Prognosemetoder – en oversikt - Telenor
Prognosemetoder – en oversikt - Telenor
Prognosemetoder – en oversikt - Telenor

Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
001.18:621.39<br />
134<br />
Prognoser for abonnem<strong>en</strong>tsetterspørsel<br />
AV CARLO HJELKREM OG JOHANNES BØE<br />
1 Behandling av grunnlagsdata,<br />
data på etterspørselsform<br />
Arbeidet med forslag til etterspørselsprognos<strong>en</strong>e<br />
begynner med et betydelig<br />
forarbeid i form av behandling av<br />
grunnlagsdata på s<strong>en</strong>tralområd<strong>en</strong>ivå. Vi<br />
skal her anta at dette arbeidet er utført,<br />
dvs at vi har data på etterspørselsform,<br />
og at ev<strong>en</strong>tuelle korrigeringer for nummerlån<br />
og justeringer for gr<strong>en</strong>sejusteringer<br />
er foretatt. Se [1], hvor dette er diskutert.<br />
Når vi nå har data på (riktig) etterspørselsform<br />
kan vi lage prognoser, <strong>en</strong>t<strong>en</strong> ved<br />
at tidsrekk<strong>en</strong> først analyseres med tanke<br />
på å bygge <strong>en</strong> prognosemodell eller ved<br />
at <strong>en</strong> allerede innarbeidet prognosemodell<br />
b<strong>en</strong>yttes. Vi skal her pres<strong>en</strong>tere <strong>en</strong>kelte<br />
resultater fra dette arbeidet i Region<br />
Oslo.<br />
Sid<strong>en</strong> prognosearbeidet stadig er under<br />
utvikling, blir beskrivels<strong>en</strong>e ned<strong>en</strong>for<br />
eksempler på hvordan prognos<strong>en</strong>e kan<br />
lages med data fra Region Oslo: No<strong>en</strong> av<br />
framgangsmåt<strong>en</strong>e er allerede fraveket<br />
idet du leser dette, fordi nye metoder er<br />
utprøvd og ny informasjon er tatt i bruk.<br />
Likevel vil dette være eksempler på<br />
anv<strong>en</strong>delse av no<strong>en</strong> av de prognosemetod<strong>en</strong>e<br />
som er pres<strong>en</strong>tert andre steder i<br />
d<strong>en</strong>ne utgav<strong>en</strong> av Telektronikk.<br />
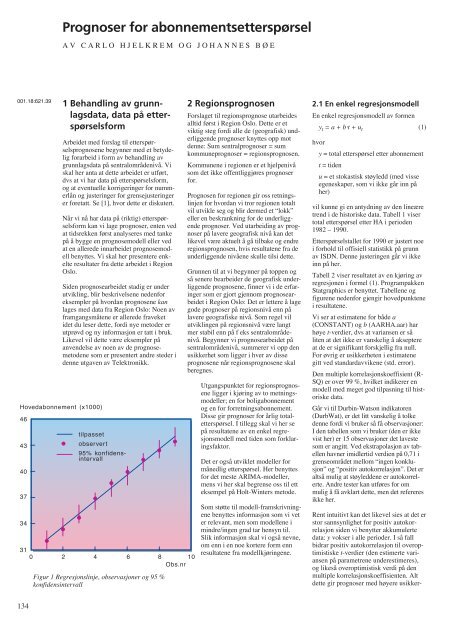
Hovedabonnem<strong>en</strong>t (x1000)<br />
46<br />
43<br />
40<br />
37<br />
34<br />
31<br />
0<br />
tilpasset<br />
observert<br />
95% konfid<strong>en</strong>sintervall<br />
2 4 6 8 10<br />
Obs.nr<br />
Figur 1 Regresjonslinje, observasjoner og 95 %<br />
konfid<strong>en</strong>sintervall<br />
2 Regionsprognos<strong>en</strong><br />
Forslaget til regionsprognose utarbeides<br />
alltid først i Region Oslo. Dette er et<br />
viktig steg fordi alle de (geografisk) underligg<strong>en</strong>de<br />
prognoser knyttes opp mot<br />
d<strong>en</strong>ne: Sum s<strong>en</strong>tralprognoser = sum<br />
kommuneprognoser = regionsprognos<strong>en</strong>.<br />
Kommun<strong>en</strong>e i region<strong>en</strong> er et hjelp<strong>en</strong>ivå<br />
som det ikke off<strong>en</strong>tliggjøres prognoser<br />
for.<br />
Prognos<strong>en</strong> for region<strong>en</strong> gir oss retningslinj<strong>en</strong><br />
for hvordan vi tror region<strong>en</strong> totalt<br />
vil utvikle seg og blir dermed et “lokk”<br />
eller <strong>en</strong> beskrankning for de underligg<strong>en</strong>de<br />
prognoser. Ved utarbeiding av prognoser<br />
på lavere geografisk nivå kan det<br />
likevel være aktuelt å gå tilbake og <strong>en</strong>dre<br />
regionsprognos<strong>en</strong>, hvis resultat<strong>en</strong>e fra de<br />
underligg<strong>en</strong>de nivå<strong>en</strong>e skulle tilsi dette.<br />
Grunn<strong>en</strong> til at vi begynner på topp<strong>en</strong> og<br />
så s<strong>en</strong>ere bearbeider de geografisk underligg<strong>en</strong>de<br />
prognos<strong>en</strong>e, finner vi i de erfaringer<br />
som er gjort gj<strong>en</strong>nom prognosearbeidet<br />
i Region Oslo: Det er lettere å lage<br />
gode prognoser på regionsnivå <strong>en</strong>n på<br />
lavere geografiske nivå. Som regel vil<br />
utvikling<strong>en</strong> på regionsnivå være langt<br />
mer stabil <strong>en</strong>n på f eks s<strong>en</strong>tralområd<strong>en</strong>ivå.<br />
Begynner vi prognosearbeidet på<br />
s<strong>en</strong>tralområd<strong>en</strong>ivå, summerer vi opp d<strong>en</strong><br />
usikkerhet som ligger i hver av disse<br />
prognos<strong>en</strong>e når regionsprognos<strong>en</strong>e skal<br />
beregnes.<br />
Utgangspunktet for regionsprognos<strong>en</strong>e<br />
ligger i kjøring av to metningsmodeller;<br />
<strong>en</strong> for boligabonnem<strong>en</strong>t<br />
og <strong>en</strong> for forretningsabonnem<strong>en</strong>t.<br />
Disse gir prognoser for årlig totaletterspørsel.<br />
I tillegg skal vi her se<br />
på resultat<strong>en</strong>e av <strong>en</strong> <strong>en</strong>kel regresjonsmodell<br />
med tid<strong>en</strong> som forklaringsfaktor.<br />
Det er også utviklet modeller for<br />
månedlig etterspørsel. Her b<strong>en</strong>yttes<br />
for det meste ARIMA-modeller,<br />
m<strong>en</strong>s vi her skal begr<strong>en</strong>se oss til ett<br />
eksempel på Holt-Winters metode.<br />
Som støtte til modell-framskrivning<strong>en</strong>e<br />
b<strong>en</strong>yttes informasjon som vi vet<br />
er relevant, m<strong>en</strong> som modell<strong>en</strong>e i<br />
mindre/ing<strong>en</strong> grad tar h<strong>en</strong>syn til.<br />
Slik informasjon skal vi også nevne,<br />
om <strong>en</strong>n i <strong>en</strong> noe kortere form <strong>en</strong>n<br />
resultat<strong>en</strong>e fra modellkjøring<strong>en</strong>e.<br />
2.1 En <strong>en</strong>kel regresjonsmodell<br />
En <strong>en</strong>kel regresjonsmodell av form<strong>en</strong><br />
yt = a + b⋅t + ut (1)<br />
hvor<br />
y = total etterspørsel etter abonnem<strong>en</strong>t<br />
t = tid<strong>en</strong><br />
u = et stokastisk støyledd (med visse<br />
eg<strong>en</strong>eskaper, som vi ikke går inn på<br />
her)<br />
vil kunne gi <strong>en</strong> antydning av d<strong>en</strong> lineære<br />
tr<strong>en</strong>d i de historiske data. Tabell 1 viser<br />
total etterspørsel etter HA i period<strong>en</strong><br />
1982 <strong>–</strong> 1990.<br />
Etterspørselstallet for 1990 er justert noe<br />
i forhold til offisiell statistikk på grunn<br />
av ISDN. D<strong>en</strong>ne justering<strong>en</strong> går vi ikke<br />
inn på her.<br />
Tabell 2 viser resultatet av <strong>en</strong> kjøring av<br />
regresjon<strong>en</strong> i formel (1). Programpakk<strong>en</strong><br />
Statgraphics er b<strong>en</strong>yttet. Tabell<strong>en</strong>e og<br />
figur<strong>en</strong>e ned<strong>en</strong>for gj<strong>en</strong>gir hovedpunkt<strong>en</strong>e<br />
i resultat<strong>en</strong>e.<br />
Vi ser at estimat<strong>en</strong>e for både a<br />
(CONSTANT) og b (AARHA.aar) har<br />
høye t-verdier, dvs at varians<strong>en</strong> er så<br />
lit<strong>en</strong> at det ikke er vanskelig å akseptere<br />
at de er signifikant forskjellig fra null.<br />
For øvrig er usikkerhet<strong>en</strong> i estimat<strong>en</strong>e<br />
gitt ved standardavvik<strong>en</strong>e (std. error).<br />
D<strong>en</strong> multiple korrelasjonskoeffisi<strong>en</strong>t (R-<br />
SQ) er over 99 %, hvilket indikerer <strong>en</strong><br />
modell med meget god tilpasning til historiske<br />
data.<br />
Går vi til Durbin-Watson indikator<strong>en</strong><br />
(DurbWat), er det litt vanskelig å tolke<br />
d<strong>en</strong>ne fordi vi bruker så få observasjoner:<br />
I d<strong>en</strong> tabell<strong>en</strong> som vi bruker (d<strong>en</strong> er ikke<br />
vist her) er 15 observasjoner det laveste<br />
som er angitt. Ved ekstrapolasjon av tabell<strong>en</strong><br />
havner imidlertid verdi<strong>en</strong> på 0,71 i<br />
gr<strong>en</strong>seområdet mellom “ing<strong>en</strong> konklusjon”<br />
og “positiv autokorrelasjon”. Det er<br />
altså mulig at støyledd<strong>en</strong>e er autokorrelerte.<br />
Andre tester kan utføres for om<br />
mulig å få avklart dette, m<strong>en</strong> det refereres<br />
ikke her.<br />
R<strong>en</strong>t intuitivt kan det likevel sies at det er<br />
stor sannsynlighet for positiv autokorrelasjon<br />
sid<strong>en</strong> vi b<strong>en</strong>ytter akkumulerte<br />
data: y vokser i alle perioder. I så fall<br />
bidrar positiv autokorrelasjon til overoptimistiske<br />
t-verdier (d<strong>en</strong> estimerte varians<strong>en</strong><br />
på parametr<strong>en</strong>e underestimeres),<br />
og likeså overoptimistisk verdi på d<strong>en</strong><br />
multiple korrelasjonskoeffisi<strong>en</strong>t<strong>en</strong>. Alt<br />
dette gir prognoser med høyere usikker-