

Download Full Issue in PDF - Academy Publisher
Download Full Issue in PDF - Academy Publisher
Download Full Issue in PDF - Academy Publisher

Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
JOURNAL OF COMPUTERS, VOL. 8, NO. 6, JUNE 2013 1413<br />
F<br />
I<br />
F<br />
O<br />
S<br />
shift<br />
registers<br />
off-chip memory<br />
and FIFO<br />
.<br />
.<br />
.<br />
.<br />
.<br />
.<br />
F<br />
I<br />
F<br />
O<br />
.<br />
.<br />
.<br />
S<br />
shift<br />
registers<br />
.<br />
.<br />
.<br />
convolution filter array<br />
F<br />
I<br />
F<br />
O<br />
S<br />
shift<br />
registers<br />
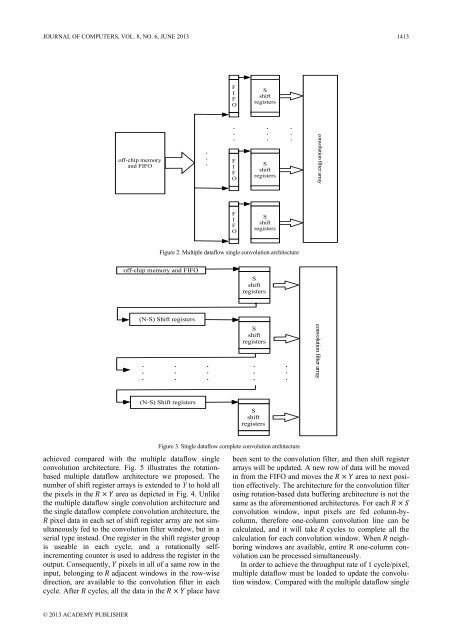
Figure 2. Multiple dataflow s<strong>in</strong>gle convolution architecture<br />
off-chip memory and FIFO<br />
S<br />
shift<br />
registers<br />
(N-S) Shift registers<br />
.<br />
.<br />
.<br />
.<br />
.<br />
.<br />
.<br />
.<br />
.<br />
S<br />
shift<br />
registers<br />
.<br />
.<br />
.<br />
.<br />
.<br />
.<br />
convolution filter array<br />
(N-S) Shift registers<br />
S<br />
shift<br />
registers<br />
achieved compared with the multiple dataflow s<strong>in</strong>gle<br />
convolution architecture. Fig. 5 illustrates the rotationbased<br />
multiple dataflow architecture we proposed. The<br />
number of shift register arrays is extended to Y to hold all<br />
the pixels <strong>in</strong> the area as depicted <strong>in</strong> Fig. 4. Unlike<br />
the multiple dataflow s<strong>in</strong>gle convolution architecture and<br />
the s<strong>in</strong>gle dataflow complete convolution architecture, the<br />
pixel data <strong>in</strong> each set of shift register array are not simultaneously<br />
fed to the convolution filter w<strong>in</strong>dow, but <strong>in</strong> a<br />
serial type <strong>in</strong>stead. One register <strong>in</strong> the shift register group<br />
is useable <strong>in</strong> each cycle, and a rotationally self<strong>in</strong>crement<strong>in</strong>g<br />
counter is used to address the register <strong>in</strong> the<br />
output. Consequently, pixels <strong>in</strong> all of a same row <strong>in</strong> the<br />
<strong>in</strong>put, belong<strong>in</strong>g to adjacent w<strong>in</strong>dows <strong>in</strong> the row-wise<br />
direction, are available to the convolution filter <strong>in</strong> each<br />
cycle. After cycles, all the data <strong>in</strong> the place have<br />
Figure 3. S<strong>in</strong>gle dataflow complete convolution architecture<br />
been sent to the convolution filter, and then shift register<br />
arrays will be updated. A new row of data will be moved<br />
<strong>in</strong> from the FIFO and moves the area to next position<br />
effectively. The architecture for the convolution filter<br />
us<strong>in</strong>g rotation-based data buffer<strong>in</strong>g architecture is not the<br />
same as the aforementioned architectures. For each <br />
convolution w<strong>in</strong>dow, <strong>in</strong>put pixels are fed column-bycolumn,<br />
therefore one-column convolution l<strong>in</strong>e can be<br />
calculated, and it will take cycles to complete all the<br />
calculation for each convolution w<strong>in</strong>dow. When neighbor<strong>in</strong>g<br />
w<strong>in</strong>dows are available, entire R one-column convolution<br />
can be processed simultaneously.<br />
In order to achieve the throughput rate of 1 cycle/pixel,<br />
multiple dataflow must be loaded to update the convolution<br />
w<strong>in</strong>dow. Compared with the multiple dataflow s<strong>in</strong>gle<br />
© 2013 ACADEMY PUBLISHER













