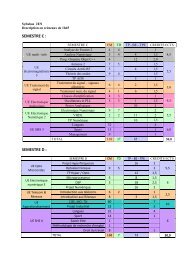
cours et TD - Enseeiht
cours et TD - Enseeiht
cours et TD - Enseeiht
- No tags were found...

Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
3. ESTIMATIONS DES PRINCIPAUX PARAMÈTRES 119Exemple 3.2.7. On se propose de déterminer la quantité d’olives que l’on doit prendre pour pouvoir estimer àune décimale près la teneur en huile (exprimée en pourcentage du poids frais). Comme nous n’avons au départaucune information, nous prenons, dans un premier temps 100 olives. On suppose que la variable aléatoire ”teneuren huile” suit une loi normale. Après avoir analysé celles-ci, nous avons obtenu : ȳ = 28.5% <strong>et</strong> ˆσ = 5.7%. Nousprenons α = 0.05. L’intervalle de confiance de µ au niveau 0.95 est alors de[]5.75.728.5 − t 1−α/2 √ ; 28.5 + t 1−α/2 √ = [28.5 − 1.12; 28.5 + 1.12]100 100n = 100 est donc trop p<strong>et</strong>it. Déterminons maintenant la taille de l’échantillon nécessaire. Nous conservons l’estimationde σ obtenue lors de notre première expérience <strong>et</strong> nous remplaçons t 1−α/2 par u 1−α/2 dans l’équation (6.2).Nous obtenons ainsi1.96 × 5.7d = = 0.1nsoitn ≃ 13000On vérifie a posteriori que la valeur de n est grande <strong>et</strong> donc que l’approximation de t 1−α/2 par u 1−α/2 est correcte.Si n est faible, il faut itérer pour trouver la solution de l’équation (6.2).3.3 Estimation d’une proportionThéorème 3.3.1. Soit P e un problème d’estimation où X est une variable aléatoire de loi de Bernoulli B(p) alors(i)Ȳ est un estimateur sans biais <strong>et</strong> convergent du paramètre p <strong>et</strong> l’estimation ponctuelle est donc donnée parˆp = k obsn ;(ii) si l’échantillonnage est avec remise l’intervalle de confiance au niveau (1 − α) est donné par p ∈ [p 1 ; p 2 ] oùp 1 <strong>et</strong> p 2 sont déterminés par :<strong>et</strong>P (Ȳ ≥ k obsn ) =n∑i=k obsC i np i 2(1 − p 2 ) n−i = α/2 (6.3)P (Ȳ ≤ k k obsobsn ) = ∑Cnp i i 1(1 − p 1 ) n−i = α/2 (6.4)i=1DémonstrationCela provient tout simplement de la théorie de l’échantillonnage <strong>et</strong> pour (ii) du fait que nȲ suit une loi binômiale.✷Les équations 6.3 <strong>et</strong> 6.4 sont difficiles à résoudre <strong>et</strong> on sait que l’on peut souvent en pratique approximerune loi binômiale ou hypergéométrique par une loi normale d’où la proposition suivante. Nous notons dans c<strong>et</strong>teproposition ˆσ p l’estimation de la variance de ¯X qui est données par :(i) ˆσ p 2 = ˆpˆq si l’échantillonnage est avec remise ;n − 1(ii) ˆσ p 2 = ˆpˆq N − nsi l’échantillonnage est sans remise.n − 1 NProposition 3.3.2. Soit P e un problème d’estimation où X est une variable aléatoire de loi de Bernoulli B(p). Sin est supérieur aux valeurs mentionnées dans la table 6.3 alors l’intervalle de confiance est données par[p ∈ ˆp − u 1−α/2ˆσ p − 12n ; ˆp + u 1−α/2ˆσ p + 1 ]au niveau (1 − α)2nDémonstrationPuisque l’on peut faire l’approximation par une loi normale on obtient l’intervalle en prenant l’intervalle de confianced’une moyenne. Le terme 12nest un terme de correction de non continuité [3] ✷Remarque 3.3.3. (i) Pour les valeurs de n inférieures à 100 <strong>et</strong> pour n/N < 0.1 on a construit des tablesstatistiques qu’il suffit d’aller consulter.(ii) pour les valeurs de p très proche de 0 on peut aussi utiliser l’approximation de la loi binômiale par une loi depoisson.