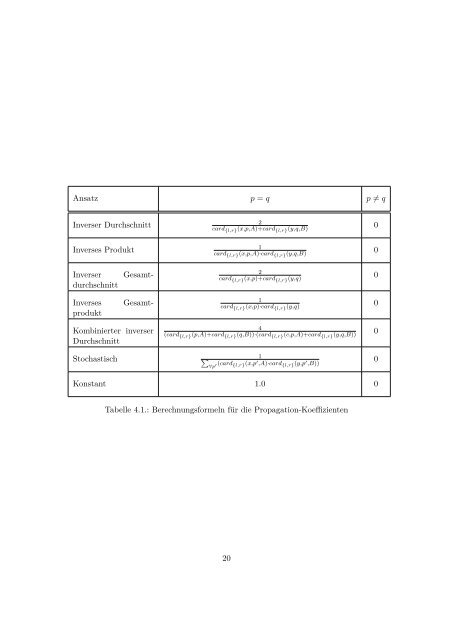
Ansatz p = q p ≠ q Inverser Durchschnitt 2 card {l,r} (x,p,A)+card {l,r} (y,q,B) 0 Inverses Produkt 1 card {l,r} (x,p,A)·card {l,r} (y,q,B) 0 Gesamt- Inverser durchschnitt Inverses produkt Gesamt- 2 card {l,r} (x,p)+card {l,r} (y,q) 0 1 card {l,r} (x,p)·card {l,r} (y,q) 0 Kombinierter inverser Durchschnitt 4 (card {l,r} (p,A)+card {l,r} (q,B))·(card {l,r} (c,p,A)+card {l,r} (y,q,B)) 0 1 Stochastisch ∑ ∀p ′ (card {l,r} (x,p ′ ,A)·card {l,r} (y,p ′ ,B)) 0 Konstant 1.0 0 Tabelle 4.1.: Berechnungsformeln für die Propagation-Koeffizienten 20
Abbildung 4.3.: Similarity Propagation Graph zu A <strong>und</strong> B Propagation-Koeffizienten bezogen auf zwei Map Pairs im PCG berechnet. Die beiden hier vorgestellten Formeln für π berechnen die Propagation-Koeffizienten in Abhängigkeit der Anzahl eingehender <strong>und</strong> ausgehender Kanten in den Modellen A <strong>und</strong> B. Die inverse Produktformel berechnet zum Beispiel π dabei wie folgt: ⎧ ⎨ 1 card π {l,r} (〈x, p, A〉, 〈y, q, B〉) = {l,r} (x,p,A)·card {l,r} (y,q,B) , wenn p = q ⎩0, wenn p ≠ q Da die Formel π für die ausgehenden (π l ) <strong>und</strong> eingehenden (π r ) Kanten gleichermaßen berechnet wird, wird hier abkürzend die Schreibweise π {l,r} verwendet. card l (x, p, M) = |{(x, p, t)|∃t : (x, p, t) ∈ M}| bezeichnet die Anzahl der ausgehenden Kanten eines Knotens x mit dem Label p in M <strong>und</strong> card r (x, p, M) = |{(t, p, x)|∃t : (t, p, x) ∈ M}| die Anzahl der eingehenden, mit p beschrifteten Kanten. card {l,r} ist ebenfalls eine abkürzende Schreibweise, wobei gilt: card {l,r} (x, p, A) = { cardl (x, p, A), wenn π l berechnet wird card r (x, p, A), wenn π r berechnet wird Um nach der inversen Produktformel zum Beispiel den Propagation-Koeffizienten der ausgehenden Kanten eines Map Pairs (a, b) für zwei Modelle A <strong>und</strong> B mit a ∈ A <strong>und</strong> b ∈ B zu berechnen, wird die Anzahl der ausgehenden Kanten des Knotens a in Modell A mit der Anzahl der ausgehenden Kanten des Knotens b in Modell B multipliziert <strong>und</strong> das Ergebnis invertiert. Voraussetzung ist wie bei der Konstruktion des PCG, dass es überhaupt gleich beschriftete Kanten gibt, die von a <strong>und</strong> b ausgehen. Ansonsten wird als Wert für den Propagation-Koeffizienten 0 zurückgegeben, der darauf hinweist, dass es im PCG der Modelle A <strong>und</strong> B keine ausgehende Kante des Map Pairs (a, b) gibt. Abbildung 4.3 zeigt den zu A <strong>und</strong> B gehörenden SPG. Für die Berechnung des Propagation-Koeffizienten einer Kante ((x 1 , y 1 ), p, (x 2 , y 2 )) wurde hier die inverse Pro- 21
- Seite 1 und 2: Leibniz Universität Hannover Insti
- Seite 3 und 4: Inhaltsverzeichnis 1. Einleitung 5
- Seite 5 und 6: 1. Einleitung 1.1. Motivation und S
- Seite 7 und 8: 2. Grundlagen In diesem Kapitel sol
- Seite 9 und 10: Möglichkeiten erläutert, wie Mapp
- Seite 11 und 12: (etwa OLA oder Microsoft BizTalk Ma
- Seite 13 und 14: Abbildung 3.2.: Klassifizierung von
- Seite 15 und 16: 4. Der Similarity Flooding Algorith
- Seite 17 und 18: Definition 4.1 Seien A und B zwei M
- Seite 19: Gemäß der Definition wird also zu
- Seite 23 und 24: durch die Formel darstellen, wobei
- Seite 25 und 26: Tabelle 4.3 dargestellt sind. Währ
- Seite 27 und 28: Abbildung 4.4.: Bipartiter Graph (l
- Seite 29 und 30: Das Zuordnungsproblem Beim Zuordnun
- Seite 31 und 32: 5. Vergleich mit anderen Verfahren
- Seite 33 und 34: (vorgeschlagen ist ein Unterschied
- Seite 35 und 36: durchgeführt werden müssen, um ei
- Seite 37 und 38: 6. Implementierung der Testumgebung
- Seite 39 und 40: Abbildung 6.4.: Menü mit den Anfan
- Seite 41 und 42: Abbildung 6.7.: Filterung der Ergeb
- Seite 43 und 44: AUTOR(Name (PK), Geburtsdatum); BUC
- Seite 45 und 46: sich allein mit der Qualität des V
- Seite 47 und 48: Die Graphen 3, 4 und 5 sind jeweils
- Seite 49 und 50: Graph 1 2 3 4 5 6 7 |Knoten| 6 15 8
- Seite 51 und 52: wie sich das allgemein auf das Simi
- Seite 53 und 54: Knoten Iteration 1 (a, b) 0 (a 1 ,
- Seite 55 und 56: Knoten Iteration 1 2 3 10 20 30 40
- Seite 57 und 58: gorithmus arbeiten muss, um zu eine
- Seite 59 und 60: Die Beobachtung, dass sich die Kand
- Seite 61 und 62: Knoten Iteration 1 2 3 4 5 6 7 8 9
- Seite 63 und 64: Einstellen niedriger Anfangsähnlic
- Seite 65 und 66: eines Schemas in einen Graphen. Im
- Seite 67 und 68: ER_MITARBEITER aus Schema 2 kann zu
- Seite 69 und 70: 1 für α in der Vorverarbeitung da
- Seite 71 und 72:
Musiksammlung Bei den Musiksammlung
- Seite 73 und 74:
durch Festlegen von Anfangsähnlich
- Seite 75 und 76:
den Benutzer berücksichtigt wurde,
- Seite 77 und 78:
Literaturverzeichnis [DMR02] [Dra93
- Seite 79 und 80:
A. Anhang - Für Experimente verwen
- Seite 81 und 82:
A.2. Graph 2 Abbildung A.4.: Graph
- Seite 83 und 84:
A.3. Graph 3 Abbildung A.7.: Graph
- Seite 85 und 86:
Abbildung A.10.: Graph 4: Pairwise
- Seite 87 und 88:
Abbildung A.12.: Graph 5: Pairwise
- Seite 89 und 90:
Abbildung A.14.: Graph 6: Pairwise
- Seite 91 und 92:
Abbildung A.16.: Graph 7: Pairwise
- Seite 93 und 94:
Abbildung B.3.: Graph zu Schema 1 9
- Seite 95 und 96:
B.2. Bustouren STADT (Name, Highlig
- Seite 97 und 98:
Abbildung B.8.: Graph zu Schema 2 9
- Seite 99 und 100:
Abbildung B.11.: Graph zu Schema 1
- Seite 101 und 102:
B.4. Filmdatenbank MOVIE (movie, ti
- Seite 103 und 104:
Abbildung B.16.: Graph zur Schema 2
- Seite 105 und 106:
Schema 1 Schema 2 Ähnlichkeitswert
- Seite 107 und 108:
Schema 1 Schema 2 Ähnlichkeitswert
- Seite 109 und 110:
Schema 1 Schema 2 Ähnlichkeitswert
- Seite 111 und 112:
Schema 1 Schema 2 Ähnlichkeitswert
- Seite 113 und 114:
Schema 1 Schema 2 Ähnlichkeitswert
- Seite 115 und 116:
Schema 1 Schema 2 Ähnlichkeitswert
- Seite 117 und 118:
Schema 1 Schema 2 Ähnlichkeitswert
- Seite 119:
Schema 1 Schema 2 Ähnlichkeitswert