

Ein Computerlinguistisches Lexikon als komplexes System
Ein Computerlinguistisches Lexikon als komplexes System
Ein Computerlinguistisches Lexikon als komplexes System

Erfolgreiche ePaper selbst erstellen
Machen Sie aus Ihren PDF Publikationen ein blätterbares Flipbook mit unserer einzigartigen Google optimierten e-Paper Software.
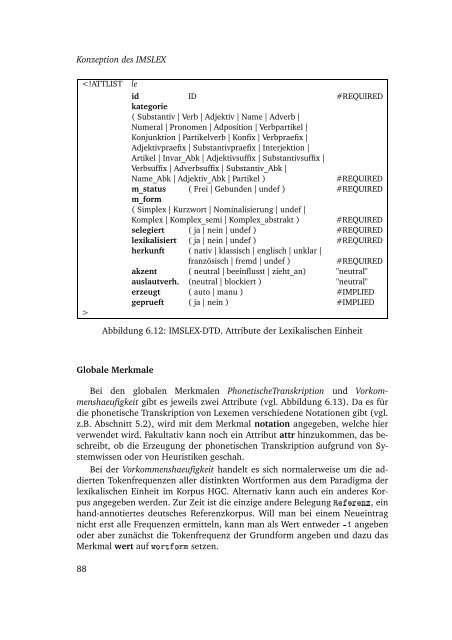
Konzeption des IMSLEX<br />
<br />
le<br />
id ID #REQUIRED<br />
kategorie<br />
( Substantiv | Verb | Adjektiv | Name | Adverb |<br />
Numeral | Pronomen | Adposition | Verbpartikel |<br />
Konjunktion | Partikelverb | Konfix | Verbpraefix |<br />
Adjektivpraefix | Substantivpraefix | Interjektion |<br />
Artikel | Invar_Abk | Adjektivsuffix | Substantivsuffix |<br />
Verbsuffix | Adverbsuffix | Substantiv_Abk |<br />
Name_Abk | Adjektiv_Abk | Partikel )<br />
#REQUIRED<br />
m_status ( Frei | Gebunden | undef ) #REQUIRED<br />
m_form<br />
( Simplex | Kurzwort | Nominalisierung | undef |<br />
Komplex | Komplex_semi | Komplex_abstrakt ) #REQUIRED<br />
selegiert ( ja | nein | undef ) #REQUIRED<br />
lexikalisiert ( ja | nein | undef ) #REQUIRED<br />
herkunft ( nativ | klassisch | englisch | unklar |<br />
französisch | fremd | undef )<br />
#REQUIRED<br />
akzent ( neutral | beeinflusst | zieht_an) "neutral"<br />
auslautverh. (neutral | blockiert ) "neutral"<br />
erzeugt ( auto | manu ) #IMPLIED<br />
geprueft ( ja | nein ) #IMPLIED<br />
Abbildung 6.12: IMSLEX-DTD. Attribute der Lexikalischen <strong>Ein</strong>heit<br />
Globale Merkmale<br />
Bei den globalen Merkmalen PhonetischeTranskription und Vorkommenshaeufigkeit<br />
gibt es jeweils zwei Attribute (vgl. Abbildung 6.13). Da es für<br />
die phonetische Transkription von Lexemen verschiedene Notationen gibt (vgl.<br />
z.B. Abschnitt 5.2), wird mit dem Merkmal notation angegeben, welche hier<br />
verwendet wird. Fakultativ kann noch ein Attribut attr hinzukommen, das beschreibt,<br />
ob die Erzeugung der phonetischen Transkription aufgrund von <strong>System</strong>wissen<br />
oder von Heuristiken geschah.<br />
Bei der Vorkommenshaeufigkeit handelt es sich normalerweise um die addierten<br />
Tokenfrequenzen aller distinkten Wortformen aus dem Paradigma der<br />
lexikalischen <strong>Ein</strong>heit im Korpus HGC. Alternativ kann auch ein anderes Korpus<br />
angegeben werden. Zur Zeit ist die einzige andere Belegung ¤£ ¡ £ ¦ £¤¥¤ , ein<br />
hand-annotiertes deutsches Referenzkorpus. Will man bei einem Neueintrag<br />
nicht erst alle Frequenzen ermitteln, kann man <strong>als</strong> Wert entweder ¢ ¤ angeben<br />
oder aber zunächst die Tokenfrequenz der Grundform angeben und dazu das<br />
Merkmal wert auf ¦ ¡ ¡ ¦ setzen.<br />
88













