

pdf-file, 2.03 Mbyte - Torsten Schütze
pdf-file, 2.03 Mbyte - Torsten Schütze
pdf-file, 2.03 Mbyte - Torsten Schütze

Sie wollen auch ein ePaper? Erhöhen Sie die Reichweite Ihrer Titel.
YUMPU macht aus Druck-PDFs automatisch weboptimierte ePaper, die Google liebt.
46 Kapitel 2. Univariate Splines<br />
2.2<br />
2<br />
1.8<br />
1.6<br />
1.4<br />
1.2<br />
1<br />
0.8<br />
0.6<br />
600 650 700 750 800 850 900 950 1000 1050<br />
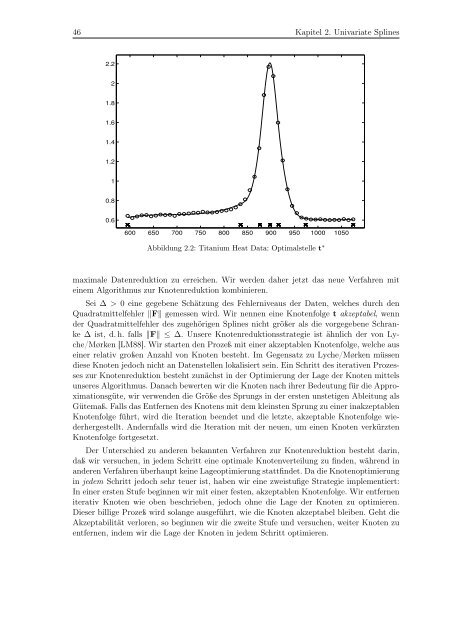
Abbildung 2.2: Titanium Heat Data: Optimalstelle t ∗<br />
maximale Datenreduktion zu erreichen. Wir werden daher jetzt das neue Verfahren mit<br />
einem Algorithmus zur Knotenreduktion kombinieren.<br />
Sei ∆ > 0 eine gegebene Schätzung des Fehlerniveaus der Daten, welches durch den<br />
Quadratmittelfehler F gemessen wird. Wir nennen eine Knotenfolge t akzeptabel, wenn<br />
der Quadratmittelfehler des zugehörigen Splines nicht größer als die vorgegebene Schranke<br />
∆ ist, d. h. falls F ≤ ∆. Unsere Knotenreduktionsstrategie ist ähnlich der von Lyche/Mørken<br />
[LM88]. Wir starten den Prozeß mit einer akzeptablen Knotenfolge, welche aus<br />
einer relativ großen Anzahl von Knoten besteht. Im Gegensatz zu Lyche/Mørken müssen<br />
diese Knoten jedoch nicht an Datenstellen lokalisiert sein. Ein Schritt des iterativen Prozesses<br />
zur Knotenreduktion besteht zunächst in der Optimierung der Lage der Knoten mittels<br />
unseres Algorithmus. Danach bewerten wir die Knoten nach ihrer Bedeutung für die Approximationsgüte,<br />
wir verwenden die Größe des Sprungs in der ersten unstetigen Ableitung als<br />
Gütemaß. Falls das Entfernen des Knotens mit dem kleinsten Sprung zu einer inakzeptablen<br />
Knotenfolge führt, wird die Iteration beendet und die letzte, akzeptable Knotenfolge wiederhergestellt.<br />
Andernfalls wird die Iteration mit der neuen, um einen Knoten verkürzten<br />
Knotenfolge fortgesetzt.<br />
Der Unterschied zu anderen bekannten Verfahren zur Knotenreduktion besteht darin,<br />
daß wir versuchen, in jedem Schritt eine optimale Knotenverteilung zu finden, während in<br />
anderen Verfahren überhaupt keine Lageoptimierung stattfindet. Da die Knotenoptimierung<br />
in jedem Schritt jedoch sehr teuer ist, haben wir eine zweistufige Strategie implementiert:<br />
In einer ersten Stufe beginnen wir mit einer festen, akzeptablen Knotenfolge. Wir entfernen<br />
iterativ Knoten wie oben beschrieben, jedoch ohne die Lage der Knoten zu optimieren.<br />
Dieser billige Prozeß wird solange ausgeführt, wie die Knoten akzeptabel bleiben. Geht die<br />
Akzeptabilität verloren, so beginnen wir die zweite Stufe und versuchen, weiter Knoten zu<br />
entfernen, indem wir die Lage der Knoten in jedem Schritt optimieren.

