

(SCI) - Technologie und Leistungsanalysen.pdf
(SCI) - Technologie und Leistungsanalysen.pdf
(SCI) - Technologie und Leistungsanalysen.pdf

Erfolgreiche ePaper selbst erstellen
Machen Sie aus Ihren PDF Publikationen ein blätterbares Flipbook mit unserer einzigartigen Google optimierten e-Paper Software.
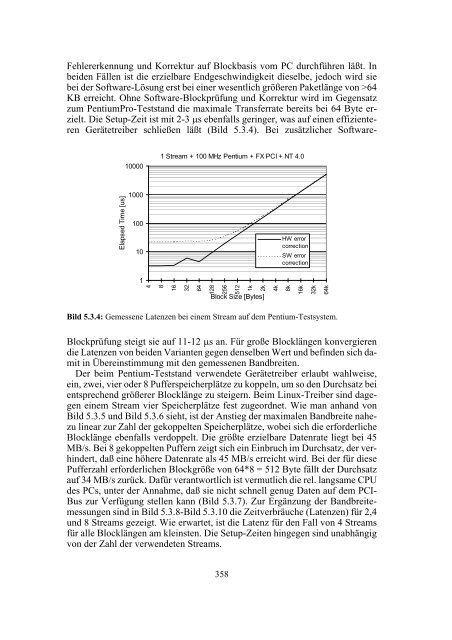
Fehlererkennung <strong>und</strong> Korrektur auf Blockbasis vom PC durchführen läßt. In<br />
beiden Fällen ist die erzielbare Endgeschwindigkeit dieselbe, jedoch wird sie<br />
bei der Software-Lösung erst bei einer wesentlich größeren Paketlänge von >64<br />
KB erreicht. Ohne Software-Blockprüfung <strong>und</strong> Korrektur wird im Gegensatz<br />
zum PentiumPro-Teststand die maximale Transferrate bereits bei 64 Byte erzielt.<br />
Die Setup-Zeit ist mit 2-3 s ebenfalls geringer, was auf einen effizienteren<br />
Gerätetreiber schließen läßt (Bild 5.3.4). Bei zusätzlicher Software-<br />
10000<br />
1 Stream + 100 MHz Pentium + FX PCI + NT 4.0<br />
Elapsed Time [us]<br />
1000<br />
100<br />
10<br />
HW error<br />
correction<br />
SW error<br />
correction<br />
1<br />
4<br />
8<br />
16<br />
32<br />
64<br />
128<br />
256<br />
512<br />
1k<br />
2k<br />
Block Size [Bytes]<br />
4k<br />
8k<br />
16k<br />
32k<br />
64k<br />
Bild 5.3.4: Gemessene Latenzen bei einem Stream auf dem Pentium-Testsystem.<br />
Blockprüfung steigt sie auf 11-12 s an. Für große Blocklängen konvergieren<br />
die Latenzen von beiden Varianten gegen denselben Wert <strong>und</strong> befinden sich damit<br />
in Übereinstimmung mit den gemessenen Bandbreiten.<br />
Der beim Pentium-Teststand verwendete Gerätetreiber erlaubt wahlweise,<br />
ein, zwei, vier oder 8 Pufferspeicherplätze zu koppeln, um so den Durchsatz bei<br />
entsprechend größerer Blocklänge zu steigern. Beim Linux-Treiber sind dagegen<br />
einem Stream vier Speicherplätze fest zugeordnet. Wie man anhand von<br />
Bild 5.3.5 <strong>und</strong> Bild 5.3.6 sieht, ist der Anstieg der maximalen Bandbreite nahezu<br />
linear zur Zahl der gekoppelten Speicherplätze, wobei sich die erforderliche<br />
Blocklänge ebenfalls verdoppelt. Die größte erzielbare Datenrate liegt bei 45<br />
MB/s. Bei 8 gekoppelten Puffern zeigt sich ein Einbruch im Durchsatz, der verhindert,<br />
daß eine höhere Datenrate als 45 MB/s erreicht wird. Bei der für diese<br />
Pufferzahl erforderlichen Blockgröße von 64*8 = 512 Byte fällt der Durchsatz<br />
auf 34 MB/s zurück. Dafür verantwortlich ist vermutlich die rel. langsame CPU<br />
des PCs, unter der Annahme, daß sie nicht schnell genug Daten auf dem PCI-<br />
Bus zur Verfügung stellen kann (Bild 5.3.7). Zur Ergänzung der Bandbreitemessungen<br />
sind in Bild 5.3.8-Bild 5.3.10 die Zeitverbräuche (Latenzen) für 2,4<br />
<strong>und</strong> 8 Streams gezeigt. Wie erwartet, ist die Latenz für den Fall von 4 Streams<br />
für alle Blocklängen am kleinsten. Die Setup-Zeiten hingegen sind unabhängig<br />
von der Zahl der verwendeten Streams.<br />
358













