

a la physique de l'information - Lisa - Université d'Angers
a la physique de l'information - Lisa - Université d'Angers
a la physique de l'information - Lisa - Université d'Angers

Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
Author's personal copy<br />
3978 F. Chapeau-Blon<strong>de</strong>au, D. Rousseau / Physica A 388 (2009) 3969–3984<br />
A B<br />
total <strong>de</strong>scription length<br />
x 10 6<br />
1.5172<br />
1.5171<br />
1.517<br />
1.5169<br />
1.5168<br />
1.5167<br />
1.5166<br />
1.5165<br />
1.5164<br />
0 10 20 30 40 50 60 70 80 100 120 150 170<br />
number of bins K<br />
3<br />
2<br />
4<br />
probability <strong>de</strong>nsity<br />
0.4<br />
0.3<br />
0.2<br />
0.1<br />
0<br />
–4 –3 –2 –1 0 1 2 3 4 5 6<br />
signal amplitu<strong>de</strong><br />
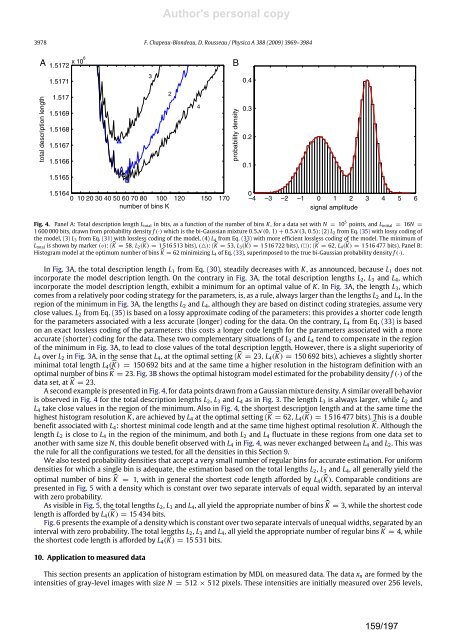
Fig. 4. Panel A: Total <strong>de</strong>scription length Ltotal in bits, as a function of the number of bins K , for a data set with N = 10 5 points, and Linitial = 16N =<br />
1 600 000 bits, drawn from probability <strong>de</strong>nsity f (·) which is the bi-Gaussian mixture 0.5N (0, 1) + 0.5N (3, 0.5): (2) L2 from Eq. (35) with lossy coding of<br />
the mo<strong>de</strong>l, (3) L3 from Eq. (31) with lossless coding of the mo<strong>de</strong>l, (4) L4 from Eq. (33) with more efficient lossless coding of the mo<strong>de</strong>l. The minimum of<br />
Ltotal is shown by marker (◦): ( K = 58, L2( K) = 1 516 513 bits), (△): ( K = 53, L3( K) = 1 516 722 bits), (): ( K = 62, L4( K) = 1 516 477 bits). Panel B:<br />
Histogram mo<strong>de</strong>l at the optimum number of bins K = 62 minimizing L4 of Eq. (33), superimposed to the true bi-Gaussian probability <strong>de</strong>nsity f (·).<br />
In Fig. 3A, the total <strong>de</strong>scription length L1 from Eq. (30), steadily <strong>de</strong>creases with K , as announced, because L1 does not<br />
incorporate the mo<strong>de</strong>l <strong>de</strong>scription length. On the contrary in Fig. 3A, the total <strong>de</strong>scription lengths L2, L3 and L4, which<br />
incorporate the mo<strong>de</strong>l <strong>de</strong>scription length, exhibit a minimum for an optimal value of K . In Fig. 3A, the length L3, which<br />
comes from a re<strong>la</strong>tively poor coding strategy for the parameters, is, as a rule, always <strong>la</strong>rger than the lengths L2 and L4. In the<br />
region of the minimum in Fig. 3A, the lengths L2 and L4, although they are based on distinct coding strategies, assume very<br />
close values. L2 from Eq. (35) is based on a lossy approximate coding of the parameters: this provi<strong>de</strong>s a shorter co<strong>de</strong> length<br />
for the parameters associated with a less accurate (longer) coding for the data. On the contrary, L4 from Eq. (33) is based<br />
on an exact lossless coding of the parameters: this costs a longer co<strong>de</strong> length for the parameters associated with a more<br />
accurate (shorter) coding for the data. These two complementary situations of L2 and L4 tend to compensate in the region<br />
of the minimum in Fig. 3A, to lead to close values of the total <strong>de</strong>scription length. However, there is a slight superiority of<br />
L4 over L2 in Fig. 3A, in the sense that L4, at the optimal setting ( K = 23, L4( K) = 150 692 bits), achieves a slightly shorter<br />
minimal total length L4( K) = 150 692 bits and at the same time a higher resolution in the histogram <strong>de</strong>finition with an<br />
optimal number of bins K = 23. Fig. 3B shows the optimal histogram mo<strong>de</strong>l estimated for the probability <strong>de</strong>nsity f (·) of the<br />
data set, at K = 23.<br />
A second example is presented in Fig. 4, for data points drawn from a Gaussian mixture <strong>de</strong>nsity. A simi<strong>la</strong>r overall behavior<br />
is observed in Fig. 4 for the total <strong>de</strong>scription lengths L2, L3 and L4 as in Fig. 3. The length L3 is always <strong>la</strong>rger, while L2 and<br />
L4 take close values in the region of the minimum. Also in Fig. 4, the shortest <strong>de</strong>scription length and at the same time the<br />
highest histogram resolution K , are achieved by L4 at the optimal setting ( K = 62, L4( K) = 1 516 477 bits). This is a double<br />
benefit associated with L4: shortest minimal co<strong>de</strong> length and at the same time highest optimal resolution K . Although the<br />
length L2 is close to L4 in the region of the minimum, and both L2 and L4 fluctuate in these regions from one data set to<br />
another with same size N, this double benefit observed with L4 in Fig. 4, was never exchanged between L4 and L2. This was<br />
the rule for all the configurations we tested, for all the <strong>de</strong>nsities in this Section 9.<br />
We also tested probability <strong>de</strong>nsities that accept a very small number of regu<strong>la</strong>r bins for accurate estimation. For uniform<br />
<strong>de</strong>nsities for which a single bin is a<strong>de</strong>quate, the estimation based on the total lengths L2, L3 and L4, all generally yield the<br />
optimal number of bins K = 1, with in general the shortest co<strong>de</strong> length affor<strong>de</strong>d by L4( K). Comparable conditions are<br />
presented in Fig. 5 with a <strong>de</strong>nsity which is constant over two separate intervals of equal width, separated by an interval<br />
with zero probability.<br />
As visible in Fig. 5, the total lengths L2, L3 and L4, all yield the appropriate number of bins K = 3, while the shortest co<strong>de</strong><br />
length is affor<strong>de</strong>d by L4( K) = 15 434 bits.<br />
Fig. 6 presents the example of a <strong>de</strong>nsity which is constant over two separate intervals of unequal widths, separated by an<br />
interval with zero probability. The total lengths L2, L3 and L4, all yield the appropriate number of regu<strong>la</strong>r bins K = 4, while<br />
the shortest co<strong>de</strong> length is affor<strong>de</strong>d by L4( K) = 15 531 bits.<br />
10. Application to measured data<br />
This section presents an application of histogram estimation by MDL on measured data. The data xn are formed by the<br />
intensities of gray-level images with size N = 512 × 512 pixels. These intensities are initially measured over 256 levels,<br />
159/197