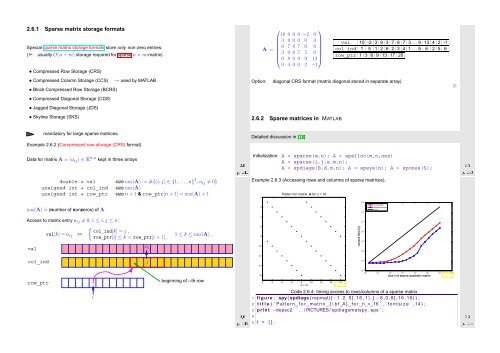
2.6.1 Sparse matrix storage formats Special sparse matrix storage formats store only non-zero entries: (➣ usually O(n + m) storage required for sparse n × m-matrix) • Compressed Row Storage (CRS) • Compressed Column Storage (CCS) • Block Compressed Row Storage (BCRS) • Compressed Diagonal Storage (CDS) • Jagged Diagonal Storage (JDS) • Skyline Storage (SKS) → used by MATLAB Option: ⎛ ⎞ 10 0 0 0 −2 0 3 9 0 0 0 3 A = 0 7 8 7 0 0 ⎜ 3 0 8 7 5 0 ⎟ ⎝ 0 8 0 9 9 13⎠ 0 4 0 0 2 −1 val 10 -2 3 9 3 7 8 7 3 . . . 9 13 4 2 -1 col_ind 1 5 1 2 6 2 3 4 1 . . . 5 6 2 5 6 row_ptr 1 3 6 9 13 17 20 diagonal CRS format (matrix diagonal stored in separate array) 2.6.2 Sparse matrices in MATLAB ✸ mandatory for large sparse matrices. Detailed discussion in [17] Example 2.6.2 (Compressed row-storage (CRS) format). Data for matrix A = (a ij ) ∈ K n,n kept in three arrays Ôº½½ ¾º Initialization: A = sparse(m,n); A = spalloc(m,n,nnz) A = sparse(i,j,s,m,n); A = spdiags(B,d,m,n); A = speye(n); A = spones(S); Ôº½¿ ¾º double * val size nnz(A) := #{(i,j) ∈ {1, ...,n} 2 , a ij ≠ 0} unsigned int * col_ind size nnz(A) unsigned int * row_ptr size n + 1 & row_ptr[n + 1] = nnz(A) + 1 Example 2.6.3 (Accessing rows and columns of sparse matrices). 0 Pattern for matrix A for n = 16 nnz(A) ˆ= (number of nonzeros) of A 2 10 0 row access column access O(n) Access to matrix entry a ij ≠ 0, 1 ≤ i,j ≤ n: 4 10 −1 val val[k] = a ij ⇔ { col_ind[k] = j , row_ptr[i] ≤ k < row_ptr[i + 1] , a ij 1 ≤ k ≤ nnz(A) . 6 8 10 access time [s] 10 −2 10 −3 10 −4 col_ind j 12 14 10 −5 row_ptr beginning of i-th row 16 0 2 4 6 8 nz = 32 10 12 14 16 Fig. 11 10 1 size n of sparse quadratic matrix 10 −6 10 0 10 1 10 2 10 3 10 4 10 5 10 6 10 7 Fig. 12 i Ôº½¾ ¾º Code 2.6.4: timing access to rows/columns of a sparse matrix 1 figure ; spy ( spdiags ( repmat([−1 2 5 ] ,16 ,1) ,[ −8 ,0 ,8] ,16 ,16) ) ; 2 t i t l e ( ’ Pattern f o r m a trix { \ b f A} f o r n = 16 ’ , ’ f o n t s i z e ’ ,14) ; 3 p r i n t −depsc2 ’ . . / PICTURES/ spdiagsmatspy . eps ’ ; Ôº½ ¾º 5 t = [ ] ; 4
6 for i =1:20 7 n = 2^ i ; m = n / 2 ; 8 A = spdiags ( repmat([−1 2 5 ] , n , 1 ) ,[−n / 2 , 0 , n / 2 ] , n , n ) ; 9 10 t1 = i n f ; for j =1:5 , t i c ; v = A(m, : ) + j ; t1 = min ( t1 , toc ) ; end 11 t2 = i n f ; for j =1:5 , t i c ; v = A ( : ,m) + j ; t2 = min ( t2 , toc ) ; end 12 t = [ t ; size (A, 1 ) , nnz (A) , t1 , t2 ] ; 13 end 14 15 figure ; 16 loglog ( t ( : , 1 ) , t ( : , 3 ) , ’ r+− ’ , t ( : , 1 ) , t ( : , 4 ) , ’ b∗− ’ , . . . 17 t ( : , 1 ) , t ( 1 , 3 )∗ t ( : , 1 ) / t ( 1 , 1 ) , ’ k−’ ) ; 18 xlabel ( ’ { \ b f size n o f sparse q u a d r a t i c m a trix } ’ , ’ f o n t s i z e ’ ,14) ; 19 ylabel ( ’ { \ b f access time [ s ] } ’ , ’ f o n t s i z e ’ ,14) ; 20 legend ( ’ row access ’ , ’ column access ’ , ’O( n ) ’ , ’ l o c a t i o n ’ , ’ northwest ’ ) ; 21 22 p r i n t −depsc2 ’ . . / PICTURES/ sparseaccess . eps ’ ; Ôº½ ¾º Ôº½ ¾º [ Acknowledgment: this observation was made by Andreas Növer, 8.10.2009] 12 ylabel ( ’ { \ b f time [ s ] } ’ , ’ f o n t s i z e ’ ,14) ; MATLAB uses compressed column storage (CCS), which entails O(n) searches for index j in the index array when accessing all elements of a matrix row. Conversely, access to a column does not involve any search operations. 3 for j =1:n 4 i f ( abs ( i−j ) == 1) , k=k +1; dat ( k , : ) = [ i , j , 1 . 0 ] ; 5 end ; 6 i f ( abs ( i−j ) == round ( n / 3 ) ) 7 k=k +1; dat ( k , : ) = [ i , j , − 1 .0]; 8 end ; 9 end ; end ; 10 A3 = sparse ( dat ( 1 : k , 1 ) , dat ( 1 : k , 2 ) , dat ( 1 : k , 3 ) ,n , n ) ; Code 2.6.9: Initialization of sparse matrices: driver script 1 % Driver routine for initialization of sparse matrices 2 K = 3 ; r = [ ] ; 3 for n = 2 . ^ ( 8 : 1 4 ) 4 t1= 1000; for k =1:K, f p r i n t f ( ’ sparse1 , %d , %d \ n ’ ,n , k ) ; t i c ; sparse1 ; t1 = min ( t1 , toc ) ; end 5 t2= 1000; for k =1:K, f p r i n t f ( ’ sparse2 , %d , %d \ n ’ ,n , k ) ; t i c ; sparse2 ; t2 = min ( t2 , toc ) ; end 6 t3= 1000; for k =1:K, f p r i n t f ( ’ sparse3 , %d , %d \ n ’ ,n , k ) ; t i c ; sparse3 ; t3 = min ( t3 , toc ) ; end 7 r = [ r ; n , t1 , t2 , t3 ] ; 8 end 9 10 loglog ( r ( : , 1 ) , r ( : , 2 ) , ’ r ∗ ’ , r ( : , 1 ) , r ( : , 3 ) , ’m+ ’ , r ( : , 1 ) , r ( : , 4 ) , ’ b^ ’ ) ; 11 xlabel ( ’ { \ b f m a trix size n } ’ , ’ f o n t s i z e ’ ,14) ; Example 2.6.5 (Efficient Initialization of sparse matrices in MATLAB). ✸ 13 legend ( ’ I n i t i a l i z a t i o n I ’ , ’ I n i t i a l i z a t i o n I I ’ , ’ I n i t i a l i z a t i o n I I I ’ , . . . 14 ’ l o c a t i o n ’ , ’ northwest ’ ) ; 15 p r i n t −depsc2 ’ . . / PICTURES/ s p a r s e i n i t . eps ’ ; Code 2.6.6: Initialization of sparse matrices: version I 1 A1 = sparse ( n , n ) ; 2 for i =1:n 3 for j =1:n 4 i f ( abs ( i−j ) == 1) , A1 ( i , j ) = A1 ( i , j ) + 1 ; end ; 5 i f ( abs ( i−j ) == round ( n / 3 ) ) , A1 ( i , j ) = A1 ( i , j ) −1; end ; 6 end ; end 1 dat = [ ] ; 2 for i =1:n 3 for j =1:n Code 2.6.7: Initialization of sparse matrices: version II 4 i f ( abs ( i−j ) == 1) , dat = [ dat ; i , j , 1 . 0 ] ; end ; 5 i f ( abs ( i−j ) == round ( n / 3 ) ) , dat = [ dat ; i , j , − 1 .0]; 6 end ; end ; end ; 7 A2 = sparse ( dat ( : , 1 ) , dat ( : , 2 ) , dat ( : , 3 ) ,n , n ) ; Ôº½ ¾º Code 2.6.8: Initialization of sparse matrices: version III 1 dat = zeros (6∗n , 3 ) ; k = 0 ; 2 for i =1:n Timings: Linux lions 2.6.16.27-0.9-smp #1 SMP Tue Feb 13 09:35:18 UTC 2007 i686 i686 i386 GNU/Linux CPU: Genuine Intel(R) CPU T2500 2.00GHz MATLAB 7.4.0.336 (R2007a) ✄ time [s] matrix size n Initialization I Initialization II Initialization III 10 2 10 1 10 0 10 −1 10 −2 10 2 10 3 10 4 10 5 Fig. 13 10 3 ☛ It is grossly inefficient to initialize a matrix in CCS format (→ Ex. 2.6.2) by setting individual entries one after another, because this usually entails moving large chunks of memory to create space for new non-zero entries. Instead calls like Ôº½ ¾º
- Page 1 and 2: 2 Direct Methods for Linear Systems
- Page 3 and 4: III Integration of Ordinary Differe
- Page 5 and 6: Extra questions for course evaluati
- Page 7 and 8: 1.1.2 Matrices Matrices = two-dimen
- Page 9 and 10: Remark 1.2.1 (Row-wise & column-wis
- Page 11 and 12: 1.3 Complexity/computational effort
- Page 13 and 14: Syntax of BLAS calls: The functions
- Page 15 and 16: 4 { 5 a ssert ( this−>n==B. n &&
- Page 17 and 18: 34 long r t 0 ; 35 bool bStarted ;
- Page 19 and 20: Obviously, left multiplication with
- Page 21 and 22: ❶: elimination step, ❷: backsub
- Page 23 and 24: A direct way to LU-decomposition:
- Page 25 and 26: Solution of LŨx = b: x ( ) 2ǫ = 1
- Page 27 and 28: numerically equivalent ˆ= same res
- Page 29 and 30: Code 2.4.8: Finding outeps in MATLA
- Page 31 and 32: Terminology: Def. 2.5.5 introduces
- Page 33 and 34: Example 2.5.5 (Instability of multi
- Page 35: Note: sensitivity gauge depends on
- Page 39 and 40: 0 20 40 60 80 100 120 140 160 180 2
- Page 41 and 42: Use sparse matrix format: 10 1 10 2
- Page 43 and 44: Envelope-aware LU-factorization: 0
- Page 45 and 46: 0 20 40 60 80 100 0 20 0 20 0 20 De
- Page 47 and 48: Evident: symmetry of à − bbT a 1
- Page 49 and 50: 9 ylabel ( ’ { \ b f c o n d i t
- Page 51 and 52: Mapping a ∈ K n to a multiple of
- Page 53 and 54: Then store G ij (a,b) as triple (i,
- Page 55 and 56: Recall: e i ˆ= i-th unit vector Ch
- Page 57 and 58: Computation of Choleskyfactorizatio
- Page 59 and 60: 1 ∃ (partial) cyclic row permutat
- Page 61 and 62: Definition 3.1.3 (Local and global
- Page 63 and 64: Example 3.1.6 (quadratic convergenc
- Page 65 and 66: k |x (k) − π| L 1−L |x (k) −
- Page 67 and 68: (x (k) ) k∈N0 Cauchy sequence ➤
- Page 69 and 70: Termination criterion for contracti
- Page 71 and 72: Given x (k) ∈ I, next iterate :=
- Page 73 and 74: secant method ( MATLAB implementati
- Page 75 and 76: Assuming p = 1: p > 1: ∥ C ∥e (
- Page 77 and 78: This is a simple computation: DG(x)
- Page 79 and 80: k x (k) ǫ k := ‖x ∗ − x (k)
- Page 81 and 82: Code 3.4.14: Damped Newton method (
- Page 83 and 84: MATLAB-CODE: Broyden method (3.4.11
- Page 85 and 86: Algorithm 4.1.3 (Steepest descent).
- Page 87 and 88:
Example 4.1.8 (Convergence of gradi
- Page 89 and 90:
4.2.1 Krylov spaces Definition 4.2.
- Page 91 and 92:
Remark 4.2.3 (A posteriori terminat
- Page 93 and 94:
10 figure ; view ([ −45 ,28]) ; m
- Page 95 and 96:
Idea: Solve Ax = b approximately in
- Page 97 and 98:
eplaced with κ(A) ! 4.4.2 Iteratio
- Page 99 and 100:
For circuit of Fig. 55 at angular f
- Page 101 and 102:
(Linear) generalized eigenvalue pro
- Page 103 and 104:
10 0 10 1 matrix size n d = eig(A)
- Page 105 and 106:
0 50 100 150 200 250 300 350 400 45
- Page 107 and 108:
1 2 3 k ρ (k) EV ρ (k) EW ρ (k)
- Page 109 and 110:
✬ ✩ ✬ ✩ Lemma 5.3.4 (Ncut a
- Page 111 and 112:
In other words, roundoff errors may
- Page 113 and 114:
Theory: linear convergence of (5.3.
- Page 115 and 116:
error in eigenvalue 10 0 10 −2 10
- Page 117 and 118:
✬ Residuals r 0 ,...,r m−1 gene
- Page 119 and 120:
Algebraic view of the Arnoldi proce
- Page 121 and 122:
5.5 Singular Value Decomposition Re
- Page 123 and 124:
Illustration: columns = ONB of Im(A
- Page 125 and 126:
✬ Theorem 5.5.7 (best low rank ap
- Page 127 and 128:
Reassuring: Remark 6.0.4 (Pseudoinv
- Page 129 and 130:
Consider the linear least squares p
- Page 131 and 132:
Goal: Euclidean distance of y ∈ R
- Page 133 and 134:
6.5 Non-linear Least Squares If (6.
- Page 135 and 136:
0 2 4 6 8 10 12 14 16 value of ∥
- Page 137 and 138:
Definition 7.1.1 (Discrete convolut
- Page 139 and 140:
Expand a 0 ,...,a n−1 and b 0 , .
- Page 141 and 142:
(7.2.2) is a simple consequence of
- Page 143 and 144:
Dominant coefficients of a signal a
- Page 145 and 146:
11 c = f f t ( y ) ; 12 13 figure (
- Page 147 and 148:
Two-dimensional trigonometric basis
- Page 149 and 150:
8 end 9 t1 = min ( t1 , toc ) ; 10
- Page 151 and 152:
Step II: for k =: rq + s, 0 ≤ r <
- Page 153 and 154:
MATLAB-CODE Sine transform function
- Page 155 and 156:
△ Example 7.5.2 (Linear regressio
- Page 157 and 158:
[23, Ch. IX] presents the topic fro
- Page 159 and 160:
Code 8.1.3: Horner scheme, polynomi
- Page 161 and 162:
1.2 equality in (8.2.10) for y := (
- Page 163 and 164:
ecursive definition: p i (t) ≡ y
- Page 165 and 166:
a 1 = y 1 − a 0 t 1 − t 0 = y 1
- Page 167 and 168:
Observations: Strong oscillations o
- Page 169 and 170:
−1 −0.8 −0.6 −0.4 −0.2 0
- Page 171 and 172:
8.5.3 Chebychev interpolation: comp
- Page 173 and 174:
9.1 Shape preserving interpolation
- Page 175 and 176:
9.2.2 Piecewise polynomial interpol
- Page 177 and 178:
Interpolation of the function: f(x)
- Page 179 and 180:
2 % Plot convergence of approximati
- Page 181 and 182:
9.4 Splines Definition 9.4.1 (Splin
- Page 183 and 184:
➤ Linear system of equations with
- Page 185 and 186:
y i+1 t i−1 t i t i+1 y i−1 y i
- Page 187 and 188:
35 h= d i f f ( t ) ; 36 d e l t a
- Page 189 and 190:
1 0.9 Function f 1 0.9 Function f
- Page 191 and 192:
f 10 Numerical Quadrature Numerical
- Page 193 and 194:
f • n = 1: Trapezoidal rule • n
- Page 195 and 196:
For fixed local n-point quadrature
- Page 197 and 198:
Equidistant trapezoidal rule (order
- Page 199 and 200:
Heuristics: A quadrature formula ha
- Page 201 and 202:
20 Zeros of Legendre polynomials in
- Page 203 and 204:
|quadrature error| 10 0 Numerical q
- Page 205 and 206:
f f • line 9: estimate for global
- Page 207 and 208:
Model: autonomous Lotka-Volterra OD
- Page 209 and 210:
Example 11.1.6 (Transient circuit s
- Page 211 and 212:
y y 1 y(t) y 0 t t 0 t 1 Fig. 133 e
- Page 213 and 214:
for discrete evolution defined on I
- Page 215 and 216:
⇒ if y ∈ C 2 ([0, T]), then y(t
- Page 217 and 218:
The implementation of an s-stage ex
- Page 219 and 220:
Example 11.5.2 (Blow-up). ✸ toler
- Page 221 and 222:
However, it would be foolish not to
- Page 223 and 224:
0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8
- Page 225 and 226:
4 3 2 abstol = 0.000010, reltol = 0
- Page 227 and 228:
✸ ✸ Motivated by the considerat
- Page 229 and 230:
0 1 2 3 4 5 6 u(t),v(t) 0.01 0.008
- Page 231 and 232:
MATLAB-CODE : Explicit integration
- Page 233 and 234:
Shorthand notation for Runge-Kutta
- Page 235 and 236:
13 Structure Preservation 13.1 Diss
- Page 237 and 238:
[18] G. GOLUB AND C. VAN LOAN, Matr
- Page 239 and 240:
linear in Gauss-Newton method, 538
- Page 241 and 242:
Chebychev nodes, 678 double, 634 fo
- Page 243 and 244:
x∗ n y ˆ= discrete periodic conv
- Page 245 and 246:
Gaussian elimination with pivoting