</strong>n Gehirnatlas projiziert <strong>und</strong> diese in ‚bedeutungsvollen’<br />
Bereichen auftauchen (steigende Schwellen von Platten A bis D). Die Korrektur von<br />
Ganzhirn-Analysen ist daher <strong>eine</strong> Notwendigkeit. Gut erklärt wird dies in Lehrbüchern zur<br />
fMRT-Statistike (<strong>sie</strong>hen zum Beispiel www.fil.ion.ucl.ac.uk/spm/doc/books/hbf2/pdfs/Ch14.<br />
pdf). Die Abbildungen <strong>wurde</strong>n erzeugt in MATLAB R2015a (Mathworks, Natick, USA).<br />
fMRT-Datenpunkte sind meist geglättet,<br />
um Ausreißer loszuwerden <strong>und</strong> „wahre“<br />
Aktivität zu verstärken. Dazu werden die<br />
Voxel-Werte jeweils durch den Mittelwert<br />
aller Voxel ersetzt, die in <strong>eine</strong>r Kugel mit<br />
bestimmtem Radius um ihn herum liegen.<br />
Aber auch nach dieser Glättung kann man<br />
davon ausgehen, dass es unabhängige Elemente<br />
in den Gehirndaten gibt, die man als<br />
Resolution Elements (Resel) bezeichnet <strong>und</strong><br />
deren Anzahl von der durchschnittlichen<br />
Glättung der Daten abhängt. Diese unabhängigen<br />
Elemente kann man verwenden,<br />
um multiple Testprobleme zu beheben –<br />
wobei hierzu auch andere Verfahren vorgeschlagen<br />
<strong>und</strong> geprüft <strong>wurde</strong>n (8).<br />
Allerdings wenden <strong>eine</strong>r Schätzung zufolge<br />
nur 60 Prozent aller fMRT-Arbeiten<br />
überhaupt <strong>eine</strong> Form der multiplen Testkorrektur<br />
(9) an, wovon wiederum ein Drittel<br />
diese nicht weiter spezifiziert.<br />
Und selbst wo <strong>eine</strong> multiple<br />
Testkorrektur korrekt eingesetzt<br />
<strong>wurde</strong>, landet man im<br />
besten Fall wieder nur beim 0,05-Niveau<br />
– was ja, wie gesagt, eigentlich <strong>eine</strong> sehr<br />
milde Schwelle ist. Als Fazit heißt das, in<br />
fMRT-Projekten werden bereits bestehende<br />
statistische Fehler noch verstärkt – <strong>und</strong><br />
allzu oft nicht wirklich verstanden.<br />
„Und dann kommt<br />
noch Bias dazu.“<br />
Wenn man nun noch dazu nimmt, dass<br />
man Aktivität, funktionelle Konnektivität,<br />
effektive Konnektivität sowie neuerdings<br />
noch weitere Parameter analy<strong>sie</strong>ren kann,<br />
<strong>und</strong> dass man zudem auf <strong>eine</strong>n Test auf<br />
Gruppenebene mehrere Post-hoc-Kontraste<br />
anwenden kann (um am Ende den zu nehmen,<br />
bei dem man etwas findet) – dann<br />
wird das Problem unvermeidlich noch größer.<br />
Dass unkorrigierte Schwellenwerte dabei<br />
mehrere große Cluster hervorbringen<br />
können, die völlig beliebig wie in <strong>eine</strong>m<br />
Gaußschen Zufallsfeld auftauchen, scheint<br />
einigen nicht bewusst zu sein (Abb 2). Zudem<br />
können p-Werte pro Voxel durchaus<br />
beeindruckend aussehen, wenn man die<br />
schiere Menge der Voxel vergisst.<br />
Ein bis zwei Jahre gr<strong>und</strong>legende,<br />
aufbauende <strong>und</strong> spezifische fMRT-Statistik<br />
wären vielleicht ein guter Start für<br />
Gruppen, die erstmals <strong>eine</strong> fMRT-Studie<br />
durchführen wollen. Andererseits können<br />
manchmal auch erfahrene Gruppen nicht<br />
der Versuchung widerstehen, die Schwellen<br />
zu senken, nur um ein schönes Bild für<br />
<strong>eine</strong> großartige Geschichte zu haben. Die<br />
fMRT hat deshalb zuletzt viel Kritik von<br />
Neurowissenschaftlern <strong>und</strong> sogar von Journalisten<br />
einstecken müssen, die nicht mit<br />
der Technik vertraut sind. Dabei ist nichts<br />
falsch mit der Technik an sich, <strong>und</strong> es existieren<br />
zudem sehr ordentliche Verfahren<br />
zur statistischen Korrektur – <strong>sie</strong> werden nur<br />
einfach nicht angewendet. Das Hauptproblem<br />
der fMRT sind folglich deren Nutzer,<br />
die allzu oft nicht wahrhaben wollen, dass<br />
<strong>sie</strong> auf statistische Karten schauen – <strong>und</strong><br />
nicht direkt auf Aktivitätskarten.<br />
fMRT-Studien sind z<strong>war</strong> nicht die einzigen,<br />
in denen statistische Fehler lauern,<br />
allerdings können hier kl<strong>eine</strong> statistische<br />
Missverständnisse unverhältnismäßig<br />
große Effekte verursachen. Immerhin hat<br />
inzwischen jedoch vor allem die multiple<br />
Testkorrektur einige Aufmerksamkeit<br />
bekommen <strong>und</strong> wird innerhalb der Neuroimaging-Gemeinde<br />
offen diskutiert; in<br />
anderen Disziplinen, in denen multiple<br />
Tests durchgeführt werden – beispielsweise<br />
präklinische Arbeiten, die mit mehreren<br />
Verhaltensexperimenten auf Unterschiede<br />
zwischen Testgruppen testen –, ist dieses<br />
Problem jedoch womöglich noch nicht<br />
sichtbar genug. Zudem begegnet<br />
man häufig auch anderen<br />
methodischen <strong>und</strong> statistischen<br />
Fehlern in Studien,<br />
die einfache oder „klassische“ Techniken<br />
verwenden. Zum Beispiel offenbarte <strong>eine</strong><br />
aktuelle Analyse, dass die Hälfte aller in<br />
High-Impact-Zeitschriften veröffentlichten<br />
Interventionsstudien versäumt hatte, die<br />
richtigen statistischen Tests durchzufüh-<br />
34<br />
7-8/2016 Laborjournal



