

A generic framework for Arabic to English machine ... - Acsu Buffalo
A generic framework for Arabic to English machine ... - Acsu Buffalo
A generic framework for Arabic to English machine ... - Acsu Buffalo

Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
5.4. DESIGN OF EVALUATION CRITERIA<br />
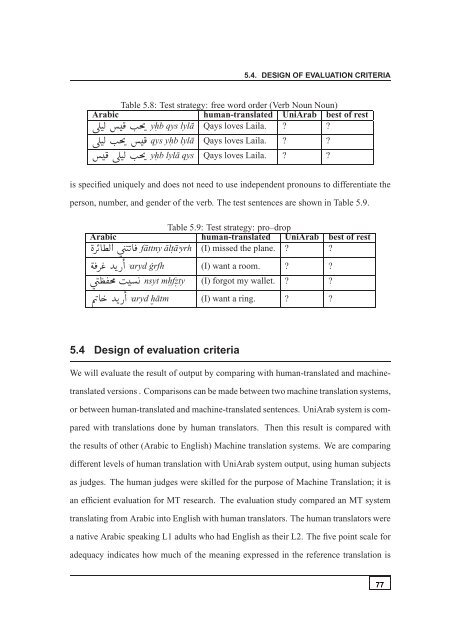
Table 5.8: Test strategy: free word order (Verb Noun Noun)<br />
<strong>Arabic</strong> human-translated UniArab best of rest<br />
yh. b qys lylā Qays loves Laila. ? ?<br />
qys yh. b lylā Qays loves Laila. ? ?<br />
yh. b lylā qys Qays loves Laila. ? ?<br />
is specified uniquely and does not need <strong>to</strong> use independent pronouns <strong>to</strong> differentiate the<br />
person, number, and gender of the verb. The test sentences are shown in Table 5.9.<br />
Table 5.9: Test strategy: pro–drop<br />
<strong>Arabic</strong> human-translated UniArab best of rest<br />
<br />
fāttny ālt.ā֓yrh (I) missed the plane. ? ?<br />
֓aryd ˙grfh (I) want a room. ? ?<br />
<br />
nsyt mh. fz . ty (I) <strong>for</strong>got my wallet. ? ?<br />
֓aryd hātm (I) want a ring. ? ?<br />
˘<br />
5.4 Design of evaluation criteria<br />
We will evaluate the result of output by comparing with human-translated and <strong>machine</strong>-<br />
translated versions . Comparisons can be made between two <strong>machine</strong> translation systems,<br />
or between human-translated and <strong>machine</strong>-translated sentences. UniArab system is com-<br />
pared with translations done by human transla<strong>to</strong>rs. Then this result is compared with<br />
the results of other (<strong>Arabic</strong> <strong>to</strong> <strong>English</strong>) Machine translation systems. We are comparing<br />
different levels of human translation with UniArab system output, using human subjects<br />
as judges. The human judges were skilled <strong>for</strong> the purpose of Machine Translation; it is<br />
an efficient evaluation <strong>for</strong> MT research. The evaluation study compared an MT system<br />
translating from <strong>Arabic</strong> in<strong>to</strong> <strong>English</strong> with human transla<strong>to</strong>rs. The human transla<strong>to</strong>rs were<br />
a native <strong>Arabic</strong> speaking L1 adults who had <strong>English</strong> as their L2. The five point scale <strong>for</strong><br />
adequacy indicates how much of the meaning expressed in the reference translation is<br />
77













