

Messung maschineller¨Ubersetzbarkeit von ... - Parallele Systeme
Messung maschineller¨Ubersetzbarkeit von ... - Parallele Systeme
Messung maschineller¨Ubersetzbarkeit von ... - Parallele Systeme

Sie wollen auch ein ePaper? Erhöhen Sie die Reichweite Ihrer Titel.
YUMPU macht aus Druck-PDFs automatisch weboptimierte ePaper, die Google liebt.
5.1. Allgemeine Textmerkmale<br />
5.1.4. Seltenheit <strong>von</strong> Wörtern<br />
Weil aufgrund der prinzipiell unbeschränkten Wortanzahl der deutschen Sprache nicht<br />
alle Wörter in den Lexika der Übersetzungsprogramme vorhanden sein können und eine<br />
Beschränkung auf die wichtigsten notwendig ist, ist zu vermuten, dass sehr seltene und<br />
somit wahrscheinlich in den Lexika der MÜ-<strong>Systeme</strong> fehlende Wörter die Übersetzungsqualität<br />
mindern, weil sie nicht übersetzt werden können oder Übersetzungen zufällig<br />
gewählt werden müssen.<br />
Es bot sich an, die Untersuchung der Seltenheit <strong>von</strong> Wörtern mit der Untersuchung der<br />
Auswirkungen <strong>von</strong> Komposita zu verbinden, weil komplexe Komposita in der Regel auch<br />
sehr selten sind. Überprüft man also die Auswirkungen sehr langer Komposita, ist dies<br />
zugleich auch eine Überprüfung seltener Wörter. Diese zusammengelegte Untersuchung<br />
wird in Abschnitt 5.2.3 dargelegt.<br />
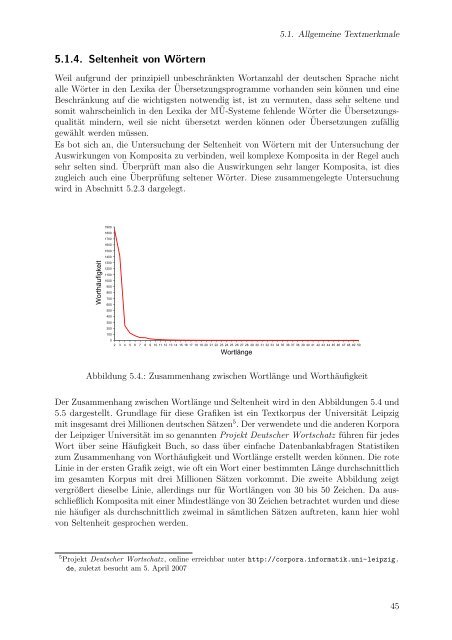
Abbildung 5.4.: Zusammenhang zwischen Wortlänge und Worthäufigkeit<br />
Der Zusammenhang zwischen Wortlänge und Seltenheit wird in den Abbildungen 5.4 und<br />
5.5 dargestellt. Grundlage für diese Grafiken ist ein Textkorpus der Universität Leipzig<br />
mit insgesamt drei Millionen deutschen Sätzen 5 . Der verwendete und die anderen Korpora<br />
der Leipziger Universität im so genannten Projekt Deutscher Wortschatz führen für jedes<br />
Wort über seine Häufigkeit Buch, so dass über einfache Datenbankabfragen Statistiken<br />
zum Zusammenhang <strong>von</strong> Worthäufigkeit und Wortlänge erstellt werden können. Die rote<br />
Linie in der ersten Grafik zeigt, wie oft ein Wort einer bestimmten Länge durchschnittlich<br />
im gesamten Korpus mit drei Millionen Sätzen vorkommt. Die zweite Abbildung zeigt<br />
vergrößert dieselbe Linie, allerdings nur für Wortlängen <strong>von</strong> 30 bis 50 Zeichen. Da ausschließlich<br />
Komposita mit einer Mindestlänge <strong>von</strong> 30 Zeichen betrachtet wurden und diese<br />
nie häufiger als durchschnittlich zweimal in sämtlichen Sätzen auftreten, kann hier wohl<br />
<strong>von</strong> Seltenheit gesprochen werden.<br />
5 Projekt Deutscher Wortschatz, online erreichbar unter http://corpora.informatik.uni-leipzig.<br />
de, zuletzt besucht am 5. April 2007<br />
45













