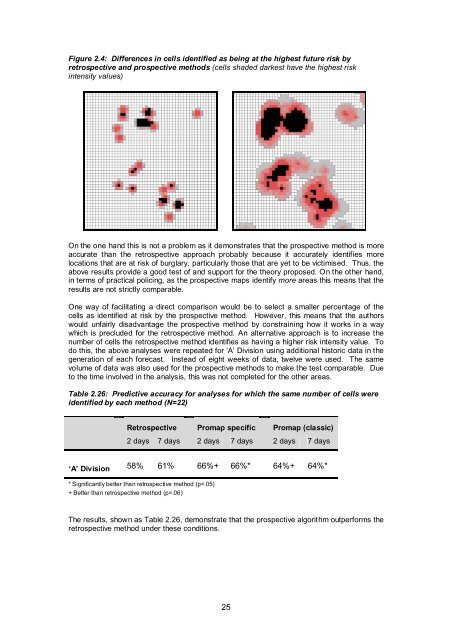
Figure 2.4: Differences <strong>in</strong> cells identified as be<strong>in</strong>g at the highest future risk byretrospective and prospective methods (cells shaded darkest have the highest risk<strong>in</strong>tensity values)On the one hand this is not a problem as it demonstrates that the prospective method is moreaccurate than the retrospective approach probably because it accurately identifies morelocations that are at risk of burglary, particularly those that are yet to be victimised. Thus, theabove results provide a good test of and support for the theory proposed. On the other hand,<strong>in</strong> terms of practical polic<strong>in</strong>g, as the prospective maps identify more areas this means that theresults are not strictly comparable.One way of facilitat<strong>in</strong>g a direct comparison would be to select a smaller percentage of thecells as identified at risk by the prospective method. However, this means that the authorswould unfairly disadvantage the prospective method by constra<strong>in</strong><strong>in</strong>g how it works <strong>in</strong> a waywhich is precluded for the retrospective method. An alternative approach is to <strong>in</strong>crease thenumber of cells the retrospective method identifies as hav<strong>in</strong>g a higher risk <strong>in</strong>tensity value. Todo this, the above analyses were repeated for ‘A’ Division us<strong>in</strong>g additional historic data <strong>in</strong> thegeneration of each forecast. Instead of eight weeks of data, twelve were used. The samevolume of data was also used for the prospective methods to make the test comparable. Dueto the time <strong>in</strong>volved <strong>in</strong> the analysis, this was not completed for the other areas.Table 2.26: Predictive accuracy for analyses for which the same number of cells wereidentified by each method (N=22)Retrospective Promap specific Promap (classic)2 days 7 days 2 days 7 days 2 days 7 days‘A’ Division 58% 61% 66%+ 66%* 64%+ 64%** Significantly better than retrospective method (p
Patroll<strong>in</strong>g efficiencyAs discussed elsewhere (Bowers et al., 2004), even though a map may predict a largevolume of <strong>crime</strong>, it may be of little utility <strong>in</strong> an <strong>operational</strong> <strong>context</strong> if it is made of a largenumber of dispersed hotspots. The best map would perhaps be one with a relatively smallnumber of clearly def<strong>in</strong>ed hotspots. One way of measur<strong>in</strong>g this is to count the number ofhotspots generated. Another way, which is slightly more sophisticated is to conduct a nearestneighbour analysis.Nearest neighbour analysis is a test of spatial randomness. The nearest neighbour <strong>in</strong>dex(nni) <strong>in</strong> particular measures how clustered po<strong>in</strong>ts or cells are relative to what would beexpected on the basis of chance. Here, the authors consider the application of this to theanalysis of hot cells - the ten per cent of cells with the highest risk <strong>in</strong>tensity values. How closetogether are they? In this <strong>context</strong>, a value of one would <strong>in</strong>dicate that the hot cells wererandomly distributed across the area. The lower the value of the nni, the more the hot cellscoalesce to form coherent (and hence policeable) hotspots. The <strong>in</strong>dex can be computed forthe nearest high-risk neighbour for each cell, which will often be the adjacent cell. It can alsobe computed for the next nearest neighbour, the next, and so on, up to k-orders. The value ofk is specified by the researcher. Thus, the k-order parameter describes which neighbour isbe<strong>in</strong>g analysed, the nearest (1st order), the next nearest (2nd order) and so on (up to the kthorder). To illustrate, consider Figure 2.5. The nni for the two examples would be the samefor the first order nearest neighbours. However, for the data on the left the second order nniwould be lower than that for the data on the right, thereby <strong>in</strong>dicat<strong>in</strong>g that the hot cells <strong>in</strong> theformer are more spatially clustered than the latter. The most efficient hotspots would perhapsbe those with a low nni for the nearest neighbour, for the next, but particularly for the higherorders. This is because the greater the number of orders for which the nni rema<strong>in</strong>s low is an<strong>in</strong>dication of a lower number of hotspots that are more coalescent. A series of dispersedhotspots would have a low distance for the first neighbour, but the distance would <strong>in</strong>crease foreach successive order. A patroll<strong>in</strong>g police officer would then have to spend more time mov<strong>in</strong>gthrough low risk areas.Figure 2.5: Illustration of a simple nearest neighbour analysis for two data sets● ● ● ●●●●●Readers may be aware that this type of analysis is traditionally used to exam<strong>in</strong>e the degree towhich <strong>crime</strong> is clustered <strong>in</strong> space, but as should be evident from the above rationale it is ofclear analytic value here, albeit a novel application of the test. To recapitulate, this type ofanalysis can be used as one <strong>in</strong>dex of patroll<strong>in</strong>g efficiency. The lower the nni for higher k-orders, the more efficient the map <strong>in</strong> this respect. Figure 2.6 shows an example analysis ofthis k<strong>in</strong>d for ‘A’ Division for both a retrospective hotspot and for a prospective map. Theresults are clear. The prospective map has a low nni across all orders, whereas for theretrospective map whilst the nni is <strong>in</strong>itially low, at around order ten it starts to <strong>in</strong>crease.Analyses for other maps generated for different days revealed the same pattern of results. Itis difficult to overstate the importance of this result for the applicability of Promap to patroldeployment.26
- Page 2 and 3: 1. UCL JILL DANDO INSTITUTE OF CRIM
- Page 4 and 5: ContentsAcknowledgementsExecutive s
- Page 6 and 7: 2.5 Illustration of a simple neares
- Page 8 and 9: Project outcomesPatterns of burglar
- Page 10 and 11: those that involved collaboration w
- Page 12 and 13: 1. IntroductionThis report represen
- Page 14 and 15: optimally calibrated system, the go
- Page 16 and 17: e ij = n .j x n i.nWhere, e ij is t
- Page 18 and 19: Table 2.2: Knox ratios for Mansfiel
- Page 20 and 21: Table 2.6: Monte-Carlo results for
- Page 22 and 23: Table 2.10: Weekly Knox ratios for
- Page 24 and 25: Table 2.14: Monte-Carlo results for
- Page 26 and 27: Figure 2.1: The five policing areas
- Page 28 and 29: The results for area 5 again demons
- Page 30 and 31: The bandwidth used to generate the
- Page 32: a densely populated urban area this
- Page 35: Table 2.24: Average number of crime
- Page 39 and 40: 3. Tactical options and selecting a
- Page 41 and 42: Selecting a pilot siteThe decision
- Page 43 and 44: Table 3.2: Tactical options matrixT
- Page 45 and 46: Type ofinterventionStudyUse ofintel
- Page 47 and 48: Other potential tactical optionsAt
- Page 49 and 50: 4. System development and evolution
- Page 51 and 52: the same time of day as each other
- Page 53 and 54: unfortunately, implementation or us
- Page 55 and 56: any tactical options were employed
- Page 57 and 58: the end of the pilot. In addition t
- Page 59 and 60: Figure 5.1: Promap dissemination pr
- Page 61 and 62: the busy schedule of the new Divisi
- Page 63 and 64: Tactical deliveryCommand Team daily
- Page 65 and 66: Table 5.3: Number of respondents wh
- Page 67 and 68: permitted, up to four plain clothed
- Page 69 and 70: observation made by those who used
- Page 71 and 72: A simple time-series analysis (see
- Page 73 and 74: Two approaches were used to compute
- Page 75 and 76: Figure 6.3: Changes in the proporti
- Page 77 and 78: Figure 6.5: Changes in the proporti
- Page 79 and 80: With respect to implementation real
- Page 81 and 82: ReferencesAggresti, A. (1996) An In
- Page 83 and 84: Johnson, S.D., Summers, L., and Pea
- Page 85 and 86: Appendix 1. The information technol
- Page 87 and 88:
Figure A1.2: Stand-alone applicatio
- Page 89 and 90:
Recommendations that may be realise
- Page 91 and 92:
Section 1: knowledge and understand
- Page 93 and 94:
Extra Comments (please outline any
- Page 95 and 96:
In relation to the evaluation of in
- Page 97 and 98:
Time-series analysisFor the purpose
- Page 99 and 100:
Figure A3.1: Changes in the spatial
- Page 101 and 102:
Figure A3.2: Lorenz curves showing
- Page 103 and 104:
To recapitulate and elaborate, the
- Page 105 and 106:
Concluding comments on methodThe te
- Page 107 and 108:
Figure A5.2: An enlargement of the
- Page 109 and 110:
Figure A5.6: Prospective map magnif
- Page 111:
Produced by the Research Developmen