

Download (1800Kb) - oops/ - Oldenburger Online-Publikations-Server
Download (1800Kb) - oops/ - Oldenburger Online-Publikations-Server
Download (1800Kb) - oops/ - Oldenburger Online-Publikations-Server

Sie wollen auch ein ePaper? Erhöhen Sie die Reichweite Ihrer Titel.
YUMPU macht aus Druck-PDFs automatisch weboptimierte ePaper, die Google liebt.
mean rmse<br />
23<br />
22.5<br />
22<br />
21.5<br />
21<br />
20.5<br />
20<br />
Gleichbleibende Reihenfolge der Trainingsmuster<br />
η=0.1<br />
η=0.05<br />
η=0.02<br />
η=0.01<br />
mean rmse<br />
23<br />
22.5<br />
22<br />
21.5<br />
21<br />
20.5<br />
20<br />
Wechselnde Reihenfolge der Trainingsmuster<br />
η=0.1<br />
η=0.05<br />
η=0.02<br />
η=0.01<br />
19.5<br />
19.5<br />
19<br />
19<br />
18.5<br />
5000 10000 15000 20000<br />
Anzahl der Trainingsschritte<br />
18.5<br />
1000 2000 3000 4000 5000 6000<br />
Anzahl der Trainingsschritte<br />
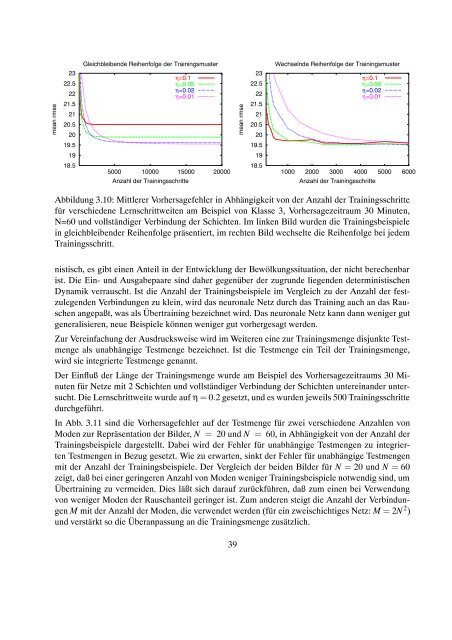
Abbildung 3.10: Mittlerer Vorhersagefehler in Abhängigkeit von der Anzahl der Trainingsschritte<br />
für verschiedene Lernschrittweiten am Beispiel von Klasse 3, Vorhersagezeitraum 30 Minuten,<br />
N=60 und vollständiger Verbindung der Schichten. Im linken Bild wurden die Trainingsbeispiele<br />
in gleichbleibender Reihenfolge präsentiert, im rechten Bild wechselte die Reihenfolge bei jedem<br />
Trainingsschritt.<br />
nistisch, es gibt einen Anteil in der Entwicklung der Bewölkungssituation, der nicht berechenbar<br />
ist. Die Ein- und Ausgabepaare sind daher gegenüber der zugrunde liegenden deterministischen<br />
Dynamik verrauscht. Ist die Anzahl der Trainingsbeispiele im Vergleich zu der Anzahl der festzulegenden<br />
Verbindungen zu klein, wird das neuronale Netz durch das Training auch an das Rauschen<br />
angepaßt, was als Übertraining bezeichnet wird. Das neuronale Netz kann dann weniger gut<br />
generalisieren, neue Beispiele können weniger gut vorhergesagt werden.<br />
Zur Vereinfachung der Ausdrucksweise wird im Weiteren eine zur Trainingsmenge disjunkte Testmenge<br />
als unabhängige Testmenge bezeichnet. Ist die Testmenge ein Teil der Trainingsmenge,<br />
wird sie integrierte Testmenge genannt.<br />
Der Einfluß der Länge der Trainingsmenge wurde am Beispiel des Vorhersagezeitraums 30 Minuten<br />
für Netze mit 2 Schichten und vollständiger Verbindung der Schichten untereinander untersucht.<br />
Die Lernschrittweite wurde auf η = 0.2 gesetzt, und es wurden jeweils 500 Trainingsschritte<br />
durchgeführt.<br />
In Abb. 3.11 sind die Vorhersagefehler auf der Testmenge für zwei verschiedene Anzahlen von<br />
Moden zur Repräsentation der Bilder, N = 20 und N = 60, in Abhängigkeit von der Anzahl der<br />
Trainingsbeispiele dargestellt. Dabei wird der Fehler für unabhängige Testmengen zu integrierten<br />
Testmengen in Bezug gesetzt. Wie zu erwarten, sinkt der Fehler für unabhängige Testmengen<br />
mit der Anzahl der Trainingsbeispiele. Der Vergleich der beiden Bilder für N = 20 und N = 60<br />
zeigt, daß bei einer geringeren Anzahl von Moden weniger Trainingsbeispiele notwendig sind, um<br />
Übertraining zu vermeiden. Dies läßt sich darauf zurückführen, daß zum einen bei Verwendung<br />
von weniger Moden der Rauschanteil geringer ist. Zum anderen steigt die Anzahl der Verbindungen<br />
M mit der Anzahl der Moden, die verwendet werden (für ein zweischichtiges Netz: M = 2N 2 )<br />
und verstärkt so die Überanpassung an die Trainingsmenge zusätzlich.<br />
39













