

Numerical Methods Contents - SAM
Numerical Methods Contents - SAM
Numerical Methods Contents - SAM

You also want an ePaper? Increase the reach of your titles
YUMPU automatically turns print PDFs into web optimized ePapers that Google loves.
Initial guess x (0) ∈ R n , k = 0<br />
r 0 := b − Ax (0)<br />
repeat<br />
t ∗ := rT k r k<br />
r T k Ar k<br />
x (k+1) := x (k) + t ∗ r k<br />
r k+1 := r k − t ∗ Ar k<br />
k := k + 1<br />
∥<br />
until ∥x (k) − x (k−1)∥ ∥<br />
∥ ∥ ∥∥x ≤τ (k) ∥<br />
Code 4.1.6: gradient method for Ax = b, A s.p.d.<br />
1 function x = g r a d i t (A, b , x , t o l , maxit )<br />
2 r = b−A∗x ;<br />
3 for k =1: maxit<br />
4 p = A∗ r ;<br />
5 t s = ( r ’∗ r ) / ( r ’∗ p ) ;<br />
6 x = x + t s ∗ r ;<br />
7 i f ( abs ( t s ) ∗norm( r ) < t o l ∗norm( x ) )<br />
8 return ; end<br />
9 r = r − t s ∗p ;<br />
10 end<br />
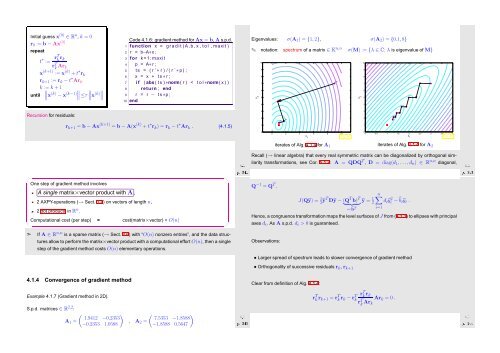
Eigenvalues: σ(A 1 ) = {1, 2}, σ(A 2 ) = {0.1, 8}<br />
✎ notation: spectrum of a matrix ∈ K n,n σ(M) := {λ ∈ C: λ is eigenvalue of M}<br />
x 2<br />
10<br />
9<br />
8<br />
x (0)<br />
7<br />
6<br />
5<br />
4<br />
x 2<br />
10<br />
9<br />
8<br />
7<br />
6<br />
5<br />
4<br />
x (1) x (2)<br />
Recursion for residuals:<br />
r k+1 = b − Ax (k+1) = b − A(x (k) + t ∗ r k ) = r k − t ∗ Ar k . (4.1.5)<br />
3<br />
2<br />
1<br />
3<br />
2<br />
1<br />
x (3) x 1<br />
Ôº¿½ º½<br />
0<br />
0 2 4 6 8 10<br />
0<br />
0 0.5 1 1.5 2 2.5 3 3.5 4<br />
Fig. 44<br />
x 1<br />
iterates of Alg. 4.1.4 for A 1 iterates of Alg. 4.1.4 for A 2<br />
Recall (→ linear algebra) that every real symmetric matrix can be diagonalized by orthogonal similarity<br />
transformations, see Cor. 5.1.7: A = QDQ T , D = diag(d 1 ,...,d n ) ∈ R n,n diagonal,<br />
Fig. 45<br />
Ôº¿¿ º½<br />
✬<br />
One step of gradient method involves<br />
A single matrix×vector product with A ,<br />
2 AXPY-operations (→ Sect. 1.4) on vectors of length n,<br />
2 dot products in R n .<br />
Computational cost (per step) = cost(matrix×vector) + O(n)<br />
✫<br />
✩<br />
✪<br />
Q −1 = Q T .<br />
J(Qŷ) = 1 2ŷT Dŷ − (Q T b) T<br />
} {{ }<br />
=:̂b T ŷ = 1 2<br />
n∑<br />
d i ŷi 2 −̂b i ŷ i .<br />
Hence, a congruence transformation maps the level surfaces of J from (4.1.1) to ellipses with principal<br />
axes d i . As A s.p.d. d i > 0 is guaranteed.<br />
i=1<br />
➣<br />
If A ∈ R n,n is a sparse matrix (→ Sect. 2.6) with “O(n) nonzero entries”, and the data structures<br />
allow to perform the matrix×vector product with a computational effort O(n), then a single<br />
step of the gradient method costs O(n) elementary operations.<br />
Observations:<br />
• Larger spread of spectrum leads to slower convergence of gradient method<br />
• Orthogonality of successive residuals r k , r k+1<br />
4.1.4 Convergence of gradient method<br />
Clear from definition of Alg. 4.1.4:<br />
Example 4.1.7 (Gradient method in 2D).<br />
S.p.d. matrices ∈ R 2,2 :<br />
A 1 =<br />
( )<br />
1.9412 −0.2353<br />
−0.2353 1.0588<br />
, A 2 =<br />
Ôº¿¾ º½<br />
( )<br />
7.5353 −1.8588<br />
−1.8588 0.5647<br />
r T k r k+1 = r T k r k − r T r T k r k<br />
k<br />
r T k Ar Ar k = 0 .<br />
k<br />
Ôº¿ º½













