

Numerical Methods Contents - SAM
Numerical Methods Contents - SAM
Numerical Methods Contents - SAM

Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
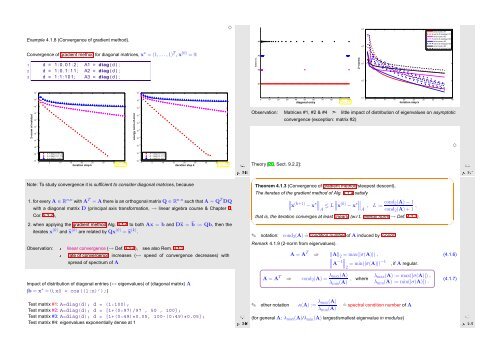
Example 4.1.8 (Convergence of gradient method).<br />
✸<br />
#4<br />
10 2<br />
error norm, #1<br />
norm of residual, #1<br />
error norm, #2<br />
norm of residual, #2<br />
error norm, #3<br />
norm of residual, #3<br />
error norm, #4<br />
norm of residual, #4<br />
Convergence of gradient method for diagonal matrices, x ∗ = (1,...,1) T , x (0) = 0:<br />
#3<br />
1 d = 1 : 0 . 0 1 : 2 ; A1 = diag ( d ) ;<br />
2 d = 1 : 0 . 1 : 1 1 ; A2 = diag ( d ) ;<br />
3 d = 1 : 1 : 1 0 1 ; A3 = diag ( d ) ;<br />
matrix no.<br />
#2<br />
2−norms<br />
10 1<br />
10 0<br />
#1<br />
10 2<br />
10 0<br />
0 10 20 30 40 50 60 70 80 90 100<br />
diagonal entry<br />
Fig. 48<br />
10 3 iteration step k<br />
10 −1<br />
0 5 10 15 20 25 30 35 40 45<br />
2−norm of residual<br />
step<br />
10 0<br />
10 −2<br />
10 −4<br />
10 −6<br />
10 −8<br />
10 −10<br />
10 −12<br />
10 −14 A = diag(1:0.01:2)<br />
A = diag(1:0.1:11)<br />
A = diag(1:1:101)<br />
10 −16<br />
0 5 10 15 20<br />
iteration<br />
25<br />
k<br />
30 35 40<br />
Fig. 46<br />
10 4<br />
energy norm of error<br />
step<br />
10 −2<br />
10 −4<br />
10 −6<br />
10 −8<br />
10 −10<br />
10 −12<br />
10 −14 A = diag(1:0.01:2)<br />
A = diag(1:0.1:11)<br />
A = diag(1:1:101)<br />
10 −16<br />
0 5 10 15 20<br />
iteration<br />
25<br />
k<br />
30 35 40<br />
Fig. 47<br />
10 2<br />
Ôº¿ º½<br />
Observation: Matrices #1, #2 & #4 ➣ little impact of distribution of eigenvalues on asymptotic<br />
convergence (exception: matrix #2)<br />
✸<br />
Theory [20, Sect. 9.2.2]:<br />
Ôº¿ º½<br />
Note: To study convergence it is sufficient to consider diagonal matrices, because<br />
1. for every A ∈ R n,n with A T = A there is an orthogonal matrix Q ∈ R n.n such that A = Q T DQ<br />
with a diagonal matrix D (principal axis transformation, → linear algebra course & Chapter 5,<br />
Cor. 5.1.7),<br />
2. when applying the gradient method Alg. 4.1.4 to both Ax = b and D˜x = ˜b := Qb, then the<br />
iterates x (k) and ˜x (k) are related by Qx (k) = ˜x (k) .<br />
Observation: linear convergence (→ Def. 3.1.4), see also Rem. 3.1.3<br />
rate of convergence increases (↔ speed of convergence decreases) with<br />
spread of spectrum of A<br />
✬<br />
Theorem 4.1.3 (Convergence of gradient method/steepest descent).<br />
The iterates of the gradient method of Alg. 4.1.4 satisfy<br />
∥<br />
∥x (k+1) − x ∗∥ ∥ ∥ ∥A ≤ L∥x (k) − x ∗∥ ∥ ∥A , L := cond 2(A) − 1<br />
cond 2 (A) + 1 ,<br />
that is, the iteration converges at least linearly (w.r.t. energy norm → Def. 4.1.1).<br />
✫<br />
✎ notation: cond 2 (A) ˆ= condition number of A induced by 2-norm<br />
Remark 4.1.9 (2-norm from eigenvalues).<br />
A = A T ⇒ ‖A‖ 2 = max(|σ(A)|) ,<br />
∥<br />
∥A −1∥ ∥ ∥2 = min(|σ(A)|) −1<br />
, if A regular.<br />
(4.1.6)<br />
✩<br />
✪<br />
Impact of distribution of diagonal entries (↔ eigenvalues) of (diagonal matrix) A<br />
(b = x ∗ = 0, x0 = cos((1:n)’);)<br />
A = A T ⇒ cond 2 (A) = λ max(A)<br />
λ min (A) , where λ max (A) := max(|σ(A)|) ,<br />
λ min (A) := min(|σ(A)|) .<br />
(4.1.7)<br />
Test matrix #1: A=diag(d); d = (1:100);<br />
Test matrix #2: A=diag(d); d = [1+(0:97)/97 , 50 , 100];<br />
Test matrix #3: A=diag(d); d = [1+(0:49)*0.05, 100-(0:49)*0.05];<br />
Test matrix #4: eigenvalues exponentially dense at 1<br />
Ôº¿ º½<br />
✎ other notation κ(A) := λ max(A)<br />
λ min (A)<br />
ˆ= spectral condition number of A<br />
(for general A: λ max (A)/λ min (A) largest/smallest eigenvalue in modulus)<br />
Ôº¿ º½













