

GUIDE WAVE ANALYSIS AND FORECASTING - WMO
GUIDE WAVE ANALYSIS AND FORECASTING - WMO
GUIDE WAVE ANALYSIS AND FORECASTING - WMO

Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
Probability of non-exceedance<br />
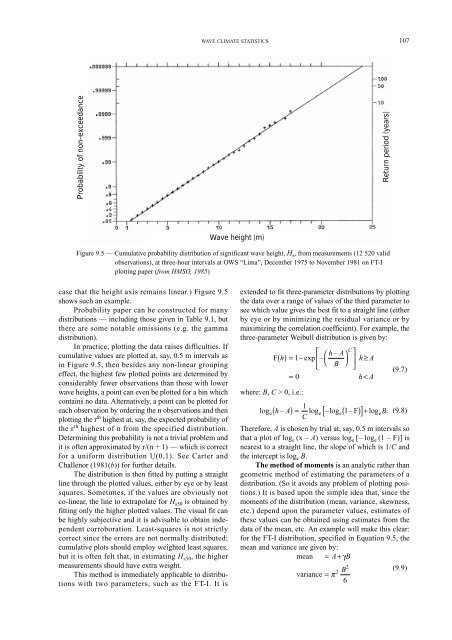
case that the height axis remains linear.) Figure 9.5<br />
shows such an example.<br />
Probability paper can be constructed for many<br />
distributions — including those given in Table 9.1, but<br />
there are some notable omissions (e.g. the gamma<br />
distribution).<br />
In practice, plotting the data raises difficulties. If<br />
cumulative values are plotted at, say, 0.5 m intervals as<br />
in Figure 9.5, then besides any non-linear grouping<br />
effect, the highest few plotted points are determined by<br />
considerably fewer observations than those with lower<br />
wave heights, a point can even be plotted for a bin which<br />
contains no data. Alternatively, a point can be plotted for<br />
each observation by ordering the n observations and then<br />
plotting the r th highest at, say, the expected probability of<br />
the r th highest of n from the specified distribution.<br />
Determining this probability is not a trivial problem and<br />
it is often approximated by r/(n + 1) — which is correct<br />
for a uniform distribution U(0,1). See Carter and<br />
Challenor (1981(b)) for further details.<br />
The distribution is then fitted by putting a straight<br />
line through the plotted values, either by eye or by least<br />
squares. Sometimes, if the values are obviously not<br />
co-linear, the line to extrapolate for H s50 is obtained by<br />
fitting only the higher plotted values. The visual fit can<br />
be highly subjective and it is advisable to obtain independent<br />
corroboration. Least-squares is not strictly<br />
correct since the errors are not normally distributed;<br />
cumulative plots should employ weighted least squares,<br />
but it is often felt that, in estimating H s50, the higher<br />
measurements should have extra weight.<br />
This method is immediately applicable to distributions<br />
with two parameters, such as the FT-I. It is<br />
<strong>WAVE</strong> CLIMATE STATISTICS 107<br />
Wave height (m)<br />
Figure 9.5 — Cumulative probability distribution of significant wave height, H s, from measurements (12 520 valid<br />
observations), at three-hour intervals at OWS “Lima”, December 1975 to November 1981 on FT-I<br />
plotting paper (from HMSO, 1985)<br />
Return period (years)<br />
extended to fit three-parameter distributions by plotting<br />
the data over a range of values of the third parameter to<br />
see which value gives the best fit to a straight line (either<br />
by eye or by minimizing the residual variance or by<br />
maximizing the correlation coefficient). For example, the<br />
three-parameter Weibull distribution is given by:<br />
(9.7)<br />
where: B, C > 0, i.e.:<br />
(9.8)<br />
Therefore, A is chosen by trial at, say, 0.5 m intervals so<br />
that a plot of loge (x – A) versus loge [– loge (1 – F)] is<br />
nearest to a straight line, the slope of which is 1/C and<br />
the intercept is loge B.<br />
The method of moments is an analytic rather than<br />
geometric method of estimating the parameters of a<br />
distribution. (So it avoids any problem of plotting positions.)<br />
It is based upon the simple idea that, since the<br />
moments of the distribution (mean, variance, skewness,<br />
etc.) depend upon the parameter values, estimates of<br />
these values can be obtained using estimates from the<br />
data of the mean, etc. An example will make this clear:<br />
for the FT-I distribution, specified in Equation 9.5, the<br />
mean and variance are given by:<br />
mean = A+ γB<br />
B<br />
(9.9)<br />
variance = π 2<br />
C ⎡ h A<br />
F( h)<br />
= −<br />
⎛ – ⎞ ⎤<br />
1 exp ⎢–<br />
h A<br />
⎝ B ⎠<br />
⎥ ≥<br />
⎣ ⎦<br />
= 0<br />
h< A<br />
1<br />
loge( h– A)<br />
= loge[ – loge( 1–<br />
F) ]+ logeB.<br />
C<br />
2<br />
6














