

Diplomarbeit von Michael Schindler
Diplomarbeit von Michael Schindler
Diplomarbeit von Michael Schindler

Erfolgreiche ePaper selbst erstellen
Machen Sie aus Ihren PDF Publikationen ein blätterbares Flipbook mit unserer einzigartigen Google optimierten e-Paper Software.
(a)<br />
αǫA<br />
α<br />
p<br />
p c<br />
−1 0 1 x/σS<br />
1<br />
ǫA<br />
ωA<br />
4.2 Das Verhalten des ANTS 83<br />
˜p<br />
A<br />
(b)<br />
−1 0 1 x/σS<br />
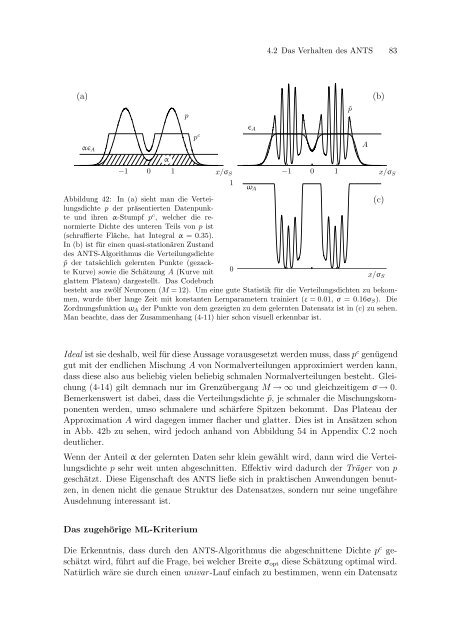
Abbildung 42: In (a) sieht man die Verteilungsdichte<br />
p der präsentierten Datenpunkte<br />
und ihren α-Stumpf p<br />
(c)<br />
0<br />
x/σS<br />
c , welcher die renormierte<br />
Dichte des unteren Teils <strong>von</strong> p ist<br />
(schraffierte Fläche, hat Integral α = 0.35).<br />
In (b) ist für einen quasi-stationären Zustand<br />
des ANTS-Algorithmus die Verteilungsdichte<br />
˜p der tatsächlich gelernten Punkte (gezackte<br />
Kurve) sowie die Schätzung A (Kurve mit<br />
glattem Plateau) dargestellt. Das Codebuch<br />
besteht aus zwölf Neuronen (M = 12). Um eine gute Statistik für die Verteilungsdichten zu bekommen,<br />
wurde über lange Zeit mit konstanten Lernparametern trainiert (ε = 0.01, σ = 0.16σS). Die<br />
Zordnungsfunktion ωA der Punkte <strong>von</strong> dem gezeigten zu dem gelernten Datensatz ist in (c) zu sehen.<br />
Man beachte, dass der Zusammenhang (4-11) hier schon visuell erkennbar ist.<br />
Ideal ist sie deshalb, weil für diese Aussage vorausgesetzt werden muss, dass p c genügend<br />
gut mit der endlichen Mischung A <strong>von</strong> Normalverteilungen approximiert werden kann,<br />
dass diese also aus beliebig vielen beliebig schmalen Normalverteilungen besteht. Gleichung<br />
(4-14) gilt demnach nur im Grenzübergang M → ∞ und gleichzeitigem σ → 0.<br />
Bemerkenswert ist dabei, dass die Verteilungsdichte ˜p, je schmaler die Mischungskomponenten<br />
werden, umso schmalere und schärfere Spitzen bekommt. Das Plateau der<br />
Approximation A wird dagegen immer flacher und glatter. Dies ist in Ansätzen schon<br />
in Abb. 42b zu sehen, wird jedoch anhand <strong>von</strong> Abbildung 54 in Appendix C.2 noch<br />
deutlicher.<br />
Wenn der Anteil α der gelernten Daten sehr klein gewählt wird, dann wird die Verteilungsdichte<br />
p sehr weit unten abgeschnitten. Effektiv wird dadurch der Träger <strong>von</strong> p<br />
geschätzt. Diese Eigenschaft des ANTS ließe sich in praktischen Anwendungen benutzen,<br />
in denen nicht die genaue Struktur des Datensatzes, sondern nur seine ungefähre<br />
Ausdehnung interessant ist.<br />
Das zugehörige ML-Kriterium<br />
Die Erkenntnis, dass durch den ANTS-Algorithmus die abgeschnittene Dichte p c geschätzt<br />
wird, führt auf die Frage, bei welcher Breite σopt diese Schätzung optimal wird.<br />
Natürlich wäre sie durch einen univar-Lauf einfach zu bestimmen, wenn ein Datensatz

