

Reading Working Papers in Linguistics 4 (2000) - The University of ...
Reading Working Papers in Linguistics 4 (2000) - The University of ...
Reading Working Papers in Linguistics 4 (2000) - The University of ...

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
I. SINKA, M. GARMAN AND C. SCHELLETTER<br />
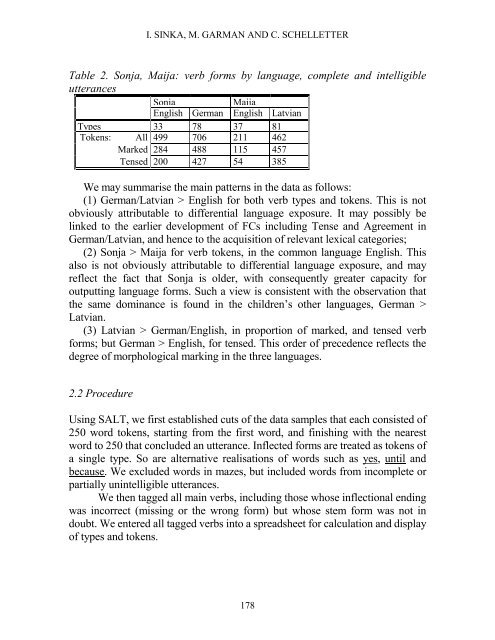
Table 2. Sonja, Maija: verb forms by language, complete and <strong>in</strong>telligible<br />
utterances<br />
Sonja<br />
Maija<br />
English German English Latvian<br />
Types 33 78 37 81<br />
Tokens: All 499 706 211 462<br />
Marked 284 488 115 457<br />
Tensed 200 427 54 385<br />
We may summarise the ma<strong>in</strong> patterns <strong>in</strong> the data as follows:<br />
(1) German/Latvian > English for both verb types and tokens. This is not<br />
obviously attributable to differential language exposure. It may possibly be<br />
l<strong>in</strong>ked to the earlier development <strong>of</strong> FCs <strong>in</strong>clud<strong>in</strong>g Tense and Agreement <strong>in</strong><br />
German/Latvian, and hence to the acquisition <strong>of</strong> relevant lexical categories;<br />
(2) Sonja > Maija for verb tokens, <strong>in</strong> the common language English. This<br />
also is not obviously attributable to differential language exposure, and may<br />
reflect the fact that Sonja is older, with consequently greater capacity for<br />
outputt<strong>in</strong>g language forms. Such a view is consistent with the observation that<br />
the same dom<strong>in</strong>ance is found <strong>in</strong> the children’s other languages, German ><br />
Latvian.<br />
(3) Latvian > German/English, <strong>in</strong> proportion <strong>of</strong> marked, and tensed verb<br />
forms; but German > English, for tensed. This order <strong>of</strong> precedence reflects the<br />
degree <strong>of</strong> morphological mark<strong>in</strong>g <strong>in</strong> the three languages.<br />
2.2 Procedure<br />
Us<strong>in</strong>g SALT, we first established cuts <strong>of</strong> the data samples that each consisted <strong>of</strong><br />
250 word tokens, start<strong>in</strong>g from the first word, and f<strong>in</strong>ish<strong>in</strong>g with the nearest<br />
word to 250 that concluded an utterance. Inflected forms are treated as tokens <strong>of</strong><br />
a s<strong>in</strong>gle type. So are alternative realisations <strong>of</strong> words such as yes, until and<br />
because. We excluded words <strong>in</strong> mazes, but <strong>in</strong>cluded words from <strong>in</strong>complete or<br />
partially un<strong>in</strong>telligible utterances.<br />
We then tagged all ma<strong>in</strong> verbs, <strong>in</strong>clud<strong>in</strong>g those whose <strong>in</strong>flectional end<strong>in</strong>g<br />
was <strong>in</strong>correct (miss<strong>in</strong>g or the wrong form) but whose stem form was not <strong>in</strong><br />
doubt. We entered all tagged verbs <strong>in</strong>to a spreadsheet for calculation and display<br />
<strong>of</strong> types and tokens.<br />
178













