

Mélanges de GLMs et nombre de composantes : application ... - Scor
Mélanges de GLMs et nombre de composantes : application ... - Scor
Mélanges de GLMs et nombre de composantes : application ... - Scor

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
B.1.3<br />
Plus loin dans la théorie <strong>de</strong>s CART<br />
Spécification <strong>de</strong>s règles binaires<br />
B.1. Métho<strong>de</strong> CART<br />
Criterion 1. Ces règles dépen<strong>de</strong>nt seulement d’un seuil µ <strong>et</strong> d’ une variable x l , 1 ≤ l ≤ d :<br />
– x l ≤ µ, µ ∈ R dans le cas d’une variable continue ordonnée (si nous avons m valeurs<br />
distinctes pour x l , l’ensemble <strong>de</strong>s valeurs possibles card(D) vaut M - 1) ;<br />
– x l ∈ µ où µ est un sous-ensemble <strong>de</strong> {µ 1 , µ 2 , ..., µ M } <strong>et</strong> les µ m sont les modalités <strong>de</strong> la<br />
variable catégorielle (dans ce cas le cardinal du sous-ensemble D <strong>de</strong>s règles binaires vaut<br />
2 M−1 − 1).<br />
Qu’est ce qu’une fonction d’impur<strong>et</strong>é ?<br />
Définition. Une fonction d’impur<strong>et</strong>é est une fonction réelle g définie sur un ensemble <strong>de</strong><br />
probabilités discrètes d’un ensemble fini :<br />
symétrique en p 1 , p 2 , ..., p J <strong>et</strong> qui vérifie :<br />
g : (p 1 , p 2 , ..., p J ) → g(p 1 , p 2 , ..., p J ),<br />
1. le maximum <strong>de</strong> g est à l’équiprobabilité : argmax g(p 1 , p 2 , ..., p J ) = ( 1<br />
J , 1 J , ..., 1 J<br />
)<br />
,<br />
2. le minimum <strong>de</strong> g est obtenu par les “dirac" : argmin g(p 1 , p 2 , ..., p J ) ∈ {e 1 , ..., e J }, où<br />
e j est le j eme élément dans la base canonique <strong>de</strong>R J .<br />
Différentes fonctions d’impur<strong>et</strong>é<br />
D’habitu<strong>de</strong> nous considérons les fonctions suivantes (qui satisfont le critère <strong>de</strong> concavité) :<br />
• impur(t) = - ∑ J<br />
j=1 p(j|t) ln(p(j|t)) ; cp<br />
size of tree<br />
1 2 3 6 16 22 35 54 69 83 98 118 140 175<br />
X-val Relative Error<br />
0.2 0.4 0.6 0.8 1.0<br />
Inf 0.043 0.00049 0.00032 0.00019 1e-04 5.3e-05 0<br />
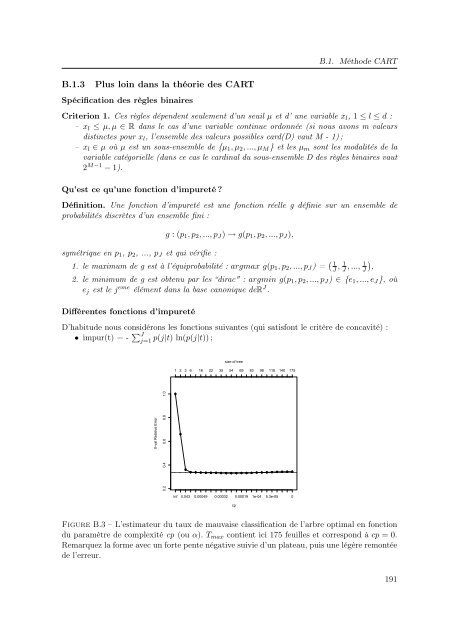
Figure B.3 – L’estimateur du taux <strong>de</strong> mauvaise classification <strong>de</strong> l’arbre optimal en fonction<br />
du paramètre <strong>de</strong> complexité cp (ou α). T max contient ici 175 feuilles <strong>et</strong> correspond à cp = 0.<br />
Remarquez la forme avec un forte pente négative suivie d’un plateau, puis une légère remontée<br />
<strong>de</strong> l’erreur.<br />
191













