

Profile von Senioren mit Autounfällen (PROSA)
Profile von Senioren mit Autounfällen (PROSA)
Profile von Senioren mit Autounfällen (PROSA)

Sie wollen auch ein ePaper? Erhöhen Sie die Reichweite Ihrer Titel.
YUMPU macht aus Druck-PDFs automatisch weboptimierte ePaper, die Google liebt.
0,40<br />
0,30<br />
0,20<br />
0,10<br />
0,00<br />
-0,10<br />
-0,20<br />
-0,30<br />
-0,40<br />
-0,50<br />
-0,60<br />
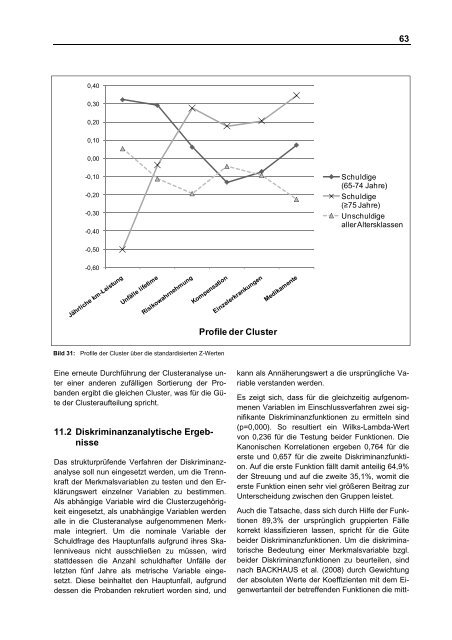
Bild 31: <strong>Profile</strong> der Cluster über die standardisierten Z-Werten<br />
Eine erneute Durchführung der Clusteranalyse unter<br />
einer anderen zufälligen Sortierung der Probanden<br />
ergibt die gleichen Cluster, was für die Güte<br />
der Clusteraufteilung spricht.<br />
11.2 Diskriminanzanalytische Ergebnisse<br />
Das strukturprüfende Verfahren der Diskriminanzanalyse<br />
soll nun eingesetzt werden, um die Trennkraft<br />
der Merkmalsvariablen zu testen und den Erklärungswert<br />
einzelner Variablen zu bestimmen.<br />
Als abhängige Variable wird die Clusterzugehörigkeit<br />
eingesetzt, als unabhängige Variablen werden<br />
alle in die Clusteranalyse aufgenommenen Merkmale<br />
integriert. Um die nominale Variable der<br />
Schuldfrage des Hauptunfalls aufgrund ihres Skalenniveaus<br />
nicht ausschließen zu müssen, wird<br />
stattdessen die Anzahl schuldhafter Unfälle der<br />
letzten fünf Jahre als metrische Variable eingesetzt.<br />
Diese beinhaltet den Hauptunfall, aufgrund<br />
dessen die Probanden rekrutiert worden sind, und<br />
<strong>Profile</strong> der Cluster<br />
63<br />
Schuldige<br />
(65-74 Jahre)<br />
Schuldige<br />
(≥75 Jahre)<br />
Unschuldige<br />
aller Altersklassen<br />
kann als Annäherungswert a die ursprüngliche Variable<br />
verstanden werden.<br />
Es zeigt sich, dass für die gleichzeitig aufgenommenen<br />
Variablen im Einschlussverfahren zwei signifikante<br />
Diskriminanzfunktionen zu er<strong>mit</strong>teln sind<br />
(p=0,000). So resultiert ein Wilks-Lambda-Wert<br />
<strong>von</strong> 0,236 für die Testung beider Funktionen. Die<br />
Kanonischen Korrelationen ergeben 0,764 für die<br />
erste und 0,657 für die zweite Diskriminanzfunktion.<br />
Auf die erste Funktion fällt da<strong>mit</strong> anteilig 64,9%<br />
der Streuung und auf die zweite 35,1%, wo<strong>mit</strong> die<br />
erste Funktion einen sehr viel größeren Beitrag zur<br />
Unterscheidung zwischen den Gruppen leistet.<br />
Auch die Tatsache, dass sich durch Hilfe der Funktionen<br />
89,3% der ursprünglich gruppierten Fälle<br />
korrekt klassifizieren lassen, spricht für die Güte<br />
beider Diskriminanzfunktionen. Um die diskriminatorische<br />
Bedeutung einer Merkmalsvariable bzgl.<br />
beider Diskriminanzfunktionen zu beurteilen, sind<br />
nach BACKHAUS et al. (2008) durch Gewichtung<br />
der absoluten Werte der Koeffizienten <strong>mit</strong> dem Eigenwertanteil<br />
der betreffenden Funktionen die <strong>mit</strong>t














