- Seite 2 und 3: 1 Konventionelle Kopplungen 1.1 Ein
- Seite 4 und 5: Parallele Rechentechnik Die paralle
- Seite 6 und 7: Zur Lösung des zeitabhängigen Ver
- Seite 8 und 9: leichter an diesem überschaubaren
- Seite 10 und 11: V = ( i j) Mengenschreibweise: ⎧
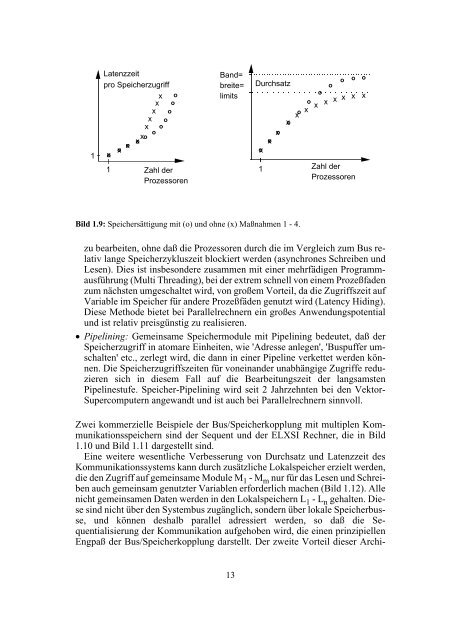
- Seite 12 und 13: 1 x relativer Durchsatz x x x x x x
- Seite 16 und 17: P1 L1 Lokale Busse und Speicher P2
- Seite 18 und 19: MEM MEM . . . MEM Memory Bus Cache
- Seite 20 und 21: 1.3.3 Die Grenzen der Bus/Speicherk
- Seite 22 und 23: P1 P2 ... Pn C1 C2 ... Cn M1 M2 ...
- Seite 24 und 25: 1.6 Skalierbarkeit von Verbindungss
- Seite 26 und 27: Korrespondierend zu der Tatsache, d
- Seite 28 und 29: Programmiermodell gemeinsame Variab
- Seite 30 und 31: Programmiermodell (Benutzersicht) g
- Seite 32 und 33: (Knoten, Teilnehmer) gleich weit vo
- Seite 34 und 35: und der IBM RP3-Rechner [Pfister85]
- Seite 36 und 37: Pi Ai Kanal Netz Kanal Aj Pj beobac
- Seite 38 und 39: mehrerer Prozessoren auf dieselbe V
- Seite 40 und 41: P1 M1 M1 M1 D1 P2 P1 M1 M2 D2 M1 .
- Seite 42 und 43: Prozessor i Prozeß b Prozeß a Pro
- Seite 44 und 45: nere Netze mit je n Eingängen nur
- Seite 46 und 47: a) b) Bild 2.16: Rekursiv aufgebaut
- Seite 48 und 49: auch Prozeßsynchronisation, z.B. u
- Seite 50 und 51: eines normalen Multi-/Broadcasts zu
- Seite 52 und 53: Bezeichnung Typ Vorher Nachher allg
- Seite 54 und 55: s - mal Gl. 2.6: S < e + e + … +
- Seite 56 und 57: Ist die i. Teilmenge vom Punkt-zu-P
- Seite 58 und 59: Gl. 2.15: ∧ U j = i j + 1 . An di
- Seite 60 und 61: Dies stellt den Broadcast vom 1. Se
- Seite 62 und 63: 2.5.2 Verbindungsart Grundsätzlich
- Seite 64 und 65:
Dies ist z.B. bei allen systolische
- Seite 66 und 67:
Ziel- und Herkunftsadresse bestehen
- Seite 68 und 69:
echnernetzen wird ebenfalls Store-a
- Seite 70 und 71:
indungskanälen und die Passanten d
- Seite 72 und 73:
2.6.5 Store-and-Forward Routing Bei
- Seite 74 und 75:
Paket= position Empfänger Knoten i
- Seite 76 und 77:
3 Statische Verbindungsnetzwerke 3.
- Seite 78 und 79:
Ring Sehnenring 2D-Gitter .. . . ..
- Seite 80 und 81:
Moore-Graph für N=10 (= Petersen-G
- Seite 82 und 83:
Def. 3.3: Ein Graph heißt knotensy
- Seite 84 und 85:
ein genaueres Maß zur Hand haben.
- Seite 86 und 87:
Knotenkonnektivität Der Knotenzusa
- Seite 88 und 89:
Aus verkabelungstechnischen und üb
- Seite 90 und 91:
wrap-around-Verbindungen diese Eige
- Seite 92 und 93:
3.6.6 De Bruijn-Topologie De Bruijn
- Seite 94 und 95:
mit den Knoten N 0 ' = a n-1 ,..,a
- Seite 96 und 97:
terschiedlicher Sequenzen, die durc
- Seite 98 und 99:
Für die Emulation wird die Topolog
- Seite 100 und 101:
3.9 BIBD-Graphen Eine Möglichkeit,
- Seite 102 und 103:
fisch ist. Die gebräuchlichsten de
- Seite 104 und 105:
nem verkehrsreichen Knoten warten w
- Seite 106 und 107:
daß bei minimalem, adaptivem Routi
- Seite 108 und 109:
Knoten 1 Knoten 2 Knoten 3 Transfer
- Seite 110 und 111:
Satz 3.2: Solange in einem Netz kei
- Seite 112 und 113:
schritte, die ein Paket im Netz zur
- Seite 114 und 115:
mungsfreiheit: Gl. 3.11: k np ( - 1
- Seite 116 und 117:
wird die benötigte Pufferklassenza
- Seite 118 und 119:
Dally und Seitz [Dally87] zeigten s
- Seite 120 und 121:
Sobald ein Sendekanal für ein Pake
- Seite 122 und 123:
1 2 1 2 a) 4 3 4 3 Nordost Ostsüd
- Seite 124 und 125:
n-dimensionales Negative First-Verf
- Seite 126 und 127:
3 10 17 2 44 45 9 4 37 30 38 16 31
- Seite 128 und 129:
3.11.2 Gruppentheorie für Cayley-G
- Seite 130 und 131:
Aufgrund der Tatsache, daß Permuta
- Seite 132 und 133:
Verkettungen von Permutationen Die
- Seite 134 und 135:
das Resultat p ° q = ⎛1 2 3 4⎞
- Seite 136 und 137:
Satz 3.12: Jede Permutationsgruppe
- Seite 138 und 139:
Der Satz 3.15 sagt, daß es bei ein
- Seite 140 und 141:
1234 p1 1324 p2 2143 3142 2413 p1 =
- Seite 142 und 143:
führen kann, nämlich auf den Pfad
- Seite 144 und 145:
Wenn die Voraussetzung der Hierarch
- Seite 146 und 147:
A1 e p1 p2 A2 p4 p5 A3 p3 Bild 3.33
- Seite 148 und 149:
Ebenso unterschiedlich wie die Stuf
- Seite 150 und 151:
4.3.1 Perfect Shuffle-Permutation D
- Seite 152 und 153:
Die von der schnellen Fouriertransf
- Seite 154 und 155:
Je nach Parameter k ergeben die Sub
- Seite 156 und 157:
Gl. 4.9: I=(i n i n-1 ,...,i 1 ), b
- Seite 158 und 159:
Satz 4.5: = , Satz 4.6: = , sowie e
- Seite 160 und 161:
netzwerken nur 8 statt der 16 mögl
- Seite 162 und 163:
(i 1 = 0 oder i 1 = 1), muß der Sc
- Seite 164 und 165:
000 001 010 011 100 101 110 111 000
- Seite 166 und 167:
0000 0001 0010 0011 0100 0101 0110
- Seite 168 und 169:
vorletzten Stufe kollidieren würde
- Seite 170 und 171:
1,1 2,1 3,1 4,1 1,2 2,2 3,2 4,2 1,3
- Seite 172 und 173:
4.5.5 Vergleich Indirect Binary n-C
- Seite 174 und 175:
0 1 2 3 4 5 6 7 0 1 2 3 4 5 6 7 0 2
- Seite 176 und 177:
Routing im Generalized Cube Die mat
- Seite 178 und 179:
In der 3. Stufe wird das Ziel bis a
- Seite 180 und 181:
4.5.10 Banyan-Butterfly Das erste "
- Seite 182 und 183:
Stufe das MSB oder LSB auszuwerten,
- Seite 184 und 185:
iiii oiii ooii Bild 4.40: Funktion
- Seite 186 und 187:
tionaler oder topologischer Äquiva
- Seite 188 und 189:
4.6.5 Transformationen von logN-Net
- Seite 190 und 191:
Gl. 4.35: ( F) ( F) ( F) ( F) ( F)
- Seite 192 und 193:
Flip 000, 0 000, 1 000, 2 000, 3 00
- Seite 194 und 195:
terscheiden sich von den Graphen mi
- Seite 196 und 197:
4.47 sind zwei Beispiele regelmäß
- Seite 198 und 199:
Bild 4.52: Einziger Banyan der Grö
- Seite 200 und 201:
E i n g ä n g e A u s g ä n g e B
- Seite 202 und 203:
Die nach Bild 4.59b entstandene Top
- Seite 204 und 205:
Ersetzt man in dieser Topologie die
- Seite 206 und 207:
Der (2,2,4)-SW-Banyan entsteht durc
- Seite 208 und 209:
usw. Bei dem gewählten Numerierung
- Seite 210 und 211:
000 001 010 011 100 101 110 111 Kno
- Seite 212 und 213:
Die graphische Repräsentation des
- Seite 214 und 215:
gur auf einem zweiten Kegelstumpf s
- Seite 216 und 217:
was dem Wert (011) in Zweierkomplem
- Seite 218 und 219:
estimmt. Man kann das Netz auch als
- Seite 220 und 221:
a) b) c) d) Bild 4.79: Konstruktion
- Seite 222 und 223:
• um 2 i mod N Positionen nach un
- Seite 224 und 225:
4.10 Das Clos-Netz 4.10.1 Einleitun
- Seite 226 und 227:
4.10.3 Die allgemeine Perfect Shuff
- Seite 228 und 229:
N=4*3 Basis 4 00 01 E 02 i 10 n 11
- Seite 230 und 231:
ein freier Weg vom Sender zum Empf
- Seite 232 und 233:
ere Möglichkeiten, wie z.B. die Ma
- Seite 234 und 235:
ter der Ausgangsstufe widerspiegelt
- Seite 236 und 237:
stufe und die Kanten des Graphen re
- Seite 238 und 239:
1 2 9 7 6 8 8 4 5 10 Bild 4.89: 1.
- Seite 240 und 241:
und Ausgangsstufe verbinden, an den
- Seite 242 und 243:
(0 7 6 5 4 3 2 1), für die die Weg
- Seite 244 und 245:
4.11.4 Benes-ähnliche Netze Es gib
- Seite 246 und 247:
Doppeltes Omega-Netz Bislang ist di
- Seite 248 und 249:
nalen Raumes Kreuzschienenverteiler
- Seite 250 und 251:
5 Beispiele kommerzieller Verbindun
- Seite 252 und 253:
z y x . . . . . . . .. . . . . . .
- Seite 254 und 255:
normaler Multi-/Broadcast . . . Kno
- Seite 256 und 257:
Betrachtet man einen Prozessor näh
- Seite 258 und 259:
othek erfordert mehr Software-Zusat
- Seite 260 und 261:
5.1.6 Synchronisationsmechanismen I
- Seite 262 und 263:
vorher: lokales Tausch Register = x
- Seite 264 und 265:
1993 erschien die SP1 als das erste
- Seite 266 und 267:
zutauschen. Die andere Seite der Ne
- Seite 268 und 269:
8 Flow Control CRC Check Receiver 1
- Seite 270 und 271:
1 2 3 16 . . . 1 2 3 16 . . . 1 2 3
- Seite 272 und 273:
5.2.4 Lokalität in der Netzstruktu
- Seite 274 und 275:
nicht blockierende Senden dargestel
- Seite 276 und 277:
1.1 1.2 1.3 1.4 I/O 2.1 2.2 2.3 2.4
- Seite 278 und 279:
Das Verbindungsnetz innerhalb eines
- Seite 280 und 281:
tieller Codes steht das "Applicatio
- Seite 282 und 283:
. . . . . . . . . . . . . . . . . .
- Seite 284 und 285:
In Bild 5.26 findet eine Kommunikat
- Seite 286 und 287:
ist bei dieser Methode um 2 Kopiero
- Seite 288 und 289:
Der Bedienrechner ist neben seiner
- Seite 290 und 291:
5.5.5 Verbindungsnetzwerk Das Verbi