Elektronika 2009-11.pdf - Instytut Systemów Elektronicznych
Elektronika 2009-11.pdf - Instytut Systemów Elektronicznych
Elektronika 2009-11.pdf - Instytut Systemów Elektronicznych

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
Summary<br />
The image set of recognition data, which has been used in<br />
order to determine in percentage figures the efficiency of<br />
a correct recognition of the size of stenoses in coronary arteries,<br />
included 16 different spatial reconstructions obtained<br />
for patients with heart disease (mostly ischemia). In this set,<br />
we considered image sequences of patients previously<br />
analysed at the stage of the grammar construction and the<br />
recognising analyser. In order to avoid analysing identical reconstructions<br />
we selected separate images occurring after<br />
slight positions rotation (different projection) the ones used<br />
originally (from spatial helical CT scans). The remaining images<br />
in the test data have been obtained for a new group of<br />
patients. The objective of an analysis of these data was to determine<br />
in percentage the efficiency of the correct recognition<br />
of artery stenosis and to determine their size with the use of<br />
the grammar introduced. The recognition of such stenoses,<br />
including the determination of their locations, lumens of the<br />
artery, and the types (concentric or eccentric), was conducted<br />
in such a way that while reasoning out the grammar for the<br />
graph representation of the coronary vascularization, particular<br />
edges of the graph determined the actual beginnings and<br />
ends of particular sections of coronary arteries. During the<br />
grammar reasoning and the course of the transform of embedding<br />
graph representations on the actual images, the corresponding<br />
sections of arteries were analysed with regard to<br />
the presence of potential stenoses in them. The method of<br />
this analysis also consisted in applying a context-free sequential<br />
grammar to detect stenoses in 2D coronarography<br />
images. Such a grammar has been defined in publications<br />
[7-8]. Applying such a grammar to analyse particular sections<br />
of arteries in the obtained spatial reconstructions turned out to<br />
be quite effective, as it allowed the unanimous On the image<br />
data tested, the efficiency of recognition amounted to 85%.<br />
The value of the efficiency of recognition is determined by the<br />
percentage fraction of the accurately recognized and measured<br />
vessel stenoses compared to the number of all images<br />
analyzed in the test. The recognition itself meant locating and<br />
defining the type of stenosis, e.g. concentric or eccentric.<br />
This work has been supported by the Ministry of Science and<br />
Higher Education, Republic of Poland, under project number<br />
N519 007 32/0978<br />
References<br />
[1] Ferrarini L. i in.: GAMEs: Growing and adaptive meshes for fully<br />
automatic shape modeling and analysis. Medical Image Analysis,<br />
11, 2007, 302-314.<br />
[2] Seghers D. i in.: Minimal shape and intensity cost path segmentation.<br />
IEEE Trans. on Medical Imaging, 26, 2007, 1115-<br />
1129.<br />
[3] Loeckx D. i in.: Temporal subtraction of thorax CR images using<br />
a statistical deformation model. IEEE Trans. on Medical Imaging,<br />
22, 2003, 1490-1504.<br />
[4] Higgins W.E. i in.: System for analyzing true three-dimensional<br />
angiograms. IEEE Trans. Med. Imag. 15, 1996, 377-385.<br />
[5] Skomorowski M.: A Syntactic-Statistical Approach to Recognition<br />
of Distorted Patterns. Jagiellonian University, Krakow, 2000.<br />
[6] Tadeusiewicz R., Flasiński M.: Pattern Recognition. Warsaw,<br />
1991.<br />
[7] Ogiela M. R., Tadeusiewicz R.: Modern Computational Intelligence<br />
Methods for the Interpretation of Medical Images.<br />
Springer-Verlag, Berlin Heidelberg, 2008.<br />
[8] Tadeusiewicz R., Ogiela M. R.: Medical Image Understanding<br />
Technology. Springer Verlag, Berlin-Heidelberg, 2004.<br />
Average individual classification probability function<br />
(Przeciętna indywidualna funkcja prawdopodobieństwa klasyfikacji)<br />
dr inż. MAREK LANDOWSKI 1,2 , prof. dr hab. inż. ANDRZEJ PIEGAT 2<br />
1 Quantitative Methods Institute, Szczecin Maritime University, Szczecin<br />
2 Faculty of Computer Science and Information Systems, West Pomeranian University of Technology, Szczecin<br />
In everyday life people use different words to make various<br />
mental calculations. Therefore the proper description of<br />
a word is a crucial problem. There are two types of models of<br />
linguistic concept: possibilistic model and probabilistic model.<br />
In the possibilistic theory models of linguistic concept are described<br />
by the membership function [1], whereas in probability<br />
theory models of linguistic concept are described by<br />
classification probability function [2,3]. Possibilistic models described<br />
by the membership function are mainly used in fuzzy<br />
control and in modeling input-output relation of an object like<br />
y = f(x 1 , x 2 , …, x n ). Probabilistic models describing linguistic<br />
concepts by classification probability function seem to perform<br />
better in automatic thinking and decision making theory. Fuzzy<br />
sets theory and probability theory are complementary and not<br />
exclusive theories. These theories can work together though<br />
they model semantic concepts differently [4].<br />
The article focuses on probabilistic model of linguistic concept<br />
[5], in particular on finding the average individual classification<br />
probability function. According to the authors’ knowledge<br />
average individual classification probability function are<br />
the novelty in the word literature.<br />
In the article there is the following order. Firstly the two<br />
kinds of models of linguistics concepts are presented. Next<br />
the interpretation is given as well as the methods of identification<br />
average individual classification probability function.<br />
Then the features of average individual classification probability<br />
function received from the experiments are introduced.<br />
Finally the conclusions are presented.<br />
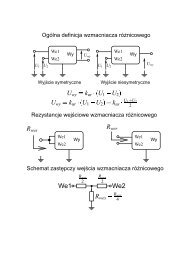
Probabilistic models of linguistic concept<br />
from the group of people (population)<br />
We distinguish two kinds of models of linguistic concept received<br />
from the group of people (population):<br />
• group (population) model,<br />
• average, individual model of an average person of the group.<br />
12 ELEKTRONIKA 11/<strong>2009</strong>