

Numerical Methods Contents - SAM
Numerical Methods Contents - SAM
Numerical Methods Contents - SAM

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
0 50 100 150 200 250 300 350 400 450 500<br />
page rank<br />
0.1<br />
0.09<br />
0.08<br />
0.07<br />
0.06<br />
0.05<br />
0.04<br />
0.03<br />
0.02<br />
0.01<br />
step 5<br />
page rank<br />
0.1<br />
0.09<br />
0.08<br />
0.07<br />
0.06<br />
0.05<br />
0.04<br />
0.03<br />
0.02<br />
0.01<br />
step 15<br />
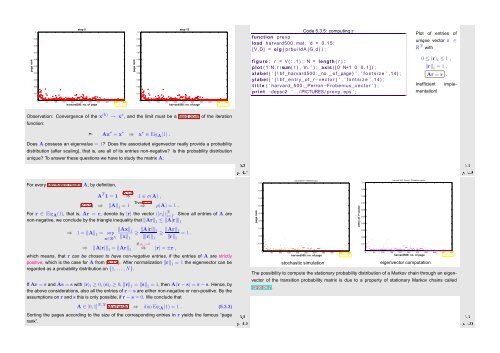
1 function prevp<br />
Code 5.3.5: computing r<br />
2 load harvard500 . mat ; d = 0 . 1 5 ;<br />
3 [ V,D] = eig ( p r b u i l d A (G, d ) ) ;<br />
4<br />
5 figure ; r = V ( : , 1 ) ; N = length ( r ) ;<br />
6 plot ( 1 :N, r /sum( r ) , ’m. ’ ) ; axis ( [ 0 N+1 0 0 . 1 ] ) ;<br />
7 xlabel ( ’ { \ b f harvard500 : no . o f page } ’ , ’ f o n t s i z e ’ ,14) ;<br />
8 ylabel ( ’ { \ b f e n t r y o f r−vector } ’ , ’ f o n t s i z e ’ ,14) ;<br />
9 t i t l e ( ’ harvard 500: Perron−Frobenius vector ’ ) ;<br />
10 p r i n t −depsc2 ’ . . / PICTURES/ prevp . eps ’ ;<br />
Plot of entries of<br />
unique vector r ∈<br />
R N with<br />
0 ≤ (r) i ≤ 1 ,<br />
‖r‖ 1 = 1 ,<br />
Inefficient<br />
Ar = r .<br />
implementation!<br />
0<br />
harvard500: no. of page<br />
Fig. 62<br />
0<br />
200 250 300 350<br />
harvard500: no. of page<br />
450 500<br />
Fig. 63<br />
0 50 100 150 400<br />
Observation: Convergence of the x (k) → x ∗ , and the limit must be a fixed point of the iteration<br />
function:<br />
➣ Ax ∗ = x ∗ ⇒ x ∗ ∈ Eig A (1) .<br />
Does A possess an eigenvalue = 1? Does the associated eigenvector really provide a probability<br />
distribution (after scaling), that is, are all of its entries non-negative? Is this probability distribution<br />
unique? To answer these questions we have to study the matrix A:<br />
Ôº½ º¿<br />
Ôº½ º¿<br />
For every stochastic matrix A, by definition,<br />
A T 1 = 1 (5.1.2)<br />
⇒ 1 ∈ σ(A) ,<br />
(2.5.5) ⇒ ‖A‖ 1 = 1<br />
Thm 5.1.2<br />
⇒ ρ(A) = 1 .<br />
For r ∈ Eig A (1), that is, Ar = r, denote by |r| the vector (|r i |) N i=1 . Since all entries of A are<br />
non-negative, we conclude by the triangle inequality that ‖Ar‖ 1 ≤ ‖A|r|‖ 1<br />
⇒<br />
1 = ‖A‖ 1 = sup<br />
x∈R N ‖Ax‖ 1<br />
‖x‖ 1<br />
≥ ‖A|r|‖ 1<br />
‖|r|‖ 1<br />
≥ ‖Ar‖ 1<br />
‖r‖ 1<br />
= 1 .<br />
⇒ ‖A|r|‖ 1 = ‖Ar‖ 1<br />
if a ij >0<br />
⇒ |r| = ±r ,<br />
which means, that r can be chosen to have non-negative entries, if the entries of A are strictly<br />
positive, which is the case for A from (5.3.2). After normalization ‖r‖ 1 = 1 the eigenvector can be<br />
regarded as a probability distribution on {1,...,N}.<br />
If Ar = r and As = s with (r) i ≥ 0, (s) i ≥ 0, ‖r‖ 1 = ‖s‖ 1 = 1, then A(r − s) = r − s. Hence, by<br />
the above considerations, also all the entries of r − s are either non-negative or non-positive. By the<br />
assumptions on r and s this is only possible, if r − s = 0. We conclude that<br />
A ∈ ]0, 1] N,N stochastic ⇒ dim Eig A (1) = 1 . (5.3.3)<br />
Sorting the pages according to the size of the corresponding entries in r yields the famous “page<br />
rank”.<br />
Ôº½ º¿<br />
page rank<br />
0.09<br />
0.08<br />
0.07<br />
0.06<br />
0.05<br />
0.04<br />
0.03<br />
0.02<br />
0.01<br />
harvard500: 1000000 hops<br />
0<br />
200 250 300 350<br />
harvard500: no. of page<br />
450 500<br />
Fig. 64<br />
0 50 100 150 400<br />
stochastic simulation<br />
entry of r−vector<br />
0.1<br />
0.09<br />
0.08<br />
0.07<br />
0.06<br />
0.05<br />
0.04<br />
0.03<br />
0.02<br />
0.01<br />
harvard 500: Perron−Frobenius vector<br />
0<br />
200 250 300 350<br />
harvard500: no. of page<br />
450 500<br />
Fig. 65<br />
0 50 100 150 400<br />
eigenvector computation<br />
The possibility to compute the stationary probability distribution of a Markov chain through an eigenvector<br />
of the transition probability matrix is due to a property of stationary Markov chains called<br />
ergodicity.<br />
Ôº¾¼ º¿













