PPKE ITK PhD and MPhil Thesis Classes
PPKE ITK PhD and MPhil Thesis Classes
PPKE ITK PhD and MPhil Thesis Classes

Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
2.1 Introduction 39<br />
Instruction historgram<br />
1.50E+07<br />
1.13E+07<br />
7.50E+06<br />
3.75E+06<br />
0E+00<br />
UR0 UR2 UR4 UR8<br />
Single cycle<br />
Dual cycle<br />
Nop cycle<br />
Stall due to branch miss<br />
Stall due to prefetch miss<br />
Stall due to dependency<br />
Stall due to fp resource conflict Stall due to waiting for hint target<br />
Stall due to dp pipeline<br />
Channel stall cycle<br />
SPU Initialization cycle<br />
Number of Instructions<br />
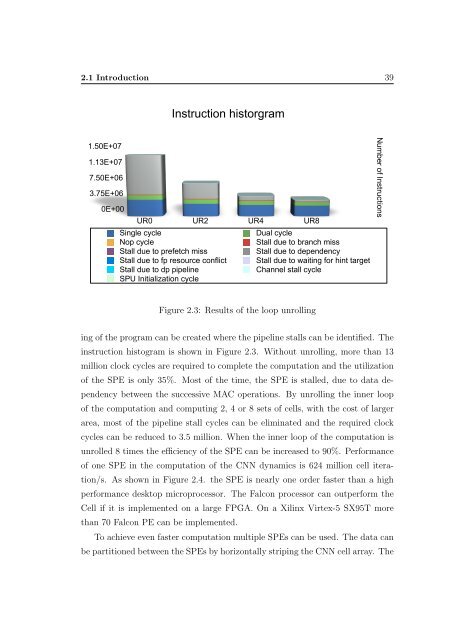
Figure 2.3: Results of the loop unrolling<br />
ing of the program can be created where the pipeline stalls can be identified. The<br />
instruction histogram is shown in Figure 2.3. Without unrolling, more than 13<br />
million clock cycles are required to complete the computation <strong>and</strong> the utilization<br />
of the SPE is only 35%. Most of the time, the SPE is stalled, due to data dependency<br />
between the successive MAC operations. By unrolling the inner loop<br />
of the computation <strong>and</strong> computing 2, 4 or 8 sets of cells, with the cost of larger<br />
area, most of the pipeline stall cycles can be eliminated <strong>and</strong> the required clock<br />
cycles can be reduced to 3.5 million. When the inner loop of the computation is<br />
unrolled 8 times the efficiency of the SPE can be increased to 90%. Performance<br />
of one SPE in the computation of the CNN dynamics is 624 million cell iteration/s.<br />
As shown in Figure 2.4. the SPE is nearly one order faster than a high<br />
performance desktop microprocessor. The Falcon processor can outperform the<br />
Cell if it is implemented on a large FPGA. On a Xilinx Virtex-5 SX95T more<br />
than 70 Falcon PE can be implemented.<br />
To achieve even faster computation multiple SPEs can be used. The data can<br />
be partitioned between the SPEs by horizontally striping the CNN cell array. The



![optika tervezés [Kompatibilitási mód] - Ez itt...](https://img.yumpu.com/45881475/1/190x146/optika-tervezacs-kompatibilitasi-mad-ez-itt.jpg?quality=85)