PPKE ITK PhD and MPhil Thesis Classes
PPKE ITK PhD and MPhil Thesis Classes
PPKE ITK PhD and MPhil Thesis Classes

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
4. IMPLEMENTING A GLOBAL ANALOGIC PROGRAMMING UNIT<br />
106 FOR EMULATED DIGITAL CNN PROCESSORS ON FPGA<br />
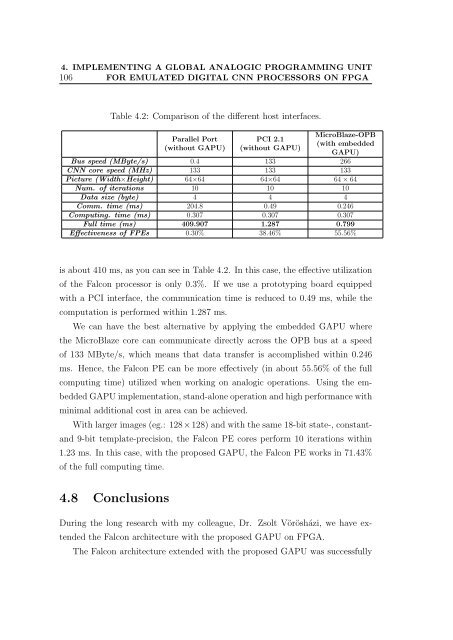
Table 4.2: Comparison of the different host interfaces.<br />
Parallel Port<br />
(without GAPU)<br />
PCI 2.1<br />
(without GAPU)<br />
MicroBlaze-OPB<br />
(with embedded<br />
GAPU)<br />
Bus speed (MByte/s) 0.4 133 266<br />
CNN core speed (MHz) 133 133 133<br />
Picture (Width×Height) 64×64 64×64 64 × 64<br />
Num. of iterations 10 10 10<br />
Data size (byte) 4 4 4<br />
Comm. time (ms) 204.8 0.49 0.246<br />
Computing. time (ms) 0.307 0.307 0.307<br />
Full time (ms) 409.907 1.287 0.799<br />
Effectiveness of FPEs 0.30% 38.46% 55.56%<br />
is about 410 ms, as you can see in Table 4.2. In this case, the effective utilization<br />
of the Falcon processor is only 0.3%. If we use a prototyping board equipped<br />
with a PCI interface, the communication time is reduced to 0.49 ms, while the<br />
computation is performed within 1.287 ms.<br />
We can have the best alternative by applying the embedded GAPU where<br />
the MicroBlaze core can communicate directly across the OPB bus at a speed<br />
of 133 MByte/s, which means that data transfer is accomplished within 0.246<br />
ms. Hence, the Falcon PE can be more effectively (in about 55.56% of the full<br />
computing time) utilized when working on analogic operations. Using the embedded<br />
GAPU implementation, st<strong>and</strong>-alone operation <strong>and</strong> high performance with<br />
minimal additional cost in area can be achieved.<br />
With larger images (eg.: 128×128) <strong>and</strong> with the same 18-bit state-, constant<strong>and</strong><br />
9-bit template-precision, the Falcon PE cores perform 10 iterations within<br />
1.23 ms. In this case, with the proposed GAPU, the Falcon PE works in 71.43%<br />
of the full computing time.<br />
4.8 Conclusions<br />
During the long research with my colleague, Dr. Zsolt Vörösházi, we have extended<br />
the Falcon architecture with the proposed GAPU on FPGA.<br />
The Falcon architecture extended with the proposed GAPU was successfully



![optika tervezés [Kompatibilitási mód] - Ez itt...](https://img.yumpu.com/45881475/1/190x146/optika-tervezacs-kompatibilitasi-mad-ez-itt.jpg?quality=85)