cours et TD - Enseeiht
cours et TD - Enseeiht
cours et TD - Enseeiht
- No tags were found...

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
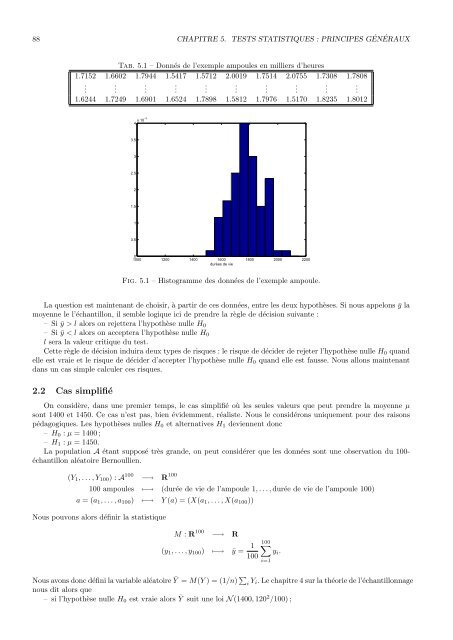
88 CHAPITRE 5. TESTS STATISTIQUES : PRINCIPES GÉNÉRAUXTab. 5.1 – Donnés de l’exemple ampoules en milliers d’heures1.7152 1.6602 1.7944 1.5417 1.5712 2.0019 1.7514 2.0755 1.7308 1.7808. . . . . . . . . .1.6244 1.7249 1.6901 1.6524 1.7898 1.5812 1.7976 1.5170 1.8235 1.80124 x 10−3 durées de vie3.532.521.510.501000 1200 1400 1600 1800 2000 2200Fig. 5.1 – Histogramme des données de l’exemple ampoule.La question est maintenant de choisir, à partir de ces données, entre les deux hypothèses. Si nous appelons ȳ lamoyenne le l’échantillon, il semble logique ici de prendre la règle de décision suivante :– Si ȳ > l alors on rej<strong>et</strong>tera l’hypothèse nulle H 0– Si ȳ < l alors on acceptera l’hypothèse nulle H 0l sera la valeur critique du test.C<strong>et</strong>te règle de décision induira deux types de risques : le risque de décider de rej<strong>et</strong>er l’hypothèse nulle H 0 quandelle est vraie <strong>et</strong> le risque de décider d’accepter l’hypothèse nulle H 0 quand elle est fausse. Nous allons maintenantdans un cas simple calculer ces risques.2.2 Cas simplifiéOn considère, dans une premier temps, le cas simplifié où les seules valeurs que peut prendre la moyenne µsont 1400 <strong>et</strong> 1450. Ce cas n’est pas, bien évidemment, réaliste. Nous le considérons uniquement pour des raisonspédagogiques. Les hypothèses nulles H 0 <strong>et</strong> alternatives H 1 deviennent donc– H 0 : µ = 1400 ;– H 1 : µ = 1450.La population A étant supposé très grande, on peut considérer que les données sont une observation du 100-échantillon aléatoire Bernoullien.(Y 1 , . . . , Y 100 ) : A 100 −→ R 100100 ampoules ↦−→ (durée de vie de l’ampoule 1, . . . , durée de vie de l’ampoule 100)a = (a 1 , . . . , a 100 ) ↦−→ Y (a) = (X(a 1 , . . . , X(a 100 ))Nous pouvons alors définir la statistiqueM : R 100 −→ R(y 1 , . . . , y 100 ) ↦−→ ȳ = 1100∑100y i .i=1Nous avons donc défini la variable aléatoire Ȳ = M(Y ) = (1/n) ∑ i Y i. Le chapitre 4 sur la théorie de l’échantillonnagenous dit alors que– si l’hypothèse nulle H 0 est vraie alors Ȳ suit une loi N (1400, 1202 /100) ;