

Mélanges de GLMs et nombre de composantes : application ... - Scor
Mélanges de GLMs et nombre de composantes : application ... - Scor
Mélanges de GLMs et nombre de composantes : application ... - Scor

Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
1.3. Illustration : <strong>application</strong> sur <strong>de</strong>s contrats mixtes<br />
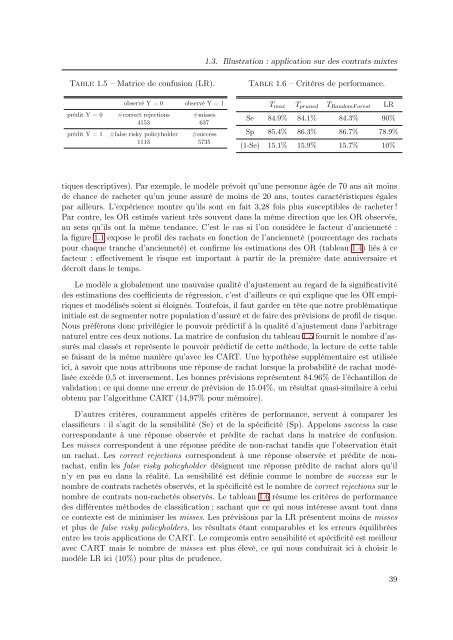
Table 1.5 – Matrice <strong>de</strong> confusion (LR).<br />
observé Y = 0 observé Y = 1<br />
prédit Y = 0 #correct rejections #misses<br />
4153 637<br />
prédit Y = 1 #false risky policyhol<strong>de</strong>r #success<br />
1113 5735<br />
Table 1.6 – Critères <strong>de</strong> performance.<br />
T max T pruned T RandomF orest LR<br />
Se 84.9% 84.1% 84.3% 90%<br />
Sp 85.4% 86.3% 86.7% 78.9%<br />
(1-Se) 15.1% 15.9% 15.7% 10%<br />
tiques <strong>de</strong>scriptives). Par exemple, le modèle prévoit qu’une personne âgée <strong>de</strong> 70 ans ait moins<br />
<strong>de</strong> chance <strong>de</strong> rach<strong>et</strong>er qu’un jeune assuré <strong>de</strong> moins <strong>de</strong> 20 ans, toutes caractéristiques égales<br />
par ailleurs. L’expérience montre qu’ils sont en fait 3,28 fois plus susceptibles <strong>de</strong> rach<strong>et</strong>er !<br />
Par contre, les OR estimés varient très souvent dans la même direction que les OR observés,<br />
au sens qu’ils ont la même tendance. C’est le cas si l’on considère le facteur d’ancienn<strong>et</strong>é :<br />
la figure 1.1 expose le profil <strong>de</strong>s rachats en fonction <strong>de</strong> l’ancienn<strong>et</strong>é (pourcentage <strong>de</strong>s rachats<br />
pour chaque tranche d’ancienn<strong>et</strong>é) <strong>et</strong> confirme les estimations <strong>de</strong>s OR (tableau 1.4) liés à ce<br />
facteur : effectivement le risque est important à partir <strong>de</strong> la première date anniversaire <strong>et</strong><br />
décroît dans le temps.<br />
Le modèle a globalement une mauvaise qualité d’ajustement au regard <strong>de</strong> la significativité<br />
<strong>de</strong>s estimations <strong>de</strong>s coefficients <strong>de</strong> régression, c’est d’ailleurs ce qui explique que les OR empiriques<br />
<strong>et</strong> modélisés soient si éloignés. Toutefois, il faut gar<strong>de</strong>r en tête que notre problématique<br />
initiale est <strong>de</strong> segmenter notre population d’assuré <strong>et</strong> <strong>de</strong> faire <strong>de</strong>s prévisions <strong>de</strong> profil <strong>de</strong> risque.<br />
Nous préférons donc privilégier le pouvoir prédictif à la qualité d’ajustement dans l’arbitrage<br />
naturel entre ces <strong>de</strong>ux notions. La matrice <strong>de</strong> confusion du tableau 1.5 fournit le <strong>nombre</strong> d’assurés<br />
mal classés <strong>et</strong> représente le pouvoir prédictif <strong>de</strong> c<strong>et</strong>te métho<strong>de</strong>, la lecture <strong>de</strong> c<strong>et</strong>te table<br />
se faisant <strong>de</strong> la même manière qu’avec les CART. Une hypothèse supplémentaire est utilisée<br />
ici, à savoir que nous attribuons une réponse <strong>de</strong> rachat lorsque la probabilité <strong>de</strong> rachat modélisée<br />
excè<strong>de</strong> 0,5 <strong>et</strong> inversement. Les bonnes prévisions représentent 84.96% <strong>de</strong> l’échantillon <strong>de</strong><br />
validation ; ce qui donne une erreur <strong>de</strong> prévision <strong>de</strong> 15.04%, un résultat quasi-similaire à celui<br />
obtenu par l’algorithme CART (14,97% pour mémoire).<br />
D’autres critères, couramment appelés critères <strong>de</strong> performance, servent à comparer les<br />
classifieurs : il s’agit <strong>de</strong> la sensibilité (Se) <strong>et</strong> <strong>de</strong> la spécificité (Sp). Appelons success la case<br />
correspondante à une réponse observée <strong>et</strong> prédite <strong>de</strong> rachat dans la matrice <strong>de</strong> confusion.<br />
Les misses correspon<strong>de</strong>nt à une réponse prédite <strong>de</strong> non-rachat tandis que l’observation était<br />
un rachat. Les correct rejections correspon<strong>de</strong>nt à une réponse observée <strong>et</strong> prédite <strong>de</strong> nonrachat,<br />
enfin les false risky policyhol<strong>de</strong>r désignent une réponse prédite <strong>de</strong> rachat alors qu’il<br />
n’y en pas eu dans la réalité. La sensibilité est définie comme le <strong>nombre</strong> <strong>de</strong> success sur le<br />
<strong>nombre</strong> <strong>de</strong> contrats rach<strong>et</strong>és observés, <strong>et</strong> la spécificité est le <strong>nombre</strong> <strong>de</strong> correct rejections sur le<br />
<strong>nombre</strong> <strong>de</strong> contrats non-rach<strong>et</strong>és observés. Le tableau 1.6 résume les critères <strong>de</strong> performance<br />
<strong>de</strong>s différentes métho<strong>de</strong>s <strong>de</strong> classification ; sachant que ce qui nous intéresse avant tout dans<br />
ce contexte est <strong>de</strong> minimiser les misses. Les prévisions par la LR présentent moins <strong>de</strong> misses<br />
<strong>et</strong> plus <strong>de</strong> false risky policyhol<strong>de</strong>rs, les résultats étant comparables <strong>et</strong> les erreurs équilibrées<br />
entre les trois <strong>application</strong>s <strong>de</strong> CART. Le compromis entre sensibilité <strong>et</strong> spécificité est meilleur<br />
avec CART mais le <strong>nombre</strong> <strong>de</strong> misses est plus élevé, ce qui nous conduirait ici à choisir le<br />
modèle LR ici (10%) pour plus <strong>de</strong> pru<strong>de</strong>nce.<br />
39













