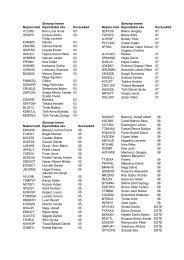
PPKE ITK PhD and MPhil Thesis Classes
PPKE ITK PhD and MPhil Thesis Classes
PPKE ITK PhD and MPhil Thesis Classes

Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
2.1 Introduction 45<br />
6<br />
4.5<br />
3<br />
Speedup<br />
1.5<br />
0<br />
SPE 1 SPE 2 SPE 4 SPE 8<br />
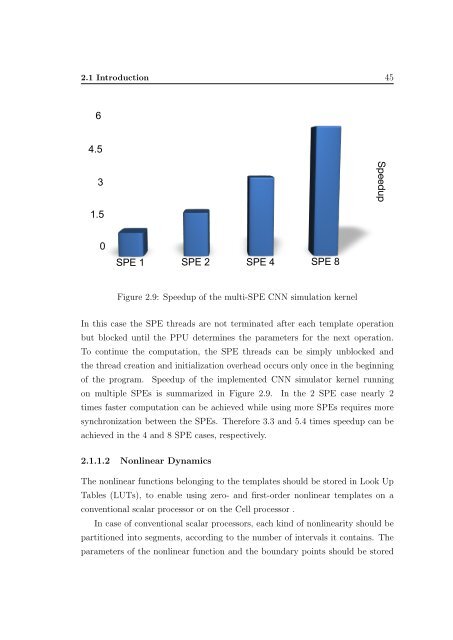
Figure 2.9: Speedup of the multi-SPE CNN simulation kernel<br />
In this case the SPE threads are not terminated after each template operation<br />
but blocked until the PPU determines the parameters for the next operation.<br />
To continue the computation, the SPE threads can be simply unblocked <strong>and</strong><br />
the thread creation <strong>and</strong> initialization overhead occurs only once in the beginning<br />
of the program. Speedup of the implemented CNN simulator kernel running<br />
on multiple SPEs is summarized in Figure 2.9. In the 2 SPE case nearly 2<br />
times faster computation can be achieved while using more SPEs requires more<br />
synchronization between the SPEs. Therefore 3.3 <strong>and</strong> 5.4 times speedup can be<br />
achieved in the 4 <strong>and</strong> 8 SPE cases, respectively.<br />
2.1.1.2 Nonlinear Dynamics<br />
The nonlinear functions belonging to the templates should be stored in Look Up<br />
Tables (LUTs), to enable using zero- <strong>and</strong> first-order nonlinear templates on a<br />
conventional scalar processor or on the Cell processor .<br />
In case of conventional scalar processors, each kind of nonlinearity should be<br />
partitioned into segments, according to the number of intervals it contains. The<br />
parameters of the nonlinear function <strong>and</strong> the boundary points should be stored



![optika tervezés [Kompatibilitási mód] - Ez itt...](https://img.yumpu.com/45881475/1/190x146/optika-tervezacs-kompatibilitasi-mad-ez-itt.jpg?quality=85)