

Diplomarbeit von Michael Schindler
Diplomarbeit von Michael Schindler
Diplomarbeit von Michael Schindler

Erfolgreiche ePaper selbst erstellen
Machen Sie aus Ihren PDF Publikationen ein blätterbares Flipbook mit unserer einzigartigen Google optimierten e-Paper Software.
88 4. Neuigkeitsorientiertes Lernen<br />
1<br />
x/σS<br />
−1<br />
x/σS<br />
x(t)<br />
C(t)<br />
(a)<br />
0 TS t<br />
x(t) x(t)<br />
1<br />
−1<br />
1<br />
x/σS<br />
−1<br />
C(t)<br />
(b)<br />
0 TS t<br />
x(t)<br />
C(t)<br />
(c)<br />
0 TS t<br />
t<br />
TS<br />
(d)<br />
0<br />
0 TS t<br />
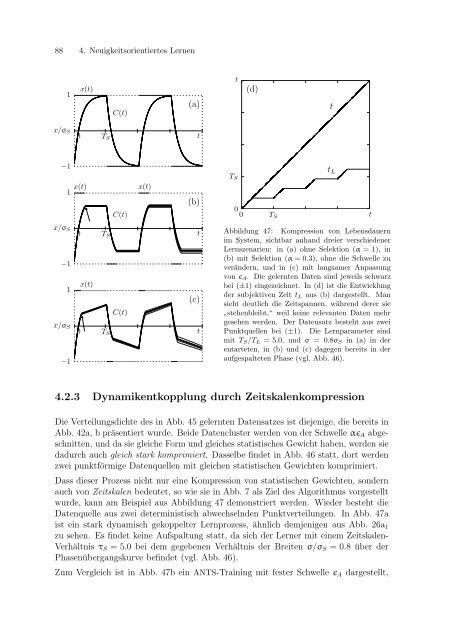
Abbildung 47: Kompression <strong>von</strong> Lebensdauern<br />
im System, sichtbar anhand dreier verschiedener<br />
Lernszenarien: in (a) ohne Selektion (α = 1), in<br />
(b) mit Selektion (α = 0.3), ohne die Schwelle zu<br />
verändern, und in (c) mit langsamer Anpassung<br />
<strong>von</strong> ǫA. Die gelernten Daten sind jeweils schwarz<br />
bei (±1) eingezeichnet. In (d) ist die Entwicklung<br />
der subjektiven Zeit tL aus (b) dargestellt. Man<br />
sieht deutlich die Zeitspannen, während derer sie<br />
” stehenbleibt,“ weil keine relevanten Daten mehr<br />
gesehen werden. Der Datensatz besteht aus zwei<br />
Punktquellen bei (±1). Die Lernparameter sind<br />
mit TS/TL = 5.0, und σ = 0.8σS in (a) in der<br />
entarteten, in (b) und (c) dagegen bereits in der<br />
aufgespalteten Phase (vgl. Abb. 46).<br />
4.2.3 Dynamikentkopplung durch Zeitskalenkompression<br />
Die Verteilungsdichte des in Abb. 45 gelernten Datensatzes ist diejenige, die bereits in<br />
Abb. 42a, b präsentiert wurde. Beide Datencluster werden <strong>von</strong> der Schwelle αǫA abgeschnitten,<br />
und da sie gleiche Form und gleiches statistisches Gewicht haben, werden sie<br />
dadurch auch gleich stark komprimiert. Dasselbe findet in Abb. 46 statt, dort werden<br />
zwei punktförmige Datenquellen mit gleichen statistischen Gewichten komprimiert.<br />
Dass dieser Prozess nicht nur eine Kompression <strong>von</strong> statistischen Gewichten, sondern<br />
auch <strong>von</strong> Zeitskalen bedeutet, so wie sie in Abb. 7 als Ziel des Algorithmus vorgestellt<br />
wurde, kann am Beispiel aus Abbildung 47 demonstriert werden. Wieder besteht die<br />
Datenquelle aus zwei deterministisch abwechselnden Punktverteilungen. In Abb. 47a<br />
ist ein stark dynamisch gekoppelter Lernprozess, ähnlich demjenigen aus Abb. 26a1<br />
zu sehen. Es findet keine Aufspaltung statt, da sich der Lerner mit einem Zeitskalen-<br />
Verhältnis τS = 5.0 bei dem gegebenen Verhältnis der Breiten σ/σS = 0.8 über der<br />
Phasenübergangskurve befindet (vgl. Abb. 46).<br />
Zum Vergleich ist in Abb. 47b ein ANTS-Training mit fester Schwelle ǫA dargestellt,<br />
t<br />
tL

