

Studienführer r e v i t a n r e t l A vierter - fokus: DU
Studienführer r e v i t a n r e t l A vierter - fokus: DU
Studienführer r e v i t a n r e t l A vierter - fokus: DU

Erfolgreiche ePaper selbst erstellen
Machen Sie aus Ihren PDF Publikationen ein blätterbares Flipbook mit unserer einzigartigen Google optimierten e-Paper Software.
76<br />
Ein Teilgebiet der Intelligenten Datenanalyse<br />
ist die Wissensentdeckung in Datenbanken<br />
(auch „Data Mining“ genannt). Data Mining<br />
ist ein mittlerweile angewandtes Forschungsgebiet,<br />
dass sich als Antwort auf die Flut an<br />
Daten versteht, der wir heute gegenüberstehen.<br />
Es widmet sich der Herausforderung,<br />
Verfahren zu entwickeln, die Menschen helfen<br />
können, nützliche Muster in ihren Daten zu<br />
finden.<br />
Unsere Arbeitsgruppe „Computational Intelligence“<br />
befasst sich mit diesen Verfahren,<br />
wobei derzeit insbesondere neue Methoden<br />
zur „Intelligenten Datenanalyse“ erforscht<br />
werden. Wir nutzen häufig Techniken aus den<br />
Bereichen der Neuronalen Netze, der Fuzzy-<br />
Systeme, der Evolutionären Algorithmen, der<br />
Bayesschen Netze und des approximativen<br />
Schließens. Diese Methoden sind besonders<br />
geeignet, in Anwendungen einfach zu handhabende,<br />
robuste und günstige Problemlösungen<br />
zu finden.<br />
So profitieren beispielsweise Mediziner, Bank-<br />
oder Versicherungsangestellte von solchen<br />
gelernten Modellen, wenn Sie anhand gegebener<br />
Fakten Entscheidungen über Krankheiten,<br />
Kreditwürdigkeiten bzw. Versicherungsbetrüge<br />
treffen müssen. Unsere<br />
Arbeitsgruppe analysiert<br />
solche realen Prozesse und<br />
die daraus resultierende Daten,<br />
um Lösungen zu entwickeln,<br />
welche die Entscheidungen<br />
in wissensbasierten<br />
Systemen erleichtern können.<br />
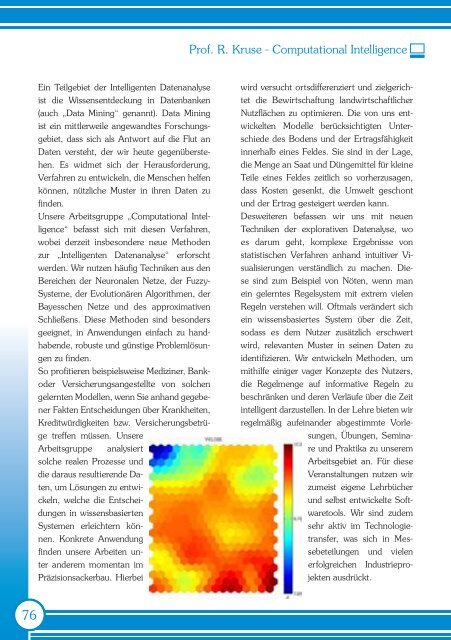
Konkrete Anwendung<br />
finden unsere Arbeiten unter<br />
anderem momentan im<br />
Präzisionsackerbau. Hierbei<br />
Prof. R. Kruse - Computational Intelligence<br />
wird versucht ortsdifferenziert und zielgerichtet<br />
die Bewirtschaftung landwirtschaftlicher<br />
Nutzflächen zu optimieren. Die von uns entwickelten<br />
Modelle berücksichtigten Unterschiede<br />
des Bodens und der Ertragsfähigkeit<br />
innerhalb eines Feldes. Sie sind in der Lage,<br />
die Menge an Saat und Düngemittel für kleine<br />
Teile eines Feldes zeitlich so vorherzusagen,<br />
dass Kosten gesenkt, die Umwelt geschont<br />
und der Ertrag gesteigert werden kann.<br />
Desweiteren befassen wir uns mit neuen<br />
Techniken der explorativen Datenalyse, wo<br />
es darum geht, komplexe Ergebnisse von<br />
statistischen Verfahren anhand intuitiver Visualisierungen<br />
verständlich zu machen. Diese<br />
sind zum Beispiel von Nöten, wenn man<br />
ein gelerntes Regelsystem mit extrem vielen<br />
Regeln verstehen will. Oftmals verändert sich<br />
ein wissensbasiertes System über die Zeit,<br />
sodass es dem Nutzer zusätzlich erschwert<br />
wird, relevanten Muster in seinen Daten zu<br />
identifizieren. Wir entwickeln Methoden, um<br />
mithilfe einiger vager Konzepte des Nutzers,<br />
die Regelmenge auf informative Regeln zu<br />
beschränken und deren Verläufe über die Zeit<br />
intelligent darzustellen. In der Lehre bieten wir<br />
regelmäßig aufeinander abgestimmte Vorlesungen,<br />
Übungen, Seminare<br />
und Praktika zu unserem<br />
Arbeitsgebiet an. Für diese<br />
Veranstaltungen nutzen wir<br />
zumeist eigene Lehrbücher<br />
und selbst entwickelte Softwaretools.<br />
Wir sind zudem<br />
sehr aktiv im Technologietransfer,<br />
was sich in Messebeteilungen<br />
und vielen<br />
erfolgreichen Industrieprojekten<br />
ausdrückt.









