

Software Reliability Engineering im Infotainment - Georg-August ...
Software Reliability Engineering im Infotainment - Georg-August ...
Software Reliability Engineering im Infotainment - Georg-August ...

Erfolgreiche ePaper selbst erstellen
Machen Sie aus Ihren PDF Publikationen ein blätterbares Flipbook mit unserer einzigartigen Google optimierten e-Paper Software.
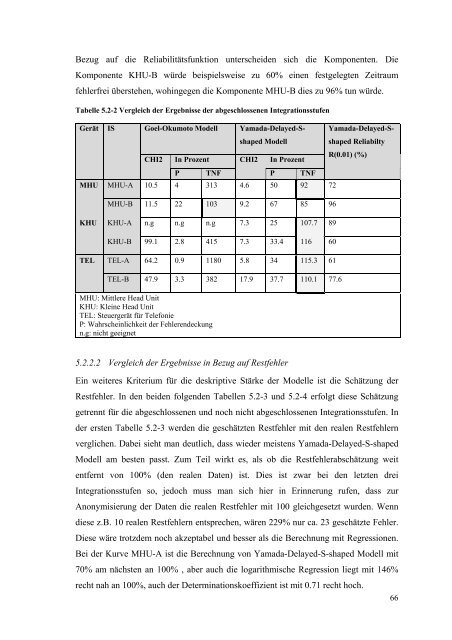
Bezug auf die Reliabilitätsfunktion unterscheiden sich die Komponenten. Die<br />
Komponente KHU-B würde beispielsweise zu 60% einen festgelegten Zeitraum<br />
fehlerfrei überstehen, wohingegen die Komponente MHU-B dies zu 96% tun würde.<br />
Tabelle 5.2-2 Vergleich der Ergebnisse der abgeschlossenen Integrationsstufen<br />
Gerät<br />
MHU<br />
IS Goel-Okumoto Modell Yamada-Delayed-Sshaped<br />
Modell<br />
Yamada-Delayed-Sshaped<br />
Reliabilty<br />
CHI2 In Prozent CHI2 In Prozent<br />
R(0.01) (%)<br />
P TNF<br />
P TNF<br />
MHU-A 10.5 4 313 4.6 50 92 72<br />
MHU-B 11.5 22 103 9.2 67 85 96<br />
KHU<br />
KHU-A n.g n.g n.g 7.3 25 107.7 89<br />
KHU-B 99.1 2.8 415 7.3 33.4 116 60<br />
TEL<br />
TEL-A 64.2 0.9 1180 5.8 34 115.3 61<br />
TEL-B 47.9 3.3 382 17.9 37.7 110.1 77.6<br />
MHU: Mittlere Head Unit<br />
KHU: Kleine Head Unit<br />
TEL: Steuergerät für Telefonie<br />
P: Wahrscheinlichkeit der Fehlerendeckung<br />
n.g: nicht geeignet<br />
5.2.2.2 Vergleich der Ergebnisse in Bezug auf Restfehler<br />
Ein weiteres Kriterium für die deskriptive Stärke der Modelle ist die Schätzung der<br />
Restfehler. In den beiden folgenden Tabellen 5.2-3 und 5.2-4 erfolgt diese Schätzung<br />
getrennt für die abgeschlossenen und noch nicht abgeschlossenen Integrationsstufen. In<br />
der ersten Tabelle 5.2-3 werden die geschätzten Restfehler mit den realen Restfehlern<br />
verglichen. Dabei sieht man deutlich, dass wieder meistens Yamada-Delayed-S-shaped<br />
Modell am besten passt. Zum Teil wirkt es, als ob die Restfehlerabschätzung weit<br />
entfernt von 100% (den realen Daten) ist. Dies ist zwar bei den letzten drei<br />
Integrationsstufen so, jedoch muss man sich hier in Erinnerung rufen, dass zur<br />
Anonymisierung der Daten die realen Restfehler mit 100 gleichgesetzt wurden. Wenn<br />
diese z.B. 10 realen Restfehlern entsprechen, wären 229% nur ca. 23 geschätzte Fehler.<br />
Diese wäre trotzdem noch akzeptabel und besser als die Berechnung mit Regressionen.<br />
Bei der Kurve MHU-A ist die Berechnung von Yamada-Delayed-S-shaped Modell mit<br />
70% am nächsten an 100% , aber auch die logarithmische Regression liegt mit 146%<br />
recht nah an 100%, auch der Determinationskoeffizient ist mit 0.71 recht hoch.<br />
66













