Calage et validation des modèles de trafic - Sétra
Calage et validation des modèles de trafic - Sétra
Calage et validation des modèles de trafic - Sétra

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
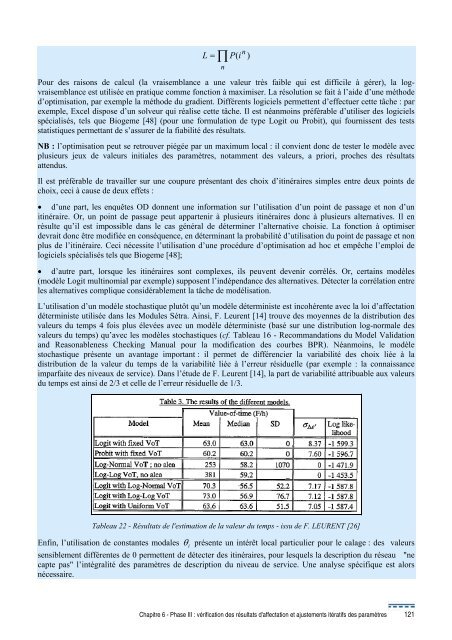
nL = ∏ P(i )nPour <strong><strong>de</strong>s</strong> raisons <strong>de</strong> calcul (la vraisemblance a une valeur très faible qui est difficile à gérer), la logvraisemblanceest utilisée en pratique comme fonction à maximiser. La résolution se fait à l’ai<strong>de</strong> d’une métho<strong>de</strong>d’optimisation, par exemple la métho<strong>de</strong> du gradient. Différents logiciels perm<strong>et</strong>tent d’effectuer c<strong>et</strong>te tâche : parexemple, Excel dispose d’un solveur qui réalise c<strong>et</strong>te tâche. Il est néanmoins préférable d’utiliser <strong><strong>de</strong>s</strong> logicielsspécialisés, tels que Biogeme [48] (pour une formulation <strong>de</strong> type Logit ou Probit), qui fournissent <strong><strong>de</strong>s</strong> testsstatistiques perm<strong>et</strong>tant <strong>de</strong> s’assurer <strong>de</strong> la fiabilité <strong><strong>de</strong>s</strong> résultats.NB : l’optimisation peut se r<strong>et</strong>rouver piégée par un maximum local : il convient donc <strong>de</strong> tester le modèle avecplusieurs jeux <strong>de</strong> valeurs initiales <strong><strong>de</strong>s</strong> paramètres, notamment <strong><strong>de</strong>s</strong> valeurs, a priori, proches <strong><strong>de</strong>s</strong> résultatsattendus.Il est préférable <strong>de</strong> travailler sur une coupure présentant <strong><strong>de</strong>s</strong> choix d’itinéraires simples entre <strong>de</strong>ux points <strong>de</strong>choix, ceci à cause <strong>de</strong> <strong>de</strong>ux eff<strong>et</strong>s :• d’une part, les enquêtes OD donnent une information sur l’utilisation d’un point <strong>de</strong> passage <strong>et</strong> non d’unitinéraire. Or, un point <strong>de</strong> passage peut appartenir à plusieurs itinéraires donc à plusieurs alternatives. Il enrésulte qu’il est impossible dans le cas général <strong>de</strong> déterminer l’alternative choisie. La fonction à optimiser<strong>de</strong>vrait donc être modifiée en conséquence, en déterminant la probabilité d’utilisation du point <strong>de</strong> passage <strong>et</strong> nonplus <strong>de</strong> l’itinéraire. Ceci nécessite l’utilisation d’une procédure d’optimisation ad hoc <strong>et</strong> empêche l’emploi <strong>de</strong>logiciels spécialisés tels que Biogeme [48];• d’autre part, lorsque les itinéraires sont complexes, ils peuvent <strong>de</strong>venir corrélés. Or, certains modèles(modèle Logit multinomial par exemple) supposent l’indépendance <strong><strong>de</strong>s</strong> alternatives. Détecter la corrélation entreles alternatives complique considérablement la tâche <strong>de</strong> modélisation.L’utilisation d’un modèle stochastique plutôt qu’un modèle déterministe est incohérente avec la loi d’affectationdéterministe utilisée dans les Modules Sétra. Ainsi, F. Leurent [14] trouve <strong><strong>de</strong>s</strong> moyennes <strong>de</strong> la distribution <strong><strong>de</strong>s</strong>valeurs du temps 4 fois plus élevées avec un modèle déterministe (basé sur une distribution log-normale <strong><strong>de</strong>s</strong>valeurs du temps) qu’avec les modèles stochastiques (cf. Tableau 16 - Recommandations du Mo<strong>de</strong>l Validationand Reasonableness Checking Manual pour la modification <strong><strong>de</strong>s</strong> courbes BPR). Néanmoins, le modèlestochastique présente un avantage important : il perm<strong>et</strong> <strong>de</strong> différencier la variabilité <strong><strong>de</strong>s</strong> choix liée à ladistribution <strong>de</strong> la valeur du temps <strong>de</strong> la variabilité liée à l’erreur résiduelle (par exemple : la connaissanceimparfaite <strong><strong>de</strong>s</strong> niveaux <strong>de</strong> service). Dans l’étu<strong>de</strong> <strong>de</strong> F. Leurent [14], la part <strong>de</strong> variabilité attribuable aux valeursdu temps est ainsi <strong>de</strong> 2/3 <strong>et</strong> celle <strong>de</strong> l’erreur résiduelle <strong>de</strong> 1/3.Tableau 22 - Résultats <strong>de</strong> l'estimation <strong>de</strong> la valeur du temps - issu <strong>de</strong> F. LEURENT [26]Enfin, l’utilisation <strong>de</strong> constantes modalesiθ présente un intérêt local particulier pour le calage : <strong><strong>de</strong>s</strong> valeurssensiblement différentes <strong>de</strong> 0 perm<strong>et</strong>tent <strong>de</strong> détecter <strong><strong>de</strong>s</strong> itinéraires, pour lesquels la <strong><strong>de</strong>s</strong>cription du réseau "necapte pas" l’intégralité <strong><strong>de</strong>s</strong> paramètres <strong>de</strong> <strong><strong>de</strong>s</strong>cription du niveau <strong>de</strong> service. Une analyse spécifique est alorsnécessaire.Chapitre 6 - Phase III : vérification <strong><strong>de</strong>s</strong> résultats d'affectation <strong>et</strong> ajustements itératifs <strong><strong>de</strong>s</strong> paramètres 121