

Green-IT und Datenbanken - ODBMS
Green-IT und Datenbanken - ODBMS
Green-IT und Datenbanken - ODBMS

Sie wollen auch ein ePaper? Erhöhen Sie die Reichweite Ihrer Titel.
YUMPU macht aus Druck-PDFs automatisch weboptimierte ePaper, die Google liebt.
6 Energieoptimierungen<br />
tentyp umgewandelt werden soll. Zur Umwandlung eines Log-Knotens in einen Disk-<br />
Knoten muss dieser mit seinen Log-Einträgen rekonstruiert <strong>und</strong> anschließend auf dem<br />
Flash-Speicher gespeichert werden. Zur Umwandlung eines Disk-Knotens in einen<br />
Log-Knoten wird der Knoten in den Speicher gelesen <strong>und</strong> in eine Menge von Logeinträgen<br />
zerlegt, die den Knoten repräsentieren. Diese Logeinträge werden dann<br />
im Puffer gespeichert. Da beim Umwandeln Kosten entstehen, sollten Knoten nicht<br />
unnötig umgewandelt werden. Der Algorithmus vergleicht die Kosten für einen Knoten<br />
eines bestimmten Typs mit den Kosten, die der andere Knotentyp verursacht<br />
hätte, <strong>und</strong> überprüft dann, ob sich die Kosten für einen Wechsel des Knotentyps lohnen.<br />
Außerdem berechnet der Algorithmus über ein Nutzen-Kosten-Verhältnis, unter<br />
Berücksichtigung der Lese- <strong>und</strong> Schreibkosten des Flash-Speichers, welche Knotengröße<br />
für den Baum zu wählen ist. Dies ist wichtig, da große Knoten die Höhe des<br />
Baumes reduzieren, aber pro Knoten mehr Informationen gelesen werden müssen<br />
<strong>und</strong> dadurch wieder höhere Kosten entstehen. Zusätzlich werden die Logeinträge des<br />
Baumes so verwaltet, dass unnötige Einträge verhindert werden, indem semantisch<br />
entgegengesetzte Befehle (z.B. ADD_KEY k <strong>und</strong> DELETE_KEY k) entfernt werden<br />
(Semantic Compaction) <strong>und</strong> alte Logeinträge durch Garbage-Collection gelöscht<br />
werden, um Speicherplatz zu schaffen.<br />
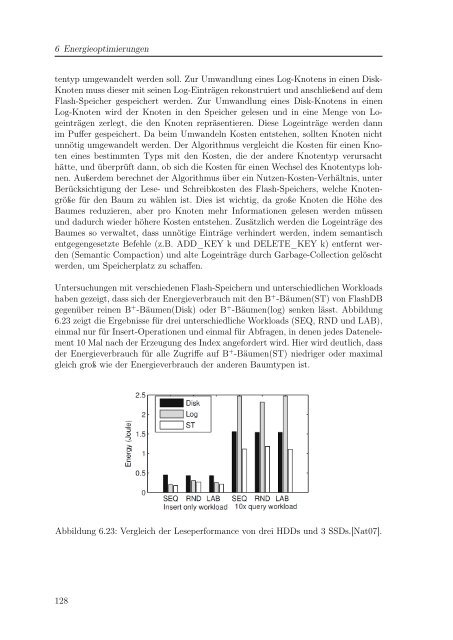
Untersuchungen mit verschiedenen Flash-Speichern <strong>und</strong> unterschiedlichen Workloads<br />
haben gezeigt, dass sich der Energieverbrauch mit den B + -Bäumen(ST) von FlashDB<br />
gegenüber reinen B + -Bäumen(Disk) oder B + -Bäumen(log) senken lässt. Abbildung<br />
6.23 zeigt die Ergebnisse für drei unterschiedliche Workloads (SEQ, RND <strong>und</strong> LAB),<br />
einmal nur für Insert-Operationen <strong>und</strong> einmal für Abfragen, in denen jedes Datenelement<br />
10 Mal nach der Erzeugung des Index angefordert wird. Hier wird deutlich, dass<br />
der Energieverbrauch für alle Zugriffe auf B + -Bäumen(ST) niedriger oder maximal<br />
gleich groß wie der Energieverbrauch der anderen Baumtypen ist.<br />
Abbildung 6.23: Vergleich der Leseperformance von drei HDDs <strong>und</strong> 3 SSDs.[Nat07].<br />
128








