

statistique, théorie et gestion de portefeuille - Docs at ISFA
statistique, théorie et gestion de portefeuille - Docs at ISFA
statistique, théorie et gestion de portefeuille - Docs at ISFA

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
12.2. Minimiser l’impact <strong>de</strong>s grands co-mouvements 385<br />
Cutting edge l<br />
Portfolio tail risk<br />
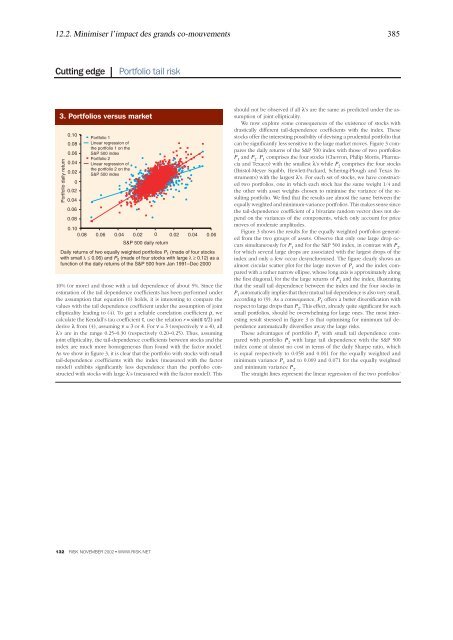
3. Portfolios versus mark<strong>et</strong><br />
Portfolio daily r<strong>et</strong>urn<br />
0.10<br />
0.08<br />
0.06<br />
0.04<br />
0.02<br />
0<br />
0.02<br />
0.04<br />
0.06<br />
0.08<br />
Portfolio 1<br />
Linear regression of<br />
the portfolio 1 on the<br />
S&P 500 in<strong>de</strong>x<br />
Portfolio 2<br />
Linear regression of<br />
the portfolio 2 on the<br />
S&P 500 in<strong>de</strong>x<br />
0.10<br />
0.08 0.06 0.04 0.02 0 0.02 0.04 0.06<br />
S&P 500 daily r<strong>et</strong>urn<br />
Daily r<strong>et</strong>urns of two equally weighted portfolios P 1 (ma<strong>de</strong> of four stocks<br />
with small λ ≤ 0.06) and P 2 (ma<strong>de</strong> of four stocks with large λ ≥ 0.12) as a<br />
function of the daily r<strong>et</strong>urns of the S&P 500 from Jan 1991–Dec 2000<br />
10% (or more) and those with a tail <strong>de</strong>pen<strong>de</strong>nce of about 5%. Since the<br />
estim<strong>at</strong>ion of the tail <strong>de</strong>pen<strong>de</strong>nce coefficients has been performed un<strong>de</strong>r<br />
the assumption th<strong>at</strong> equ<strong>at</strong>ion (6) holds, it is interesting to compare the<br />
values with the tail <strong>de</strong>pen<strong>de</strong>nce coefficient un<strong>de</strong>r the assumption of joint<br />
ellipticality leading to (4). To g<strong>et</strong> a reliable correl<strong>at</strong>ion coefficient ρ, we<br />
calcul<strong>at</strong>e the Kendall’s tau coefficient τ, use the rel<strong>at</strong>ion r = sin(πτ/2) and<br />
<strong>de</strong>rive λ from (4), assuming ν = 3 or 4. For ν = 3 (respectively ν = 4), all<br />
λ’s are in the range 0.25–0.30 (respectively 0.20–0.25). Thus, assuming<br />
joint ellipticality, the tail-<strong>de</strong>pen<strong>de</strong>nce coefficients b<strong>et</strong>ween stocks and the<br />
in<strong>de</strong>x are much more homogeneous than found with the factor mo<strong>de</strong>l.<br />
As we show in figure 3, it is clear th<strong>at</strong> the portfolio with stocks with small<br />
tail-<strong>de</strong>pen<strong>de</strong>nce coefficients with the in<strong>de</strong>x (measured with the factor<br />
mo<strong>de</strong>l) exhibits significantly less <strong>de</strong>pen<strong>de</strong>nce than the portfolio constructed<br />
with stocks with large λ’s (measured with the factor mo<strong>de</strong>l). This<br />
132 RISK NOVEMBER 2002 ● WWW.RISK.NET<br />
should not be observed if all λ’s are the same as predicted un<strong>de</strong>r the assumption<br />
of joint ellipticality.<br />
We now explore some consequences of the existence of stocks with<br />
drastically different tail-<strong>de</strong>pen<strong>de</strong>nce coefficients with the in<strong>de</strong>x. These<br />
stocks offer the interesting possibility of <strong>de</strong>vising a pru<strong>de</strong>ntial portfolio th<strong>at</strong><br />
can be significantly less sensitive to the large mark<strong>et</strong> moves. Figure 3 compares<br />
the daily r<strong>et</strong>urns of the S&P 500 in<strong>de</strong>x with those of two portfolios<br />
P 1 and P 2 . P 1 comprises the four stocks (Chevron, Philip Morris, Pharmacia<br />
and Texaco) with the smallest λ’s while P 2 comprises the four stocks<br />
(Bristol-Meyer Squibb, Hewl<strong>et</strong>t-Packard, Schering-Plough and Texas Instruments)<br />
with the largest λ’s. For each s<strong>et</strong> of stocks, we have constructed<br />
two portfolios, one in which each stock has the same weight 1/4 and<br />
the other with ass<strong>et</strong> weights chosen to minimise the variance of the resulting<br />
portfolio. We find th<strong>at</strong> the results are almost the same b<strong>et</strong>ween the<br />
equally weighted and minimum-variance portfolios. This makes sense since<br />
the tail-<strong>de</strong>pen<strong>de</strong>nce coefficient of a bivari<strong>at</strong>e random vector does not <strong>de</strong>pend<br />
on the variances of the components, which only account for price<br />
moves of mo<strong>de</strong>r<strong>at</strong>e amplitu<strong>de</strong>s.<br />
Figure 3 shows the results for the equally weighted portfolios gener<strong>at</strong>ed<br />
from the two groups of ass<strong>et</strong>s. Observe th<strong>at</strong> only one large drop occurs<br />
simultaneously for P 1 and for the S&P 500 in<strong>de</strong>x, in contrast with P 2 ,<br />
for which several large drops are associ<strong>at</strong>ed with the largest drops of the<br />
in<strong>de</strong>x and only a few occur <strong>de</strong>synchronised. The figure clearly shows an<br />
almost circular sc<strong>at</strong>ter plot for the large moves of P 1 and the in<strong>de</strong>x compared<br />
with a r<strong>at</strong>her narrow ellipse, whose long axis is approxim<strong>at</strong>ely along<br />
the first diagonal, for the the large r<strong>et</strong>urns of P 2 and the in<strong>de</strong>x, illustr<strong>at</strong>ing<br />
th<strong>at</strong> the small tail <strong>de</strong>pen<strong>de</strong>nce b<strong>et</strong>ween the in<strong>de</strong>x and the four stocks in<br />
P 1 autom<strong>at</strong>ically implies th<strong>at</strong> their mutual tail <strong>de</strong>pen<strong>de</strong>nce is also very small,<br />
according to (9). As a consequence, P 1 offers a b<strong>et</strong>ter diversific<strong>at</strong>ion with<br />
respect to large drops than P 2 . This effect, already quite significant for such<br />
small portfolios, should be overwhelming for large ones. The most interesting<br />
result stressed in figure 3 is th<strong>at</strong> optimising for minimum tail <strong>de</strong>pen<strong>de</strong>nce<br />
autom<strong>at</strong>ically diversifies away the large risks.<br />
These advantages of portfolio P 1 with small tail <strong>de</strong>pen<strong>de</strong>nce compared<br />
with portfolio P 2 with large tail <strong>de</strong>pen<strong>de</strong>nce with the S&P 500<br />
in<strong>de</strong>x come <strong>at</strong> almost no cost in terms of the daily Sharpe r<strong>at</strong>io, which<br />
is equal respectively to 0.058 and 0.061 for the equally weighted and<br />
minimum variance P 1 and to 0.069 and 0.071 for the equally weighted<br />
and minimum variance P 2 .<br />
The straight lines represent the linear regression of the two portfolios’

