5 Details zur Implementierung und Messergebnisseweitestgehend vernachlässigt werden.Verfahren Schritte Zeiten‖x‖Fluss: 2‖x min ‖ 2ALiCE PSC PC-Cluster Rand PeakAsync-FOS 341 1866 1333 1787 0,999 1Async-SOS 45 298 225 256 1 1Async-Čebyšev 37 255 196 215 1 1OPT 16 100 100 100 1,001 1FB-Async-OPT 16 51 60 57 1,001 1Async-OPS 16 95 74 90 1 1DE-FOS 17 153 152 123 1,02 1,037DE-OPT 8 39 56 54 1,002 1,001DE-OPTfb 8 42 60 57 1 1DE-OPTcc 8 42 62 57 1 1SDE-OPT 8 52 58 57 1,002 1,001DE-OPS 8 39 56 54 1,002 1,001Tabelle 5.2: Ergebnisse für den Zyklus C 32Der komplette Graph aus Tabelle 5.3 entspricht am ehesten der Topologie vieler Parallelrechner,bei denen <strong>mit</strong> <strong>Hilfe</strong> von Switches oder Crossbars jeder Prozessor <strong>mit</strong> jedemanderen gleichberechtigt kommunizieren kann. Allerdings ist es technisch ausgeschlossen,alle möglichen Verbindungen gleichzeitig zu benutzen. Da dieser Graph nur einen vonNull verschiedenen Eigenwert hat, sind Diffusionsverfahren hierfür relativ schnell. Dennochsteigt der Aufwand <strong>mit</strong> der Gesamtzahl der Prozessoren, da <strong>mit</strong> allen Nachbarneinmal kommuniziert werden muss. Für das nachfolgende Scheduling bedeutet dies, dassdie Lasten über wesentlich mehr Kanten verschoben werden als bei anderen Graphen.Nichtsdestotrotz ist <strong>Dimension</strong>-Exchange im Falle dieses speziellen Graphen den Diffusionsverfahrensowohl in Bezug <strong>auf</strong> die L<strong>auf</strong>zeiten als auch <strong>auf</strong> die Flüsse klar unterlegen.Die beiden wichtigsten Graphen sind sicherlich das Gitter G 8 in Tabelle 5.4 sowie derTorus T 8 in Tabelle 5.5, da man an diesen Beispielen (fast) alle Verfahren vergleichenkann und gerade der Torus in der Praxis als Topologie einiger Parallelrechner verwendetwird. Unter den Verfahren, die die Produktgraphstruktur nicht ausnutzen, sticht vorallem das DE-OPTcc hervor, das in vergleichsweise kurzer Zeit Flüsse berechnet, die nurwenig über dem Minimum liegen. Unter den ADI-Verfahren ist DE-ADC-OPT dasjenige,das geringe Zeiten und kleine Flüsse am besten vereint. Legt man ausschließlich Wert<strong>auf</strong> eine möglichst geringe L<strong>auf</strong>zeit, kommen vor allem FB-SDI-OPT und DE-ADI-OPTin Betracht; sollen die Flüsse möglichst klein gehalten werden, ist eher Async-ADC-OPS<strong>mit</strong> genügend großem η das Verfahren der Wahl, oder auch das wegen der komplexerenImplementierung nur für den Torus getestete DE-ADC-OPTcc. Die recht hohen Zeiten<strong>auf</strong> der PSC für Tori scheinen nicht repräsentativ zu sein und sollten nicht überbewertetwerden.Der Hypercube aus Tabelle 5.6 verhält sich ähnlich wie Gitter und Tori, auch hier istDE-OPTcc das zu bevorzugende Verfahren. Die <strong>auf</strong>geführten ADI-Verfahren sind zwar116
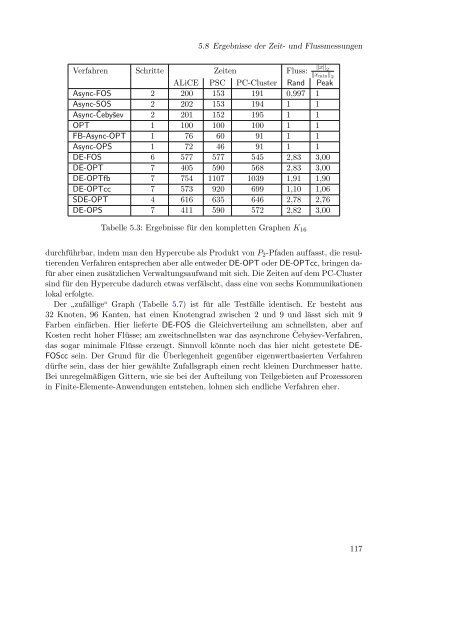
5.8 Ergebnisse der Zeit- und FlussmessungenVerfahren Schritte Zeiten‖x‖Fluss: 2‖x min ‖ 2ALiCE PSC PC-Cluster Rand PeakAsync-FOS 2 200 153 191 0,997 1Async-SOS 2 202 153 194 1 1Async-Čebyšev 2 201 152 195 1 1OPT 1 100 100 100 1 1FB-Async-OPT 1 76 60 91 1 1Async-OPS 1 72 46 91 1 1DE-FOS 6 577 577 545 2,83 3,00DE-OPT 7 405 590 568 2,83 3,00DE-OPTfb 7 754 1107 1039 1,91 1,90DE-OPTcc 7 573 920 699 1,10 1,06SDE-OPT 4 616 635 646 2,78 2,76DE-OPS 7 411 590 572 2,82 3,00Tabelle 5.3: Ergebnisse für den kompletten Graphen K 16durchführbar, indem man den Hypercube als Produkt von P 2 -Pfaden <strong>auf</strong>fasst, die resultierendenVerfahren entsprechen aber alle entweder DE-OPT oder DE-OPTcc, bringen dafüraber einen zusätzlichen Verwaltungs<strong>auf</strong>wand <strong>mit</strong> sich. Die Zeiten <strong>auf</strong> dem PC-Clustersind für den Hypercube dadurch etwas verfälscht, dass eine von sechs Kommunikationenlokal erfolgte.Der ”zufällige“ Graph (Tabelle 5.7) ist für alle Testfälle identisch. Er besteht aus32 Knoten, 96 Kanten, hat einen Knotengrad zwischen 2 und 9 und lässt sich <strong>mit</strong> 9Farben einfärben. Hier lieferte DE-FOS die Gleichverteilung am schnellsten, aber <strong>auf</strong>Kosten recht hoher Flüsse; am zweitschnellsten war das asynchrone Čebyšev-Verfahren,das sogar minimale Flüsse erzeugt. Sinnvoll könnte noch das hier nicht getestete DE-FOScc sein. Der Grund für die Überlegenheit gegenüber eigenwertbasierten Verfahrendürfte sein, dass der hier gewählte Zufallsgraph einen recht kleinen Durchmesser hatte.Bei unregelmäßigen Gittern, wie sie bei der Aufteilung von Teilgebieten <strong>auf</strong> Prozessorenin Finite-Elemente-Anwendungen entstehen, lohnen sich endliche Verfahren eher.117