

Architecture of Computing Systems (Lecture Notes in Computer ...
Architecture of Computing Systems (Lecture Notes in Computer ...
Architecture of Computing Systems (Lecture Notes in Computer ...

Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
Speedup<br />
25<br />
20<br />
15<br />
10<br />
5<br />
0<br />
Optimiz<strong>in</strong>g Stencil Application on Multi-thread GPU <strong>Architecture</strong> 243<br />
3D-N 2D-N<br />
3D-2N 2D-2N<br />
3D-4N 2D-4N<br />
32 64 128 256<br />
Problem Size N 3<br />
(a)<br />
Speedup<br />
16<br />
14<br />
12<br />
10<br />
8<br />
6<br />
4<br />
2<br />
0<br />
1<br />
6.33<br />
Mgrid Implementation<br />
15.06<br />
CPU GPU- naive GPU-f<strong>in</strong>al<br />
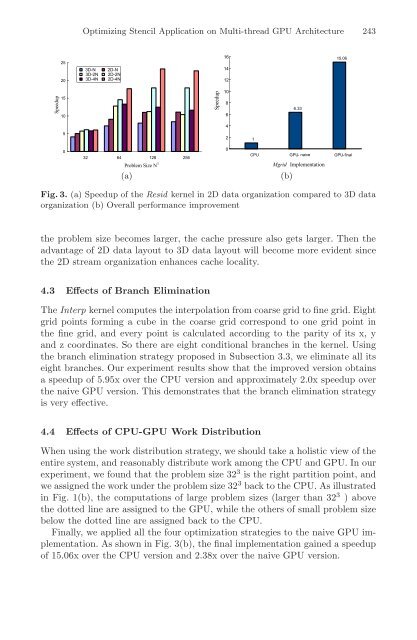
Fig. 3. (a) Speedup <strong>of</strong> the Resid kernel <strong>in</strong> 2D data organization compared to 3D data<br />
organization (b) Overall performance improvement<br />
the problem size becomes larger, the cache pressure also gets larger. Then the<br />
advantage <strong>of</strong> 2D data layout to 3D data layout will become more evident s<strong>in</strong>ce<br />
the 2D stream organization enhances cache locality.<br />
4.3 Effects <strong>of</strong> Branch Elim<strong>in</strong>ation<br />
The Interp kernel computes the <strong>in</strong>terpolation from coarse grid to f<strong>in</strong>e grid. Eight<br />
grid po<strong>in</strong>ts form<strong>in</strong>g a cube <strong>in</strong> the coarse grid correspond to one grid po<strong>in</strong>t <strong>in</strong><br />
the f<strong>in</strong>e grid, and every po<strong>in</strong>t is calculated accord<strong>in</strong>g to the parity <strong>of</strong> its x, y<br />
and z coord<strong>in</strong>ates. So there are eight conditional branches <strong>in</strong> the kernel. Us<strong>in</strong>g<br />
the branch elim<strong>in</strong>ation strategy proposed <strong>in</strong> Subsection 3.3, we elim<strong>in</strong>ate all its<br />
eight branches. Our experiment results show that the improved version obta<strong>in</strong>s<br />
a speedup <strong>of</strong> 5.95x over the CPU version and approximately 2.0x speedup over<br />
the naive GPU version. This demonstrates that the branch elim<strong>in</strong>ation strategy<br />
is very effective.<br />
4.4 Effects <strong>of</strong> CPU-GPU Work Distribution<br />
When us<strong>in</strong>g the work distribution strategy, we should take a holistic view <strong>of</strong> the<br />
entire system, and reasonably distribute work among the CPU and GPU. In our<br />
experiment, we found that the problem size 32 3 is the right partition po<strong>in</strong>t, and<br />
we assigned the work under the problem size 32 3 back to the CPU. As illustrated<br />
<strong>in</strong> Fig. 1(b), the computations <strong>of</strong> large problem sizes (larger than 32 3 )above<br />
the dotted l<strong>in</strong>e are assigned to the GPU, while the others <strong>of</strong> small problem size<br />
below the dotted l<strong>in</strong>e are assigned back to the CPU.<br />
F<strong>in</strong>ally, we applied all the four optimization strategies to the naive GPU implementation.<br />
As shown <strong>in</strong> Fig. 3(b), the f<strong>in</strong>al implementation ga<strong>in</strong>ed a speedup<br />
<strong>of</strong> 15.06x over the CPU version and 2.38x over the naive GPU version.<br />
(b)