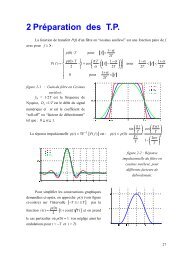
CHAPITRE V. CHAÎNES CONDITIONNELLEMENT LINÉAIRES À SAUTSMARKOVIENS21.510.50R0 (CCPM)−0.5−10 50 100 150 200 250 300 350 400 450 500(a”)21.510.50R1 (CCPM)−0.5−10 50 100 150 200 250 300 350 400 450 500(b”)21.510.5R2 (CCPM)0−0.5−10 50 100 150 200 250 300 350 400 450 500(c”)Figure V.5 – Segm<strong>en</strong>tation non supervisée par CCLSM-GMLLes taux d’erreur <strong>de</strong> ces expéri<strong>en</strong>ces sont résumés dans la table (V.1). Nouspouvons remarquer que les <strong>de</strong>ux modèles ont la même performance que dans le cas(a), par contre dans les <strong>de</strong>ux autres cas(b) et(c), le modèle CCPM à mémoirelongue est plus performant du fait que le modèle CMC ne pr<strong>en</strong>d pas <strong>en</strong> contre lesdonnées corrélées.116
CHAPITRE V. CHAÎNES CONDITIONNELLEMENT LINÉAIRES À SAUTSMARKOVIENSCMC-BI CCLSM-GMLy 1 1∶N0.2 0.2y 2 1∶N61.6 2.0y 3 1∶N13.6 5.1Table V.1 – Taux d’erreur <strong>de</strong> segm<strong>en</strong>tations <strong>en</strong> %Finalem<strong>en</strong>t, nous appliquons l’algorithme <strong>de</strong> lissage pour calculer E[X n ∣y 1∶N ]selon le modèle :∀2≤n≤N, X n =F n (R n ,Y n )X n−1 +G n (R n ,Y n )V n +H n (R n ,Y n ) (V.24)avec pour tout 2≤n≤N, F n (ω 1 ,Y n )= 3×Yn10 , F n(ω 2 ,Y n )=− 3×Yn10 ,H n(ω 1 ,Y n )= 1 2 ,H n (ω 2 ,Y n )=− 1 2 et G n(R n ,Y n )= 1 2 et V n∼N(0,1).Pour chacun <strong>de</strong>s trois cas (a), (b), et (c) <strong>de</strong> la figure (V.3), on procè<strong>de</strong> au lissagepar la nouvelle métho<strong>de</strong> générale. Les résultats obt<strong>en</strong>us sont prés<strong>en</strong>tés sur lafigure (V.5), respectivem<strong>en</strong>t <strong>en</strong> a”, b”, et c”. Dans chaque cas on prés<strong>en</strong>te <strong>de</strong>ux trajectoires: la vraie (X= x simulée selon (V.24)) et l’estimée (à R inconnu). L’écart<strong>en</strong>tre les <strong>de</strong>ux trajectoires est mesuré par l’erreur quadratique moy<strong>en</strong>ne (eq) qui est,respectivem<strong>en</strong>t, <strong>de</strong> 0.60, 0.60, et 0.61. Nous cherchons à comparer notre métho<strong>de</strong>avec celle utilisant la vraie trajectoire <strong>de</strong>s sauts donné à la figure (V.2) Sur la figure(V.7), nous prés<strong>en</strong>tons ainsi les trajectoires du processus X calculées <strong>en</strong> utilisant levrai processus R et les observations y1∶N i avec les trajectoires estimées par le lissage( figure (V.6)). Pour tout i=1,2,3, la trajectoire estimée connaissant la trajectoire<strong>de</strong>s sauts se calcule simplem<strong>en</strong>t par :∀2≤n≤N,x i n=F n (r n ,y i n)x i n−1+H n (r n ,y i n)(V.25)Les résultats obt<strong>en</strong>us sont prés<strong>en</strong>tés sur la figure (V.6), respectivem<strong>en</strong>t <strong>en</strong> a”’,b”’, et c”’. Comme à la figure (V.7), dans chaque cas on prés<strong>en</strong>te <strong>de</strong>ux trajectoires :la vraie (X= x simulée selon (V.24)) et l’estimée (à R connu) par (V.25). L’écart<strong>en</strong>tre les <strong>de</strong>ux trajectoires est mesuré par l’erreur quadratique moy<strong>en</strong>ne (eq) qui est,respectivem<strong>en</strong>t, <strong>de</strong> 0.39, 0.27, et 0.29.Naturellem<strong>en</strong>t, les résultats obt<strong>en</strong>us avec la trajectoire <strong>de</strong>s sauts connue donne<strong>de</strong> meilleurs résultats; cep<strong>en</strong>dant, la différ<strong>en</strong>ce n’est pas très gran<strong>de</strong> et visuellem<strong>en</strong>tles résultats sont assez proches.Rappelons que les résultats <strong>de</strong> la Figure 5.7 sont obt<strong>en</strong>us <strong>de</strong> manière "semisupervisée": la loi <strong>de</strong>(R,Y) est estimée, mais les paramètres F n , B n et G n sontconnus.117