

Lecture Notes in Computer Science 4917
Lecture Notes in Computer Science 4917
Lecture Notes in Computer Science 4917

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
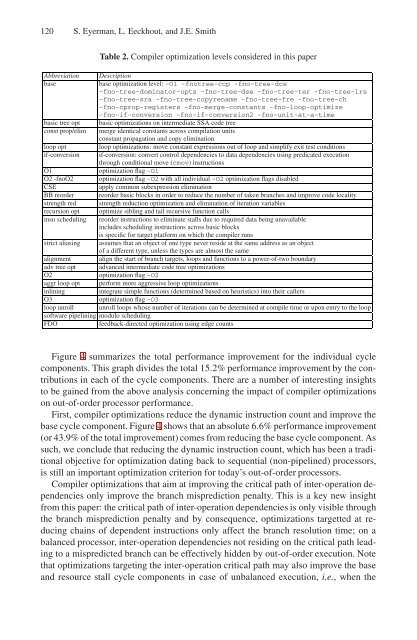
120 S. Eyerman, L. Eeckhout, and J.E. Smith<br />
Table 2. Compiler optimization levels considered <strong>in</strong> this paper<br />
Abbreviation Description<br />
base base optimization level: -O1 -fnotree-ccp -fno-tree-dce<br />
-fno-tree-dom<strong>in</strong>ator-opts -fno-tree-dse -fno-tree-ter -fno-tree-lrs<br />
-fno-tree-sra -fno-tree-copyrename -fno-tree-fre -fno-tree-ch<br />
-fno-cprop-registers -fno-merge-constants -fno-loop-optimize<br />
-fno-if-conversion -fno-if-conversion2 -fno-unit-at-a-time<br />
basic tree opt basic optimizations on <strong>in</strong>termediate SSA code tree<br />
const prop/elim merge identical constants across compilation units<br />
constant propagation and copy elim<strong>in</strong>ation<br />
loop opt loop optimizations: move constant expressions out of loop and simplify exit test conditions<br />
if-conversion if-conversion: convert control dependencies to data dependencies us<strong>in</strong>g predicated execution<br />
through conditional move (cmov) <strong>in</strong>structions<br />
O1 optimization flag -O1<br />
O2 -fnoO2 optimization flag -O2 with all <strong>in</strong>dividual -O2 optimization flags disabled<br />
CSE apply common subexpression elim<strong>in</strong>ation<br />
BB reorder reorder basic blocks <strong>in</strong> order to reduce the number of taken branches and improve code locality<br />
strength red strength reduction optimization and elim<strong>in</strong>ation of iteration variables<br />
recursion opt optimize sibl<strong>in</strong>g and tail recursive function calls<br />
<strong>in</strong>sn schedul<strong>in</strong>g reorder <strong>in</strong>structions to elim<strong>in</strong>ate stalls due to required data be<strong>in</strong>g unavailable<br />
<strong>in</strong>cludes schedul<strong>in</strong>g <strong>in</strong>structions across basic blocks<br />
is specific for target platform on which the compiler runs<br />
strict alias<strong>in</strong>g assumes that an object of one type never reside at the same address as an object<br />
of a different type, unless the types are almost the same<br />
alignment align the start of branch targets, loops and functions to a power-of-two boundary<br />
adv tree opt advanced <strong>in</strong>termediate code tree optimizations<br />
O2 optimization flag -O2<br />
aggr loop opt perform more aggressive loop optimizations<br />
<strong>in</strong>l<strong>in</strong><strong>in</strong>g <strong>in</strong>tegrate simple functions (determ<strong>in</strong>ed based on heuristics) <strong>in</strong>to their callers<br />
O3 optimization flag -O3<br />
loop unroll unroll loops whose number of iterations can be determ<strong>in</strong>ed at compile time or upon entry to the loop<br />
software pipel<strong>in</strong><strong>in</strong>g modulo schedul<strong>in</strong>g<br />
FDO feedback-directed optimization us<strong>in</strong>g edge counts<br />
Figure 4 summarizes the total performance improvement for the <strong>in</strong>dividual cycle<br />
components. This graph divides the total 15.2% performance improvement by the contributions<br />
<strong>in</strong> each of the cycle components. There are a number of <strong>in</strong>terest<strong>in</strong>g <strong>in</strong>sights<br />
to be ga<strong>in</strong>ed from the above analysis concern<strong>in</strong>g the impact of compiler optimizations<br />
on out-of-order processor performance.<br />
First, compiler optimizations reduce the dynamic <strong>in</strong>struction count and improve the<br />
base cycle component. Figure 4 shows that an absolute 6.6% performance improvement<br />
(or 43.9% of the total improvement) comes from reduc<strong>in</strong>g the base cycle component. As<br />
such, we conclude that reduc<strong>in</strong>g the dynamic <strong>in</strong>struction count, which has been a traditional<br />
objective for optimization dat<strong>in</strong>g back to sequential (non-pipel<strong>in</strong>ed) processors,<br />
is still an important optimization criterion for today’s out-of-order processors.<br />
Compiler optimizations that aim at improv<strong>in</strong>g the critical path of <strong>in</strong>ter-operation dependencies<br />
only improve the branch misprediction penalty. This is a key new <strong>in</strong>sight<br />
from this paper: the critical path of <strong>in</strong>ter-operation dependencies is only visible through<br />
the branch misprediction penalty and by consequence, optimizations targetted at reduc<strong>in</strong>g<br />
cha<strong>in</strong>s of dependent <strong>in</strong>structions only affect the branch resolution time; on a<br />
balanced processor, <strong>in</strong>ter-operation dependencies not resid<strong>in</strong>g on the critical path lead<strong>in</strong>g<br />
to a mispredicted branch can be effectively hidden by out-of-order execution. Note<br />
that optimizations target<strong>in</strong>g the <strong>in</strong>ter-operation critical path may also improve the base<br />
and resource stall cycle components <strong>in</strong> case of unbalanced execution, i.e., when the














