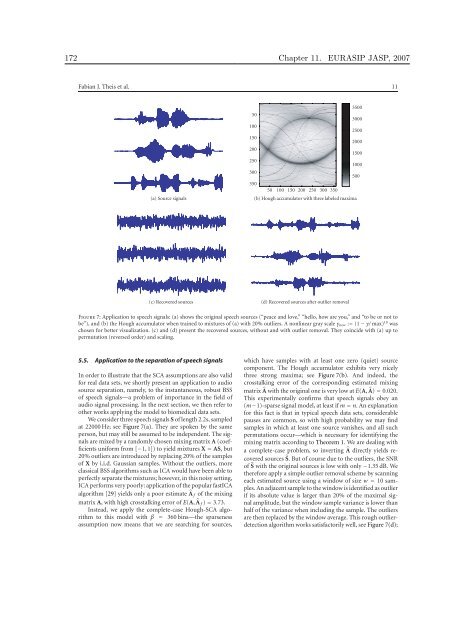
172 Chapter 11. EURASIP JASP, 2007 Fabian J. Theis et al. 11 (a) Source signals 50 100 150 200 250 300 350 50 100 150 200 250 300 350 (b) Hough accumulator with three labeled maxima (c) Recovered sources (d) Recovered sources after outlier removal Figure 7: Application to speech signals: (a) shows the orig<strong>in</strong>al speech sources (“peace and love,” “hello, how are you,” and “to be or not to be”), and (b) the Hough accumulator when tra<strong>in</strong>ed to mixtures of (a) with 20% outliers. A nonl<strong>in</strong>ear gray scale γnew := (1 − γ/ max) 10 was chosen for better visualization. (c) and (d) present the recovered sources, without and with outlier removal. They co<strong>in</strong>cide with (a) up to permutation (reversed order) and scal<strong>in</strong>g. 5.5. Application to the separation of speech signals In order to illustrate that the SCA assumptions are also valid for real data sets, we shortly present an application to audio source separation, namely, to the <strong>in</strong>stantaneous, robust BSS of speech signals—a problem of importance <strong>in</strong> the field of audio signal process<strong>in</strong>g. In the next section, we then refer to other works apply<strong>in</strong>g the model to biomedical data sets. We consider three speech signals S of length 2.2s, sampled at 22000 Hz; see Figure 7(a). They are spoken by the same person, but may still be assumed to be <strong>in</strong>dependent. The signals are mixed by a randomly chosen mix<strong>in</strong>g matrix A (coefficients uniform from [−1, 1]) to yield mixtures X = AS, but 20% outliers are <strong>in</strong>troduced by replac<strong>in</strong>g 20% of the samples of X by i.i.d. Gaussian samples. Without the outliers, more classical BSS algorithms such as ICA would have been able to perfectly separate the mixtures; however, <strong>in</strong> this noisy sett<strong>in</strong>g, ICA performs very poorly: application of the popular fastICA algorithm [29] yields only a poor estimate �A f of the mix<strong>in</strong>g matrix A, with high crosstalk<strong>in</strong>g error of E(A, �A f ) = 3.73. Instead, we apply the complete-case Hough-SCA algorithm to this model with β = 360 b<strong>in</strong>s—the sparseness assumption now means that we are search<strong>in</strong>g for sources, 3500 3000 2500 2000 1500 1000 which have samples with at least one zero (quiet) source component. The Hough accumulator exhibits very nicely three strong maxima; see Figure 7(b). And <strong>in</strong>deed, the crosstalk<strong>in</strong>g error of the correspond<strong>in</strong>g estimated mix<strong>in</strong>g matrix �A with the orig<strong>in</strong>al one is very low at E(A, �A) = 0.020. This experimentally confirms that speech signals obey an (m−1)-sparse signal model, at least if m = n. An explanation for this fact is that <strong>in</strong> typical speech data sets, considerable pauses are common, so with high probability we may f<strong>in</strong>d samples <strong>in</strong> which at least one source vanishes, and all such permutations occur—which is necessary for identify<strong>in</strong>g the mix<strong>in</strong>g matrix accord<strong>in</strong>g to Theorem 1. We are deal<strong>in</strong>g with a complete-case problem, so <strong>in</strong>vert<strong>in</strong>g �A directly yields recovered sources �S. But of course due to the outliers, the SNR of �S with the orig<strong>in</strong>al sources is low with only −1.35 dB. We therefore apply a simple outlier removal scheme by scann<strong>in</strong>g each estimated source us<strong>in</strong>g a w<strong>in</strong>dow of size w = 10 samples. An adjacent sample to the w<strong>in</strong>dow is identified as outlier if its absolute value is larger than 20% of the maximal signal amplitude, but the w<strong>in</strong>dow sample variance is lower than half of the variance when <strong>in</strong>clud<strong>in</strong>g the sample. The outliers are then replaced by the w<strong>in</strong>dow average. This rough outlierdetection algorithm works satisfactorily well, see Figure 7(d); 500
Chapter 11. EURASIP JASP, 2007 173 12 EURASIP Journal on Advances <strong>in</strong> Signal Process<strong>in</strong>g the perceptual audio quality <strong>in</strong>creased considerably, see also the differences between Figures 7(c) and 7(d), although the nom<strong>in</strong>al SNR <strong>in</strong>crease is only roughly 4.1 dB. Altogether, this example illustrates the applicability of the Hough SCA algorithm and its correspond<strong>in</strong>g SCA model to audio data sets also <strong>in</strong> noisy sett<strong>in</strong>gs, where ICA algorithms perform very poorly. 5.6. Other applications We are currently study<strong>in</strong>g several biomedical applications of the proposed model and algorithm, <strong>in</strong>clud<strong>in</strong>g the separation of functional magnetic resonance imag<strong>in</strong>g data sets as well as surface electromyograms. For results on the former data set, we refer to the detailed book chapters [22, 23]. The results of the k-SCA algorithm applied to the latter signals are shortly summarized <strong>in</strong> the follow<strong>in</strong>g. An electromyogram (EMG) denotes the electric signal generated by a contract<strong>in</strong>g muscle; its study is relevant to the diagnosis of motoneuron diseases as well as neurophysiological research. In general, EMG measurements make use of <strong>in</strong>vasive, pa<strong>in</strong>ful needle electrodes. An alternative is to use surface EMGs, which are measured us<strong>in</strong>g non<strong>in</strong>vasive, pa<strong>in</strong>less surface electrodes. However, <strong>in</strong> this case the signals are rather more difficult to <strong>in</strong>terpret due to noise and overlap of several source signals. When apply<strong>in</strong>g the k-SCA model to real record<strong>in</strong>gs, Hough-based separation outperforms classical approaches based on filter<strong>in</strong>g and ICA <strong>in</strong> terms of a greater reduction of the zero-cross<strong>in</strong>gs, a common measure to analyze the unknown extracted sources. The relative sEMG enhancement was 24.6 ± 21.4%, where the mean was taken over a group of 9 subjects. For a detailed analysis, compar<strong>in</strong>g various sparse factorization models both on toy and on real data, we refer to [30]. 6. CONCLUSION We have presented an algorithm for perform<strong>in</strong>g a global search for overcomplete SCA representations, and experiments confirm that Hough SCA is robust aga<strong>in</strong>st noise and outliers with breakdown po<strong>in</strong>ts up to 0.8. The algorithm employs hyperplane detection us<strong>in</strong>g a generalized Hough transform. Currently, we are work<strong>in</strong>g on apply<strong>in</strong>g the SCA algorithm to high-dimensional biomedical data sets to see how the different assumption of high sparsity contributes to the signal separation. ACKNOWLEDGMENTS The authors gratefully thank W. Nakamura for her suggestion of us<strong>in</strong>g the Hough transform when detect<strong>in</strong>g hyperplanes, and the anonymous reviewers for their comments, which significantly improved the manuscript. The first author acknowledges partial f<strong>in</strong>ancial support by the JSPS (PE 05543). REFERENCES [1] A. Cichocki and S. Amari, Adaptive Bl<strong>in</strong>d Signal and Image Process<strong>in</strong>g, John Wiley & Sons, New York, NY, USA, 2002. [2] A. Hyvär<strong>in</strong>en, J. Karhunen, and E. Oja, <strong>Independent</strong> <strong>Component</strong> <strong>Analysis</strong>, John Wiley & Sons, New York, NY, USA, 2001. [3] P. Comon, “<strong>Independent</strong> component analysis. A new concept?” Signal Process<strong>in</strong>g, vol. 36, no. 3, pp. 287–314, 1994. [4] F. J. Theis, “A new concept for separability problems <strong>in</strong> bl<strong>in</strong>d source separation,” Neural Computation, vol. 16, no. 9, pp. 1827–1850, 2004. [5] J. Eriksson and V. Koivunen, “Identifiability and separability of l<strong>in</strong>ear ica models revisited,” <strong>in</strong> Proceed<strong>in</strong>gs of the 4th International Symposium on <strong>Independent</strong> <strong>Component</strong> <strong>Analysis</strong> and Bl<strong>in</strong>d Source Separation (ICA ’03), pp. 23–27, Nara, Japan, April 2003. [6] S. S. Chen, D. L. Donoho, and M. A. Saunders, “Atomic decomposition by basis pursuit,” SIAM Journal of Scientific Comput<strong>in</strong>g, vol. 20, no. 1, pp. 33–61, 1998. [7] D. L. Donoho and M. Elad, “Optimally sparse representation <strong>in</strong> general (nonorthogonal) dictionaries via l 1 m<strong>in</strong>imization,” Proceed<strong>in</strong>gs of the National Academy of Sciences of the United States of America, vol. 100, no. 5, pp. 2197–2202, 2003. [8] F. J. Theis, E. W. Lang, and C. G. Puntonet, “A geometric algorithm for overcomplete l<strong>in</strong>ear ICA,” Neurocomput<strong>in</strong>g, vol. 56, no. 1–4, pp. 381–398, 2004. [9] P. Georgiev, F. J. Theis, and A. Cichocki, “Sparse component analysis and bl<strong>in</strong>d source separation of underdeterm<strong>in</strong>ed mixtures,” IEEE Transactions on Neural Networks, vol. 16, no. 4, pp. 992–996, 2005. [10] P. V. C. Hough, “Mach<strong>in</strong>e analysis of bubble chamber pictures,” <strong>in</strong> International Conference on High Energy Accelerators and Instrumentation, pp. 554–556, CERN, Geneva, Switzerland, 1959. [11] J. K. L<strong>in</strong>, D. G. Grier, and J. D. Cowan, “Feature extraction approach to bl<strong>in</strong>d source separation,” <strong>in</strong> Proceed<strong>in</strong>gs of the IEEE Workshop on Neural Networks for Signal Process<strong>in</strong>g (NNSP ’97), pp. 398–405, Amelia Island, Fla, USA, September 1997. [12] H. Sh<strong>in</strong>do and Y. Hirai, “An approach to overcomplete-bl<strong>in</strong>d source separation us<strong>in</strong>g geometric structure,” <strong>in</strong> Proceed<strong>in</strong>gs of Annual Conference of Japanese Neural Network Society (JNNS ’01), pp. 95–96, Naramachi Center, Nara, Japan, 2001. [13] F. J. Theis, C. G. Puntonet, and E. W. Lang, “Median-based cluster<strong>in</strong>g for underdeterm<strong>in</strong>ed bl<strong>in</strong>d signal process<strong>in</strong>g,” IEEE Signal Process<strong>in</strong>g Letters, vol. 13, no. 2, pp. 96–99, 2006. [14] L. Cirillo, A. Zoubir, and M. Am<strong>in</strong>, “Direction f<strong>in</strong>d<strong>in</strong>g of nonstationary signals us<strong>in</strong>g a time-frequency Hough transform,” <strong>in</strong> Proceed<strong>in</strong>gs of IEEE International Conference on Acoustics, Speech, and Signal Process<strong>in</strong>g (ICASSP ’05), pp. 2718–2721, Philadelphia, Pa, USA, March 2005. [15] S. Barbarossa, “<strong>Analysis</strong> of multicomponent LFM signals by a comb<strong>in</strong>ed Wigner-Hough transform,” IEEE Transactions on Signal Process<strong>in</strong>g, vol. 43, no. 6, pp. 1511–1515, 1995. [16] D. H. Ballard, “Generaliz<strong>in</strong>g the Hough transform to detect arbitrary shapes,” Pattern Recognition, vol. 13, no. 2, pp. 111– 122, 1981. [17] T.-W. Lee, M. S. Lewicki, M. Girolami, and T. J. Sejnowski, “Bl<strong>in</strong>d source separation of more sources than mixtures us<strong>in</strong>g overcomplete representations,” IEEE Signal Process<strong>in</strong>g Letters, vol. 6, no. 4, pp. 87–90, 1999. [18] K. Waheed and F. Salem, “Algebraic overcomplete <strong>in</strong>dependent component analysis,” <strong>in</strong> Proceed<strong>in</strong>gs of the 4th International Symposium on <strong>Independent</strong> <strong>Component</strong> <strong>Analysis</strong> and Bl<strong>in</strong>d Source Separation (ICA ’03), pp. 1077–1082, Nara, Japan, April 2003.
- Page 1 and 2:
Statistical machine learning of bio
- Page 3:
to Jakob
- Page 6 and 7:
vi Preface
- Page 8 and 9:
viii CONTENTS 3 Signal Processing 8
- Page 11 and 12:
Chapter 1 Statistical machine learn
- Page 13 and 14:
1.1. Introduction 5 auditory cortex
- Page 15 and 16:
1.2. Uniqueness issues in independe
- Page 17 and 18:
1.2. Uniqueness issues in independe
- Page 19 and 20:
S U M M A R Y T his �le contains
- Page 21 and 22:
1.3. Dependent component analysis 1
- Page 23 and 24:
Table 1.1: BSS algorithms based on
- Page 25 and 26:
1.3. Dependent component analysis 1
- Page 27 and 28:
1.3. Dependent component analysis 1
- Page 29 and 30:
1.3. Dependent component analysis 2
- Page 31 and 32:
1.3. Dependent component analysis 2
- Page 33 and 34:
1.4. Sparseness 25 1.4 Sparseness O
- Page 35 and 36:
1.4. Sparseness 27 Theorem 1.4.3 (S
- Page 37 and 38:
1.4. Sparseness 29 R 3 R 3 A BSRA R
- Page 39 and 40:
1.4. Sparseness 31 Sparse projectio
- Page 41 and 42:
1.5. Machine learning for data prep
- Page 43 and 44:
1.5. Machine learning for data prep
- Page 45 and 46:
1.5. Machine learning for data prep
- Page 47 and 48:
1.5. Machine learning for data prep
- Page 49 and 50:
1.5. Machine learning for data prep
- Page 51 and 52:
1.6. Applications to biomedical dat
- Page 53 and 54:
1.6. Applications to biomedical dat
- Page 55 and 56:
1.6. Applications to biomedical dat
- Page 57 and 58:
1.6. Applications to biomedical dat
- Page 59 and 60:
1.7. Outlook 51 noise data signal i
- Page 61:
Part II Papers 53
- Page 64 and 65:
56 Chapter 2. Neural Computation 16
- Page 66 and 67:
58 Chapter 2. Neural Computation 16
- Page 68 and 69:
60 Chapter 2. Neural Computation 16
- Page 70 and 71:
62 Chapter 2. Neural Computation 16
- Page 72 and 73:
64 Chapter 2. Neural Computation 16
- Page 74 and 75:
66 Chapter 2. Neural Computation 16
- Page 76 and 77:
68 Chapter 2. Neural Computation 16
- Page 78 and 79:
70 Chapter 2. Neural Computation 16
- Page 80 and 81:
72 Chapter 2. Neural Computation 16
- Page 82 and 83:
74 Chapter 2. Neural Computation 16
- Page 84 and 85:
76 Chapter 2. Neural Computation 16
- Page 86 and 87:
78 Chapter 2. Neural Computation 16
- Page 88 and 89:
80 Chapter 2. Neural Computation 16
- Page 90 and 91:
82 Chapter 3. Signal Processing 84(
- Page 92 and 93:
84 Chapter 3. Signal Processing 84(
- Page 94 and 95:
86 Chapter 3. Signal Processing 84(
- Page 96 and 97:
88 Chapter 3. Signal Processing 84(
- Page 98 and 99:
90 Chapter 4. Neurocomputing 64:223
- Page 100 and 101:
92 Chapter 4. Neurocomputing 64:223
- Page 102 and 103:
94 Chapter 4. Neurocomputing 64:223
- Page 104 and 105:
96 Chapter 4. Neurocomputing 64:223
- Page 106 and 107:
98 Chapter 4. Neurocomputing 64:223
- Page 108 and 109:
100 Chapter 4. Neurocomputing 64:22
- Page 110 and 111:
102 Chapter 4. Neurocomputing 64:22
- Page 112 and 113:
104 Chapter 5. IEICE TF E87-A(9):23
- Page 114 and 115:
106 Chapter 5. IEICE TF E87-A(9):23
- Page 116 and 117:
108 Chapter 5. IEICE TF E87-A(9):23
- Page 118 and 119:
110 Chapter 5. IEICE TF E87-A(9):23
- Page 120 and 121:
112 Chapter 5. IEICE TF E87-A(9):23
- Page 122 and 123:
114 Chapter 6. LNCS 3195:726-733, 2
- Page 124 and 125:
116 Chapter 6. LNCS 3195:726-733, 2
- Page 126 and 127:
118 Chapter 6. LNCS 3195:726-733, 2
- Page 128 and 129:
120 Chapter 6. LNCS 3195:726-733, 2
- Page 130 and 131: 122 Chapter 6. LNCS 3195:726-733, 2
- Page 132 and 133: 124 Chapter 7. Proc. ISCAS 2005, pa
- Page 134 and 135: 126 Chapter 7. Proc. ISCAS 2005, pa
- Page 136 and 137: 128 Chapter 7. Proc. ISCAS 2005, pa
- Page 138 and 139: 130 Chapter 8. Proc. NIPS 2006 Towa
- Page 140 and 141: 132 Chapter 8. Proc. NIPS 2006 1.3
- Page 142 and 143: 134 Chapter 8. Proc. NIPS 2006 stru
- Page 144 and 145: 136 Chapter 8. Proc. NIPS 2006 5.5
- Page 146 and 147: 138 Chapter 8. Proc. NIPS 2006
- Page 148 and 149: 140 Chapter 9. Neurocomputing (in p
- Page 150 and 151: 142 Chapter 9. Neurocomputing (in p
- Page 152 and 153: 144 Chapter 9. Neurocomputing (in p
- Page 154 and 155: 146 Chapter 9. Neurocomputing (in p
- Page 156 and 157: 148 Chapter 9. Neurocomputing (in p
- Page 158 and 159: 150 Chapter 9. Neurocomputing (in p
- Page 160 and 161: 152 Chapter 9. Neurocomputing (in p
- Page 162 and 163: 154 Chapter 9. Neurocomputing (in p
- Page 164 and 165: 156 Chapter 10. IEEE TNN 16(4):992-
- Page 166 and 167: 158 Chapter 10. IEEE TNN 16(4):992-
- Page 168 and 169: 160 Chapter 10. IEEE TNN 16(4):992-
- Page 170 and 171: 162 Chapter 11. EURASIP JASP, 2007
- Page 172 and 173: 164 Chapter 11. EURASIP JASP, 2007
- Page 174 and 175: 166 Chapter 11. EURASIP JASP, 2007
- Page 176 and 177: 168 Chapter 11. EURASIP JASP, 2007
- Page 178 and 179: 170 Chapter 11. EURASIP JASP, 2007
- Page 182 and 183: 174 Chapter 11. EURASIP JASP, 2007
- Page 184 and 185: 176 Chapter 12. LNCS 3195:718-725,
- Page 186 and 187: 178 Chapter 12. LNCS 3195:718-725,
- Page 188 and 189: 180 Chapter 12. LNCS 3195:718-725,
- Page 190 and 191: 182 Chapter 12. LNCS 3195:718-725,
- Page 192 and 193: 184 Chapter 12. LNCS 3195:718-725,
- Page 194 and 195: 186 Chapter 13. Proc. EUSIPCO 2005
- Page 196 and 197: 188 Chapter 13. Proc. EUSIPCO 2005
- Page 198 and 199: 190 Chapter 13. Proc. EUSIPCO 2005
- Page 200 and 201: 192 Chapter 14. Proc. ICASSP 2006 S
- Page 202 and 203: 194 Chapter 14. Proc. ICASSP 2006 A
- Page 204 and 205: 196 Chapter 14. Proc. ICASSP 2006
- Page 206 and 207: 198 Chapter 15. Neurocomputing, 69:
- Page 208 and 209: 200 Chapter 15. Neurocomputing, 69:
- Page 210 and 211: 202 Chapter 15. Neurocomputing, 69:
- Page 212 and 213: 204 Chapter 15. Neurocomputing, 69:
- Page 214 and 215: 206 Chapter 15. Neurocomputing, 69:
- Page 216 and 217: 208 Chapter 15. Neurocomputing, 69:
- Page 218 and 219: 210 Chapter 15. Neurocomputing, 69:
- Page 220 and 221: 212 Chapter 15. Neurocomputing, 69:
- Page 222 and 223: 214 Chapter 15. Neurocomputing, 69:
- Page 224 and 225: 216 Chapter 15. Neurocomputing, 69:
- Page 226 and 227: 218 Chapter 15. Neurocomputing, 69:
- Page 228 and 229: 220 Chapter 15. Neurocomputing, 69:
- Page 230 and 231:
222 Chapter 15. Neurocomputing, 69:
- Page 232 and 233:
224 Chapter 15. Neurocomputing, 69:
- Page 234 and 235:
226 Chapter 15. Neurocomputing, 69:
- Page 236 and 237:
228 Chapter 15. Neurocomputing, 69:
- Page 238 and 239:
230 Chapter 16. Proc. ICA 2006, pag
- Page 240 and 241:
232 Chapter 16. Proc. ICA 2006, pag
- Page 242 and 243:
234 Chapter 16. Proc. ICA 2006, pag
- Page 244 and 245:
236 Chapter 16. Proc. ICA 2006, pag
- Page 246 and 247:
238 Chapter 16. Proc. ICA 2006, pag
- Page 248 and 249:
240 Chapter 17. IEEE SPL 13(2):96-9
- Page 250 and 251:
242 Chapter 17. IEEE SPL 13(2):96-9
- Page 252 and 253:
244 Chapter 17. IEEE SPL 13(2):96-9
- Page 254 and 255:
246 Chapter 18. Proc. EUSIPCO 2006
- Page 256 and 257:
248 Chapter 18. Proc. EUSIPCO 2006
- Page 258 and 259:
250 Chapter 18. Proc. EUSIPCO 2006
- Page 260 and 261:
252 Chapter 19. LNCS 3195:977-984,
- Page 262 and 263:
254 Chapter 19. LNCS 3195:977-984,
- Page 264 and 265:
256 Chapter 19. LNCS 3195:977-984,
- Page 266 and 267:
258 Chapter 19. LNCS 3195:977-984,
- Page 268 and 269:
260 Chapter 19. LNCS 3195:977-984,
- Page 270 and 271:
262 Chapter 20. Signal Processing 8
- Page 272 and 273:
264 Chapter 20. Signal Processing 8
- Page 274 and 275:
266 Chapter 20. Signal Processing 8
- Page 276 and 277:
268 Chapter 20. Signal Processing 8
- Page 278 and 279:
270 Chapter 20. Signal Processing 8
- Page 280 and 281:
272 Chapter 20. Signal Processing 8
- Page 282 and 283:
274 Chapter 20. Signal Processing 8
- Page 284 and 285:
276 Chapter 20. Signal Processing 8
- Page 286 and 287:
278 Chapter 20. Signal Processing 8
- Page 288 and 289:
280 Chapter 20. Signal Processing 8
- Page 290 and 291:
282 Chapter 20. Signal Processing 8
- Page 292 and 293:
284 Chapter 20. Signal Processing 8
- Page 294 and 295:
286 Chapter 20. Signal Processing 8
- Page 296 and 297:
288 Chapter 20. Signal Processing 8
- Page 298 and 299:
290 Chapter 20. Signal Processing 8
- Page 300 and 301:
292 Chapter 21. Proc. BIOMED 2005,
- Page 302 and 303:
294 Chapter 21. Proc. BIOMED 2005,
- Page 304 and 305:
296 Chapter 21. Proc. BIOMED 2005,
- Page 306 and 307:
298 BIBLIOGRAPHY Barber, C., Dobkin
- Page 308 and 309:
300 BIBLIOGRAPHY Georgiev, P. (2001
- Page 310 and 311:
302 BIBLIOGRAPHY Keck, I., Theis, F
- Page 312 and 313:
304 BIBLIOGRAPHY Schießl, I., Sch
- Page 314 and 315:
306 BIBLIOGRAPHY Theis, F. and Inou