- Seite 1 und 2:
Forschungseinrichtung Satellitengeo
- Seite 3 und 4:
Kurzfassung Geodätische Messsystem
- Seite 5 und 6:
Abstract Geodetic observatories for
- Seite 7:
Erklärung Ich erkläre an Eides st
- Seite 11 und 12:
Inhaltsverzeichnis 1 Einführung 1
- Seite 13 und 14:
INHALTSVERZEICHNIS xiii 5 Verbesser
- Seite 15 und 16:
INHALTSVERZEICHNIS xv Q Testszenari
- Seite 17 und 18:
Kapitel 1 Einführung Schwerpunkt d
- Seite 19 und 20:
1.1 BEGRÜNDUNG 3 • GPS : Speziel
- Seite 21 und 22:
1.2 ZIELSETZUNG 5 epochenbezogen si
- Seite 23 und 24:
1.4 EINGESETZTE ARBEITSTECHNIKEN 7
- Seite 25 und 26:
1.4 EINGESETZTE ARBEITSTECHNIKEN 9
- Seite 27 und 28:
1.4 EINGESETZTE ARBEITSTECHNIKEN 11
- Seite 29 und 30:
1.4 EINGESETZTE ARBEITSTECHNIKEN 13
- Seite 31 und 32:
1.5 AUFBAU DER ARBEIT 15 werden. Un
- Seite 33 und 34:
1.5 AUFBAU DER ARBEIT 17 Zum Abschl
- Seite 35 und 36:
Kapitel 2 Analyse Schwerpunkt des K
- Seite 37 und 38:
2.1 BEGRIFFSDEFINITIONEN 21 einfach
- Seite 39 und 40:
2.2 INFORMATIONSVERARBEITENDE EINHE
- Seite 41 und 42:
2.2 INFORMATIONSVERARBEITENDE EINHE
- Seite 43 und 44:
2.3 DIE INTERNE WISSENSREPRÄSENTAT
- Seite 45 und 46:
2.3 DIE INTERNE WISSENSREPRÄSENTAT
- Seite 47 und 48:
2.4 SCHLUSSFOLGERUNGEN 31 Zustandsk
- Seite 49 und 50:
2.4 SCHLUSSFOLGERUNGEN 33 Beispiel
- Seite 51 und 52:
2.4 SCHLUSSFOLGERUNGEN 35 2. Verbes
- Seite 53 und 54:
Kapitel 3 Middleware als elementare
- Seite 55 und 56:
3.2 THEORETISCHE GRUNDLAGEN 39 3.2.
- Seite 57 und 58:
3.2 THEORETISCHE GRUNDLAGEN 41 (= Z
- Seite 59 und 60:
3.2 THEORETISCHE GRUNDLAGEN 43 Abbi
- Seite 61 und 62:
3.2 THEORETISCHE GRUNDLAGEN 45 Des
- Seite 63 und 64:
3.2 THEORETISCHE GRUNDLAGEN 47 und
- Seite 65 und 66:
3.2 THEORETISCHE GRUNDLAGEN 49 Stub
- Seite 67 und 68:
3.2 THEORETISCHE GRUNDLAGEN 51 Abbi
- Seite 69 und 70:
3.2 THEORETISCHE GRUNDLAGEN 53 Impl
- Seite 71 und 72:
3.2 THEORETISCHE GRUNDLAGEN 55 •
- Seite 73 und 74:
3.3 UMSETZUNGSDESIGN: CORBA FILE TR
- Seite 75 und 76:
3.3 UMSETZUNGSDESIGN: CORBA FILE TR
- Seite 77 und 78:
3.3 UMSETZUNGSDESIGN: CORBA FILE TR
- Seite 79 und 80:
3.3 UMSETZUNGSDESIGN: CORBA FILE TR
- Seite 81 und 82:
3.3 UMSETZUNGSDESIGN: CORBA FILE TR
- Seite 83 und 84:
3.3 UMSETZUNGSDESIGN: CORBA FILE TR
- Seite 85 und 86:
3.3 UMSETZUNGSDESIGN: CORBA FILE TR
- Seite 87 und 88:
3.3 UMSETZUNGSDESIGN: CORBA FILE TR
- Seite 89 und 90:
3.4 EINE WEITERFÜHRENDE IDEE: DER
- Seite 91 und 92:
3.5 ERSTE ERGEBNISSE 75 wenn man nu
- Seite 93 und 94:
3.5 ERSTE ERGEBNISSE 77 3.5.3 Die T
- Seite 95 und 96:
3.5 ERSTE ERGEBNISSE 79 Abbildung 3
- Seite 97 und 98:
3.6 ZUSAMMENFASSUNG 81 Betrachtet m
- Seite 99 und 100:
Kapitel 4 Die Verbesserung der Dien
- Seite 101 und 102:
4.2 THEORETISCHE GRUNDLAGEN 85 Da d
- Seite 103 und 104:
4.2 THEORETISCHE GRUNDLAGEN 87 Der
- Seite 105 und 106: 4.2 THEORETISCHE GRUNDLAGEN 89 Der
- Seite 107 und 108: 4.2 THEORETISCHE GRUNDLAGEN 91 1. N
- Seite 109 und 110: 4.2 THEORETISCHE GRUNDLAGEN 93 Akti
- Seite 111 und 112: 4.2 THEORETISCHE GRUNDLAGEN 95 Serv
- Seite 113 und 114: 4.3 UMSETZUNGSDESIGN: EXTENDED CORB
- Seite 115 und 116: 4.3 UMSETZUNGSDESIGN: EXTENDED CORB
- Seite 117 und 118: 4.3 UMSETZUNGSDESIGN: EXTENDED CORB
- Seite 119 und 120: 4.3 UMSETZUNGSDESIGN: EXTENDED CORB
- Seite 121 und 122: 4.3 UMSETZUNGSDESIGN: EXTENDED CORB
- Seite 123 und 124: 4.3 UMSETZUNGSDESIGN: EXTENDED CORB
- Seite 125 und 126: 4.3 UMSETZUNGSDESIGN: EXTENDED CORB
- Seite 127 und 128: 4.3 UMSETZUNGSDESIGN: EXTENDED CORB
- Seite 129 und 130: 4.4 EINE WEITERFÜHRENDE IDEE: DER
- Seite 131 und 132: 4.5 ERGEBNISSE 115 und werden durch
- Seite 133 und 134: 4.5 ERGEBNISSE 117 Die dort gegeben
- Seite 135 und 136: 4.5 ERGEBNISSE 119 im Script (z.B.
- Seite 137 und 138: 4.5 ERGEBNISSE 121 163454084 2004.0
- Seite 139 und 140: 4.5 ERGEBNISSE 123 Aufgrund der auf
- Seite 141 und 142: 4.5 ERGEBNISSE 125 Im Wesentlichen
- Seite 143 und 144: 4.6 ZUSAMMENFASSUNG 127 IIOP -Clien
- Seite 145 und 146: Kapitel 5 Verbesserung der Datendar
- Seite 147 und 148: 5.2 THEORETISCHE GRUNDLAGEN 131 lic
- Seite 149 und 150: 5.2 THEORETISCHE GRUNDLAGEN 133 Beg
- Seite 151 und 152: 5.2 THEORETISCHE GRUNDLAGEN 135 Im
- Seite 153 und 154: 5.2 THEORETISCHE GRUNDLAGEN 137 das
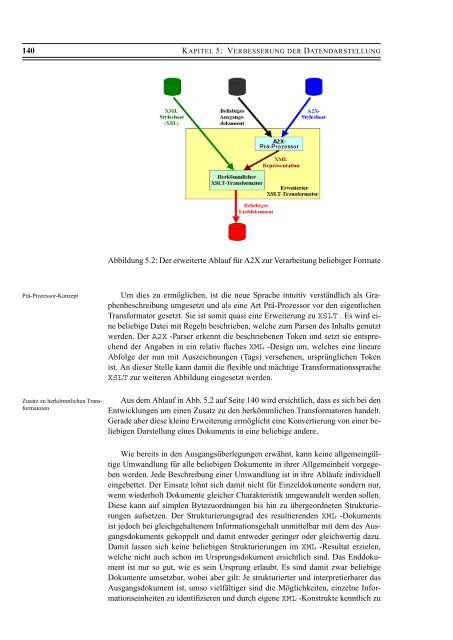
- Seite 155: 5.3 SPRACHDESIGN: ANYTHING TO XML (
- Seite 159 und 160: 5.3 SPRACHDESIGN: ANYTHING TO XML (
- Seite 161 und 162: 5.3 SPRACHDESIGN: ANYTHING TO XML (
- Seite 163 und 164: 5.3 SPRACHDESIGN: ANYTHING TO XML (
- Seite 165 und 166: 5.3 SPRACHDESIGN: ANYTHING TO XML (
- Seite 167 und 168: 5.4 ERGEBNISSE 151 A2X füllt damit
- Seite 169 und 170: 5.5 ZUSAMMENFASSUNG 153 tische Rege
- Seite 171 und 172: Kapitel 6 Die Verbesserung des Date
- Seite 173 und 174: 6.2 THEORETISCHE GRUNDLAGEN 157 an.
- Seite 175 und 176: 6.2 THEORETISCHE GRUNDLAGEN 159 ECF
- Seite 177 und 178: 6.3 UMSETZUNGSDESIGN: WETTZELL DATA
- Seite 179 und 180: 6.3 UMSETZUNGSDESIGN: WETTZELL DATA
- Seite 181 und 182: 6.3 UMSETZUNGSDESIGN: WETTZELL DATA
- Seite 183 und 184: 6.3 UMSETZUNGSDESIGN: WETTZELL DATA
- Seite 185 und 186: 6.4 ERSTE ERFAHRUNGEN 169 cher Head
- Seite 187 und 188: 6.5 ZUSAMMENFASSUNG 171 Alle Planun
- Seite 189 und 190: Kapitel 7 Strukturelle Verbesserung
- Seite 191 und 192: 7.2 THEORETISCHE GRUNDLAGEN 175 7.2
- Seite 193 und 194: 7.2 THEORETISCHE GRUNDLAGEN 177 der
- Seite 195 und 196: 7.3 DIE VISION FÜR EIN WETTZELL DA
- Seite 197 und 198: 7.3 DIE VISION FÜR EIN WETTZELL DA
- Seite 199 und 200: 7.3 DIE VISION FÜR EIN WETTZELL DA
- Seite 201 und 202: 7.3 DIE VISION FÜR EIN WETTZELL DA
- Seite 203 und 204: 7.3 DIE VISION FÜR EIN WETTZELL DA
- Seite 205 und 206: 7.4 ERSTE VERSUCHE 189 Zur Realisie
- Seite 207 und 208:
7.5 ZUSAMMENFASSUNG 191 der Umsetzu
- Seite 209 und 210:
Kapitel 8 Überleitung Schwerpunkt
- Seite 211 und 212:
8.1 ZUSAMMENFASSUNG 195 Middleware
- Seite 213 und 214:
8.2 BEWERTUNG 197 chisch angeordnet
- Seite 215 und 216:
8.2 BEWERTUNG 199 nagement sollten
- Seite 217 und 218:
8.4 FAZIT 201 erkannt werden. Zu di
- Seite 219 und 220:
Kapitel 9 Danksagung Am Gelingen de
- Seite 221 und 222:
Anhang A Graphisches Logbuch der We
- Seite 223 und 224:
207
- Seite 225 und 226:
Anhang B Verschiedene Middlewarelö
- Seite 227 und 228:
B.2 MESSAGE PASSING INTERFACE (MPI)
- Seite 229 und 230:
B.4 OPEN DATABASE CONNECTIVITY (ODB
- Seite 231 und 232:
B.5 DISTRIBUTED COMPUTING ENVIRONME
- Seite 233 und 234:
B.7 COMPONENT OBJECT MODEL (COM), D
- Seite 235 und 236:
B.8 JAVA, JAVA BEANS, ENTERPRISE JA
- Seite 237 und 238:
B.9 WEB-SERVICES 221 Gründe gegen
- Seite 239 und 240:
Anhang C CORBA-Implementierungen im
- Seite 241 und 242:
225
- Seite 243 und 244:
Anhang D Schnittstellendefinition i
- Seite 245 und 246:
}; }; // > Return: unsigned short -
- Seite 247 und 248:
Anhang E Ergebnisse lokaler Messung
- Seite 249 und 250:
233
- Seite 251 und 252:
235
- Seite 253 und 254:
237
- Seite 255 und 256:
239
- Seite 257 und 258:
241
- Seite 259 und 260:
Anhang F Klassendiagramme zum ECFT
- Seite 261 und 262:
245
- Seite 263 und 264:
Anhang G Beispiel eines Sequenzdiag
- Seite 265 und 266:
Anhang H Die GPS-Permanentstation i
- Seite 267 und 268:
Anhang I Snapshot zur Übertragungs
- Seite 269 und 270:
Anhang J Ergebnisse der Messungen i
- Seite 271 und 272:
J.1 CONCEPCIÓN/CHILE 255
- Seite 273 und 274:
J.1 CONCEPCIÓN/CHILE 257
- Seite 275 und 276:
J.2 HELGOLAND/GERMANY 259 J.2 Helgo
- Seite 277 und 278:
J.2 HELGOLAND/GERMANY 261
- Seite 279 und 280:
J.2 HELGOLAND/GERMANY 263
- Seite 281 und 282:
J.2 HELGOLAND/GERMANY 265 (Auszug a
- Seite 283 und 284:
J.3 LHASA/TIBET 267 J.3 Lhasa/Tibet
- Seite 285 und 286:
J.3 LHASA/TIBET 269
- Seite 287 und 288:
J.3 LHASA/TIBET 271
- Seite 289 und 290:
J.4 REYKJAVIK/ICELAND 273
- Seite 291 und 292:
J.4 REYKJAVIK/ICELAND 275
- Seite 293 und 294:
Anhang K Sprachdokumentation A2X (A
- Seite 295 und 296:
279
- Seite 297 und 298:
281
- Seite 299 und 300:
283
- Seite 301 und 302:
285
- Seite 303 und 304:
287
- Seite 305 und 306:
289
- Seite 307 und 308:
291
- Seite 309 und 310:
293
- Seite 311 und 312:
295
- Seite 313 und 314:
297
- Seite 315 und 316:
299
- Seite 317 und 318:
301
- Seite 319 und 320:
303
- Seite 321 und 322:
Anhang L Schema-Definition zu A2X (
- Seite 323 und 324:
- Seite 325 und 326:
- Seite 327 und 328:
311
- Seite 329 und 330:
Anhang M Beispiel einer A2X-Beschre
- Seite 331 und 332:
M.1 DIE FORMATBESCHREIBUNG 315
- Seite 333 und 334:
M.1 DIE FORMATBESCHREIBUNG 317
- Seite 335 und 336:
M.1 DIE FORMATBESCHREIBUNG 319
- Seite 337 und 338:
M.2 SCHEMATISCHE DARSTELLUNG EINER
- Seite 339 und 340:
M.3 GRAPHISCHE FORM EINER A2X-BESCH
- Seite 341 und 342:
M.4 XML-SCHREIBWEISE DER A2X-UMSETZ
- Seite 343 und 344:
M.4 XML-SCHREIBWEISE DER A2X-UMSETZ
- Seite 345 und 346:
M.4 XML-SCHREIBWEISE DER A2X-UMSETZ
- Seite 347 und 348:
M.5 DER AUFBAU DER IN XML-GEWANDELT
- Seite 349 und 350:
Anhang N Indeenskizze eines Bereche
- Seite 351 und 352:
2. Konstanten: Es existieren Konsta
- Seite 353 und 354:
WHILE-Programms nachbilden können,
- Seite 355 und 356:
Anhang O Erweiterte Schnittstellend
- Seite 357 und 358:
}; // > Parameter: inout CFTFILE SC
- Seite 359 und 360:
}; }; // > Class: WDMSInterface < /
- Seite 361 und 362:
Anhang P Die Headerdateien der DLL
- Seite 363 und 364:
P.2 HEADERDATEI FÜR C 347 unsigned
- Seite 365 und 366:
Anhang Q Testszenario einer Vererbu
- Seite 367 und 368:
Q.2 SERVERCODE ZUM VERERBUNGSTEST 3
- Seite 369 und 370:
Q.3 CLIENTCODE ZUM VERERBUNGSTEST 3
- Seite 371 und 372:
Abbildungsverzeichnis 1.1 Eingliede
- Seite 373 und 374:
Tabellenverzeichnis 3.1 CORBA Produ
- Seite 375 und 376:
Abkürzungsverzeichnis A2X Anything
- Seite 377 und 378:
ABKÜRZUNGSVERZEICHNIS 361 IT Infor
- Seite 379 und 380:
ABKÜRZUNGSVERZEICHNIS 363 WAN Wide
- Seite 381 und 382:
Literaturverzeichnis [ABI02] Abie,
- Seite 383 und 384:
LITERATURVERZEICHNIS 367 [KLAR95] K
- Seite 385 und 386:
LITERATURVERZEICHNIS 369 [OTH04] Ot
- Seite 387 und 388:
Index Asynchronous Methode Invocati
- Seite 389 und 390:
INDEX 373 168, 170, 196 Document Ty
- Seite 391 und 392:
INDEX 375 MTS(Microsoft Transaction
- Seite 393:
INDEX 377 User Datagram Protocol, s