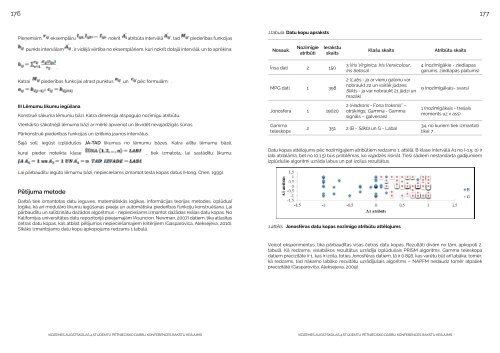
176 177Pieņemsim, eksemplāru nokrīt atribūta intervālā , tad piederības funkcijas1.tabula. Datu kopu aprakstspunkts intervālam, ir vidējā vērtība no eksemplāriem, kuri nokrīt dotajā intervālā, un to aprēķina:Nosauk.NozīmīgieatribūtiIerakstuskaitsKlašu skaitsAtribūtu skaits.Īrisa dati 2 1503 (Iris Virginica, Iris Versicolour,Iris Setosa)4 (nozīmīgākie - ziedlapasgarums, ziedlapas platums)Katrai piederības funkcijai atrast punktus un pēc formulām: .MPG dati 1 3982 (Labs - ja ar vienu galonu varnobraukt 22 un vairāk jūdzes;Slikts - ja var nobraukt 21 jūdzi unmazāk)9 (nozīmīgākais- svars)III Lēmumu likumu iegūšanaKonstruē sākuma lēmumu bāzi. Katra dimensija atspoguļo nozīmīgu atribūtu.Vienkāršo sākotnējā lēmuma bāzi ar mērķi apvienot un likvidēt nevajadzīgās šūnas.Pārkonstruē piederības funkcijas un izrēķina jaunos intervālus.Jonosfera 1 19020Gammateleskops2 (Hadrons - Fona troksnis” –otršķirīgs; Gamma - Gammasignāls – galvenais)2 351 2 (B - Slikta un G - Laba)1 (nozīmīgākais - trešaismoments uz x ass)34, no kuriem tiek izmantotitikai 7Šajā solī, iegūst izplūdušos JA-TAD likumus no lēmumu bāzes. Katra ailīte lēmumu bāzē,kurai pieder noteikta klase, tiek izmatota, lai sastādītu likumu:Datu kopas attēlojums pēc nozīmīgajiem atribūtiem redzams 1. attēlā. B klase intervālā A1 no (-1.5; 0) irlabi atdalāma, bet no (0;1.5) būs problēmas, ko vajadzēs risināt. Tieši šādiem nestandarta gadījumiemizplūdušie algoritmi uzrāda labus un pat izcilus rezultātus.Lai pārbaudītu iegūto lēmumu bāzi, nepieciešams izmantot testa kopas datus (Hong, Chen, 1999).Pētījuma metodeDarbā tiek izmantotas datu ieguves, matemātiskās loģikas, informācijas teorijas metodes, izplūdusīloģika, kā arī modulāro likumu iegūšanas pieeja un automātiska piederības funkciju konstruēšana. Laipārbaudītu un salīdzinātu dažādos algoritmus - nepieciešams izmantot dažādas reālas datu kopas. NoKalifornijas universitātes datu repozitorijā pieejamajām (Asuncion, Newman, 2007) datiem, tika atlasītasčetras datu kopas, kas atbilst pētījumos nepieciešamajiem kritērijiem (Gasparovica, Aleksejeva, 2010).Sīkāks izmantojamo datu kopu apkopojums redzams 1.tabulā.1.attēls. Jonosfēras datu kopas nozīmīgo atribūtu attēlojumsVeicot eksperimentus, tika pārbaudītas visas četras datu kopas. Rezultāti divām no tām, apkopoti 2.tabulā. Kā redzams, vislabākos rezultātus uzrādīja izplūdušais PRISM algoritms, Gamma teleskopadatiem precizitāte ir 1, kas ir izcila, toties Jonosfēras datiem, tā ir 0.856, kas varētu būt arī labāka; tomēr,kā redzams, tad nākamo labāko rezultātu uzrādījušais algoritms – NAPFM nedaudz tomēr atpaliekprecizitātē (Gasparoviča, Aleksejeva, 2009).<strong>Vidzemes</strong> <strong>Augstskola</strong>s 4.Studentu pētniecisko darbu konferences rakstu krājums<strong>Vidzemes</strong> <strong>Augstskola</strong>s 4.Studentu pētniecisko darbu konferences rakstu krājums
178 1792.tabula. Veikto eksperimentu rezultāti3.tabula. Algoritmu īss salīdzinājumsApmāc.kopaTestakopaKļūd.klasif.PrecizitāteKļūdaLikumuskaitsPRISM 13314 5706 23 0.99597 0.004 2KomentāriKlasiskaissadalījums (70:30)Dalījums 2 intervāliPRISMDarbībasprincipsMeklē labākāsatribūtu – vērtībukombinācijasPriekšrocības Nosacījums Komentārs*Universālāks*Mazāks vērtībuskitsKategoriski datiun nav izplūdumaLabs rezultāts,vidējsskaitļošanas laiksGammateleskopadatiJonosfērasdatiIzplūd.PRISM13314 5706 0 1 0 2NAPFM 13314 5706 284 0.95 0.500 2PRISM 247 104 12+7 0.817 0.183 75Izplūd.PRISM247 104 15+1 0.856 0.144 33NAPFM 247 104 16+6 0.788 0.212 61Klasiskaissadalījums (70:30)Dalījums 2intervāliKlasiskaissadalījums (70:30)Dalījums 2 intervāliKlasiskaissadalījums (70:30)Klasiskaissadalījums (70:30)3 atribūtiKlasiskaissadalījums (70:30)IzplūdušaisPRISMNAPFMMeklē labākāsatribūtu – vērtībuizplūdušāspiederībasfunkcijasMeklēnozīmīgāko(-os)atribūtu, no kuraveido likumus,pārējos atribūtusatmetot*Universālāks,kategoriski dati*Iekļauj ekspertaviedokli*Automātiskapiederībasfunkcijukonstruēšana*Neliels lēmumulikumu skaitsJa sākotnējie datiViens nozīmīgsatribūtsVairāk kā viensnozīmīgs atribūtsViens nozīmīgsatribūtsSākotnējie datiKategoriski datiVislabākaisrezultāts, lielslikumu unskaitļošanas laiksLabs rezultāts īsālaikāĪsā laikā labsrezultātsSkaitliskinepārtrauktiRezultātiPētījuma mērķis ir sasniegts - izpētīti un analizēti izplūdušie klasifikācijas algoritmi, noskaidrotas topriekšrocības attiecībā pret klasiskiem algoritmiem un sniegtas rekomendācijas algoritmu praktiskampielietojumam. Apkopojums par pētīto algoritmu darbības principiem redzams 3. tabulā.Darba rezultātā izpildīti visi izvirzītie mērķi - izpētīti izplūdušo klasifikācijas algoritmu darbības principi;veikti pētījumi par citām radniecīgām metodēm izplūdušu datu klasificēšanā, no kurām dažasperspektīvākās – FAQR (Wang, Tsai, Hong, Tseng, 2003), Nozīmīgo atribūtu un piederības funkcijumeklēšanas algoritma MMTF versija (Hong, Chen, 2000) – tiek nolemts sīkāk aplūkot nākotnē; definētakatra algoritma piemērotība pētāmām datu kopām, lai sasniegtu labākas kvalitātes rezultātus, sākotnējitika veikti eksperimenti, lai noskaidrotu prasības datu kopām, pēc tam tika meklētas atbilstošāsdatu kopas un ar perspektīvākajām veikti papildu eksperimenti, lai atlasītu atbilstošās izmantošanaisalīdzinošajā algoritmu iespēju pētīšanā; sastādīts eksperimentu plāns perspektīvākajām datu kopāmar mērķi veikt izplūdušo klasifikācijas algoritmu salīdzinošo analīzi; sniegtas rekomendācijas algoritmuizmantošanas iespējām, atkarībā no datu kopas sastāva un struktūras.Rakstot šo darbu un veicot dažādos eksperimentus, visi trīs pētāmie algoritmi tika apgūti un tikanoskaidrotas to prasības attiecībā pret apstrādājamajiem datiem. Sarežģīti bija atrast piemērotas datukopas, ar ko abi izplūdušie algoritmi spējīgi korekti darboties. Tika caurskatītas UCI datu repozitorijāpieejamās datu kopas, ar mērķi atrast perspektīvās, ko tālāk pārbaudīt, izmantojot MS Excell vidēizveidotu algoritmu sākotnējo posmu moduli – čaulu.Galvenie secinājumiIzplūdušo algoritmu izmantošana klasifikācijas uzdevumā var uzlabot rezultātu. Pat ja aprēķinu gaitākāds atribūts uzrāda niecīgu rezultātu nozīmīgumā, to nevar atmest tālākajiem eksperimentiem (javien tas nav algoritmā īpaši noteikts). Ja viens atribūts sākotnējā datu kopā kļūst par nozīmīgāko un varveiksmīgi klasificēt jaunus datus, tad, viennozīmīgi, šādai datu kopai vislabākos rezultātus visīsākajālaikā sasniegs nozīmīgo atribūtu un piederības funkciju meklēšanas algoritms. Ja sākotnējā datu kopasastāv no neliela atribūtu skaita – četriem, un divi atribūti ir nozīmīgākie, tad labākas klases rezultātus<strong>Vidzemes</strong> <strong>Augstskola</strong>s 4.Studentu pētniecisko darbu konferences rakstu krājums<strong>Vidzemes</strong> <strong>Augstskola</strong>s 4.Studentu pētniecisko darbu konferences rakstu krājums
- Page 1 and 2:
Vidzemes Augstskolas4.Studentu pēt
- Page 5 and 6:
6 7Vidzemes Augstskolas 2005. gada
- Page 7 and 8:
10 11tika intervēti arī protesta
- Page 9 and 10:
14 15Gadījumu analīzeIegūtie (no
- Page 11 and 12:
18 19Partiju apvienības „Vienot
- Page 13 and 14:
22 23Ir veikta darba autores izvēl
- Page 15:
26 27ievērojama saistība starp me
- Page 18 and 19:
32 33SABIEDRISKO POLITIKU ANALĪZEV
- Page 20 and 21:
36 37viedokļa, izvirzītie akredit
- Page 22 and 23:
40 41ieinteresēta, lai ārstēšan
- Page 24:
44 45Alternatīvo aprūpes veidu iz
- Page 27 and 28:
50 51RespondentsAEfektivitāteTehni
- Page 29 and 30:
54 55RespondentsCilvēkresursu piet
- Page 31 and 32:
58 59Izmantotā literatūraAbebe, T
- Page 33 and 34:
62 63Pētījuma gaitā tika identif
- Page 35 and 36:
66 67rindas. Kopā tika novēroti 5
- Page 37 and 38:
70 71nevis Madonas slimnīcā. Vidz
- Page 39 and 40: 74 75Privātā finansējuma piesais
- Page 41 and 42: 78 79virsotnes tas arī sasniegtu (
- Page 43 and 44: 82 83No pētījumā izmantoto gadī
- Page 45 and 46: 86 87KOMUNIKĀCIJA UN SABIEDRISKĀS
- Page 47 and 48: 90 91Sabiedrisko attiecību modeļu
- Page 49 and 50: 94 95iepriekšējos pētījumos par
- Page 51 and 52: 98 995. tabula. SA modeļi un komun
- Page 53 and 54: 102 103Dažādu zinātnes nozaru sp
- Page 55 and 56: 106 1071.2. Zinātnes komunikācija
- Page 57 and 58: 110 1114.1. Zinātnes komunikācija
- Page 59 and 60: 114 115Nākamais problēmu bloks, k
- Page 61 and 62: 118 119IevadsZināšanas ir kļuvu
- Page 63 and 64: 122 123interpretēti dati no šīs
- Page 65 and 66: 126 127Latvijas sabiedrisko attiec
- Page 67 and 68: 130 131Zināšanu pārneses klimats
- Page 69 and 70: 134 135par mazāk ietekmīgu. Lai g
- Page 71 and 72: 138 139Lai varētu precīzāk notei
- Page 73 and 74: 142 143Analizējot struktūrvienīb
- Page 75 and 76: 146 147Transformatīvās līderība
- Page 77 and 78: 150 151MetodePētījuma dalībnieki
- Page 79 and 80: 154 1553.tabula. Korelācijas koefi
- Page 81 and 82: 158 159Paulus, B.P., Larey, S.T., D
- Page 83 and 84: 162 163uzņēmuma dibināšanos ar
- Page 85 and 86: 166 167personīgajām iezīmēm kā
- Page 87 and 88: 170 171Volume 32, number 5, pp. 548
- Page 89: 174 175Izplūdušais PRISM algoritm
- Page 93 and 94: 182 183classifiers. Attribute-value
- Page 95 and 96: 186 187ir nedaudz uzlabojusies - ne