

Mélanges de GLMs et nombre de composantes : application ... - Scor
Mélanges de GLMs et nombre de composantes : application ... - Scor
Mélanges de GLMs et nombre de composantes : application ... - Scor

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
Chapitre 3. Mélange <strong>de</strong> régressions logistiques<br />
3.2.3 Modélisation <strong>et</strong> prévisions par mélange <strong>de</strong> GLM<br />
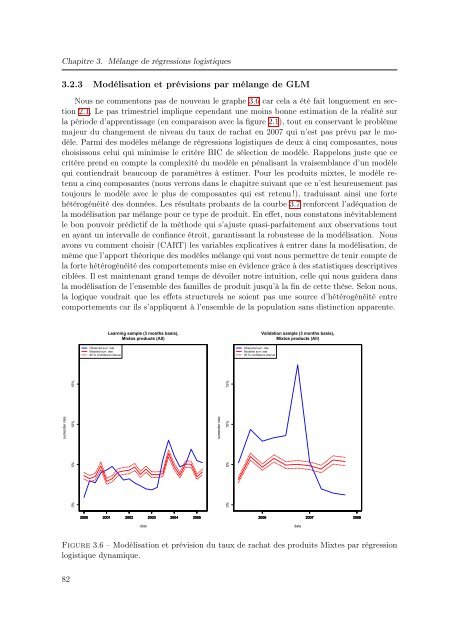
Nous ne commentons pas <strong>de</strong> nouveau le graphe 3.6 car cela a été fait longuement en section<br />
2.1. Le pas trimestriel implique cependant une moins bonne estimation <strong>de</strong> la réalité sur<br />
la pério<strong>de</strong> d’apprentissage (en comparaison avec la figure 2.1), tout en conservant le problème<br />
majeur du changement <strong>de</strong> niveau du taux <strong>de</strong> rachat en 2007 qui n’est pas prévu par le modèle.<br />
Parmi <strong>de</strong>s modèles mélange <strong>de</strong> régressions logistiques <strong>de</strong> <strong>de</strong>ux à cinq <strong>composantes</strong>, nous<br />
choisissons celui qui minimise le critère BIC <strong>de</strong> sélection <strong>de</strong> modèle. Rappelons juste que ce<br />
critère prend en compte la complexité du modèle en pénalisant la vraisemblance d’un modèle<br />
qui contiendrait beaucoup <strong>de</strong> paramètres à estimer. Pour les produits mixtes, le modèle r<strong>et</strong>enu<br />
a cinq <strong>composantes</strong> (nous verrons dans le chapitre suivant que ce n’est heureusement pas<br />
toujours le modèle avec le plus <strong>de</strong> <strong>composantes</strong> qui est r<strong>et</strong>enu !), traduisant ainsi une forte<br />
hétérogénéité <strong>de</strong>s données. Les résultats probants <strong>de</strong> la courbe 3.7 renforcent l’adéquation <strong>de</strong><br />
la modélisation par mélange pour ce type <strong>de</strong> produit. En eff<strong>et</strong>, nous constatons inévitablement<br />
le bon pouvoir prédictif <strong>de</strong> la métho<strong>de</strong> qui s’ajuste quasi-parfaitement aux observations tout<br />
en ayant un intervalle <strong>de</strong> confiance étroit, garantissant la robustesse <strong>de</strong> la modélisation. Nous<br />
avons vu comment choisir (CART) les variables explicatives à entrer dans la modélisation, <strong>de</strong><br />
même que l’apport théorique <strong>de</strong>s modèles mélange qui vont nous perm<strong>et</strong>tre <strong>de</strong> tenir compte <strong>de</strong><br />
la forte hétérogénéité <strong>de</strong>s comportements mise en évi<strong>de</strong>nce grâce à <strong>de</strong>s statistiques <strong>de</strong>scriptives<br />
ciblées. Il est maintenant grand temps <strong>de</strong> dévoiler notre intuition, celle qui nous gui<strong>de</strong>ra dans<br />
la modélisation <strong>de</strong> l’ensemble <strong>de</strong>s familles <strong>de</strong> produit jusqu’à la fin <strong>de</strong> c<strong>et</strong>te thèse. Selon nous,<br />
la logique voudrait que les eff<strong>et</strong>s structurels ne soient pas une source d’hétérogénéité entre<br />
comportements car ils s’appliquent à l’ensemble <strong>de</strong> la population sans distinction apparente.<br />
Learning sample (3 months basis),<br />
Mixtos products (All)<br />
Validation sample (3 months basis),<br />
Mixtos products (All)<br />
Observed surr. rate<br />
Mo<strong>de</strong>led surr. rate<br />
95 % confi<strong>de</strong>nce interval<br />
Observed surr. rate<br />
Mo<strong>de</strong>led surr. rate<br />
95 % confi<strong>de</strong>nce interval<br />
surren<strong>de</strong>r rate<br />
0% 5% 10% 15%<br />
surren<strong>de</strong>r rate<br />
0% 5% 10% 15%<br />
2000 2001 2002 2003 2004 2005<br />
date<br />
2006 2007 2008<br />
date<br />
Figure 3.6 – Modélisation <strong>et</strong> prévision du taux <strong>de</strong> rachat <strong>de</strong>s produits Mixtes par régression<br />
logistique dynamique.<br />
82













