Prognosemetoder – en oversikt - Telenor
Prognosemetoder – en oversikt - Telenor
Prognosemetoder – en oversikt - Telenor

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
Verdiindeks<br />
220<br />
210<br />
200<br />
190<br />
180<br />
170<br />
160<br />
150<br />
140<br />
130<br />
120<br />
110<br />
22<br />
1 2 3 4 5 6 7 8 9 10 11 12<br />
Måned<br />
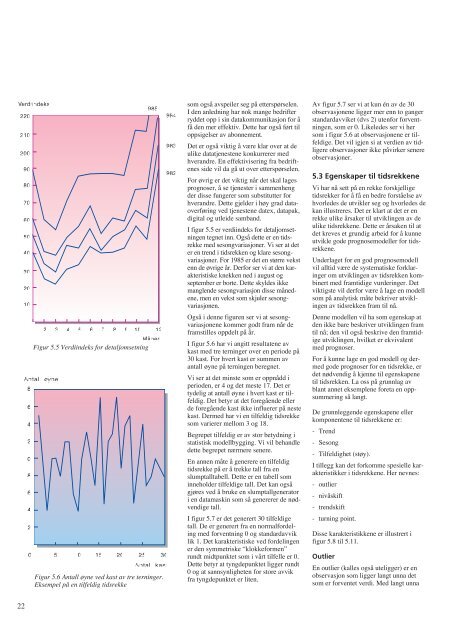
Figur 5.5 Verdiindeks for detaljomsetning<br />
Antall øyne<br />
18<br />
16<br />
14<br />
12<br />
10<br />
8<br />
6<br />
4<br />
2<br />
0<br />
1985<br />
5 10 15 20 25 30<br />
Antall kast<br />
Figur 5.6 Antall øyne ved kast av tre terninger.<br />
Eksempel på <strong>en</strong> tilfeldig tidsrekke<br />
1984<br />
1983<br />
1982<br />
som også avspeiler seg på etterspørsel<strong>en</strong>.<br />
I d<strong>en</strong> anledning har nok mange bedrifter<br />
ryddet opp i sin datakommunikasjon for å<br />
få d<strong>en</strong> mer effektiv. Dette har også ført til<br />
oppsigelser av abonnem<strong>en</strong>t.<br />
Det er også viktig å være klar over at de<br />
ulike datatj<strong>en</strong>est<strong>en</strong>e konkurrerer med<br />
hverandre. En effektivisering fra bedrift<strong>en</strong>es<br />
side vil da gå ut over etterspørsel<strong>en</strong>.<br />
For øvrig er det viktig når det skal lages<br />
prognoser, å se tj<strong>en</strong>ester i samm<strong>en</strong>h<strong>en</strong>g<br />
der disse fungerer som substitutter for<br />
hverandre. Dette gjelder i høy grad dataoverføring<br />
ved tj<strong>en</strong>est<strong>en</strong>e datex, datapak,<br />
digital og utleide samband.<br />
I figur 5.5 er verdiindeks for detaljomsetning<strong>en</strong><br />
tegnet inn. Også dette er <strong>en</strong> tidsrekke<br />
med sesongvariasjoner. Vi ser at det<br />
er <strong>en</strong> tr<strong>en</strong>d i tidsrekk<strong>en</strong> og klare sesongvariasjoner.<br />
For 1985 er det <strong>en</strong> større vekst<br />
<strong>en</strong>n de øvrige år. Derfor ser vi at d<strong>en</strong> karakteristiske<br />
knekk<strong>en</strong> ned i august og<br />
september er borte. Dette skyldes ikke<br />
mangl<strong>en</strong>de sesongvariasjon disse måned<strong>en</strong>e,<br />
m<strong>en</strong> <strong>en</strong> vekst som skjuler sesongvariasjon<strong>en</strong>.<br />
Også i d<strong>en</strong>ne figur<strong>en</strong> ser vi at sesongvariasjon<strong>en</strong>e<br />
kommer godt fram når de<br />
framstilles oppdelt på år.<br />
I figur 5.6 har vi angitt resultat<strong>en</strong>e av<br />
kast med tre terninger over <strong>en</strong> periode på<br />
30 kast. For hvert kast er summ<strong>en</strong> av<br />
antall øyne på terning<strong>en</strong> beregnet.<br />
Vi ser at det minste som er oppnådd i<br />
period<strong>en</strong>, er 4 og det meste 17. Det er<br />
tydelig at antall øyne i hvert kast er tilfeldig.<br />
Det betyr at det foregå<strong>en</strong>de eller<br />
de foregå<strong>en</strong>de kast ikke influerer på neste<br />
kast. Dermed har vi <strong>en</strong> tilfeldig tidsrekke<br />
som varierer mellom 3 og 18.<br />
Begrepet tilfeldig er av stor betydning i<br />
statistisk modellbygging. Vi vil behandle<br />
dette begrepet nærmere s<strong>en</strong>ere.<br />
En ann<strong>en</strong> måte å g<strong>en</strong>erere <strong>en</strong> tilfeldig<br />
tidsrekke på er å trekke tall fra <strong>en</strong><br />
slumptalltabell. Dette er <strong>en</strong> tabell som<br />
inneholder tilfeldige tall. Det kan også<br />
gjøres ved å bruke <strong>en</strong> slumptallg<strong>en</strong>erator<br />
i <strong>en</strong> datamaskin som så g<strong>en</strong>ererer de nødv<strong>en</strong>dige<br />
tall.<br />
I figur 5.7 er det g<strong>en</strong>erert 30 tilfeldige<br />
tall. De er g<strong>en</strong>erert fra <strong>en</strong> normalfordeling<br />
med forv<strong>en</strong>tning 0 og standardavvik<br />
lik 1. Det karakteristiske ved fordeling<strong>en</strong><br />
er d<strong>en</strong> symmetriske “klokkeform<strong>en</strong>”<br />
rundt midtpunktet som i vårt tilfelle er 0.<br />
Dette betyr at tyngdepunktet ligger rundt<br />
0 og at sannsynlighet<strong>en</strong> for store avvik<br />
fra tyngdepunktet er lit<strong>en</strong>.<br />
Av figur 5.7 ser vi at kun én av de 30<br />
observasjon<strong>en</strong>e ligger mer <strong>en</strong>n to ganger<br />
standardavviket (dvs 2) ut<strong>en</strong>for forv<strong>en</strong>tning<strong>en</strong>,<br />
som er 0. Likeledes ser vi her<br />
som i figur 5.6 at observasjon<strong>en</strong>e er tilfeldige.<br />
Det vil igj<strong>en</strong> si at verdi<strong>en</strong> av tidligere<br />
observasjoner ikke påvirker s<strong>en</strong>ere<br />
observasjoner.<br />
5.3 Eg<strong>en</strong>skaper til tidsrekk<strong>en</strong>e<br />
Vi har nå sett på <strong>en</strong> rekke forskjellige<br />
tidsrekker for å få <strong>en</strong> bedre forståelse av<br />
hvorledes de utvikler seg og hvorledes de<br />
kan illustreres. Det er klart at det er <strong>en</strong><br />
rekke ulike årsaker til utvikling<strong>en</strong> av de<br />
ulike tidsrekk<strong>en</strong>e. Dette er årsak<strong>en</strong> til at<br />
det kreves et grundig arbeid for å kunne<br />
utvikle gode prognosemodeller for tidsrekk<strong>en</strong>e.<br />
Underlaget for <strong>en</strong> god prognosemodell<br />
vil alltid være de systematiske forklaringer<br />
om utvikling<strong>en</strong> av tidsrekk<strong>en</strong> kombinert<br />
med framtidige vurderinger. Det<br />
viktigste vil derfor være å lage <strong>en</strong> modell<br />
som på analytisk måte bekriver utvikling<strong>en</strong><br />
av tidsrekk<strong>en</strong> fram til nå.<br />
D<strong>en</strong>ne modell<strong>en</strong> vil ha som eg<strong>en</strong>skap at<br />
d<strong>en</strong> ikke bare beskriver utvikling<strong>en</strong> fram<br />
til nå; d<strong>en</strong> vil også beskrive d<strong>en</strong> framtidige<br />
utvikling<strong>en</strong>, hvilket er ekvival<strong>en</strong>t<br />
med prognoser.<br />
For å kunne lage <strong>en</strong> god modell og dermed<br />
gode prognoser for <strong>en</strong> tidsrekke, er<br />
det nødv<strong>en</strong>dig å kj<strong>en</strong>ne til eg<strong>en</strong>skap<strong>en</strong>e<br />
til tidsrekk<strong>en</strong>. La oss på grunnlag av<br />
blant annet eksempl<strong>en</strong>e foreta <strong>en</strong> oppsummering<br />
så langt.<br />
De grunnlegg<strong>en</strong>de eg<strong>en</strong>skap<strong>en</strong>e eller<br />
kompon<strong>en</strong>t<strong>en</strong>e til tidsrekk<strong>en</strong>e er:<br />
- Tr<strong>en</strong>d<br />
- Sesong<br />
- Tilfeldighet (støy).<br />
I tillegg kan det forkomme spesielle karakteristikker<br />
i tidsrekk<strong>en</strong>e. Her nevnes:<br />
- outlier<br />
- nivåskift<br />
- tr<strong>en</strong>dskift<br />
- turning point.<br />
Disse karakteristikk<strong>en</strong>e er illustrert i<br />
figur 5.8 til 5.11.<br />
Outlier<br />
En outlier (kalles også uteligger) er <strong>en</strong><br />
observasjon som ligger langt unna det<br />
som er forv<strong>en</strong>tet verdi. Med langt unna